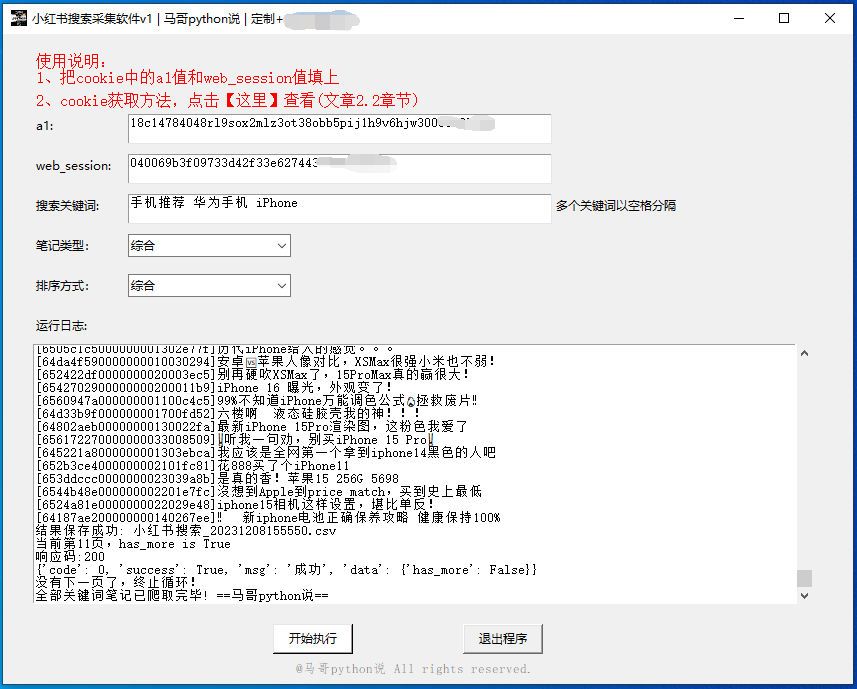
我用python开发了一个爬虫采集软件,可自动按关键词抓取小红书笔记数据。 为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用! 软件界面截图: 爬取结果截图: 1.2 演示视频 软件运行演示: 【软件演示】爬小红书关键词搜索软件 1.3 软件亮点说明 几点重要说明:


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3615
3615





