






注意:代码可以下载大部分动漫,但是樱花动漫也有些不是m3u8格式的视频,故无法下载。
我将代码简单打包了一下,有需要的可以自行下载。
首先网址 http://www.iyinghua.io/?ivk_sa=1026860c
然后,开干!
爬虫目标:根据动漫名字爬取相应的动漫。
一些问题:
1.动漫名字不全或有错怎么办?
2.如何由名字转到相应的网页?url很显然不是根据名字转接的
3.仔细观察动漫页面的网络请求,发现是m3u8格式的视频。那么问题又来了,多找几个动漫观察一下就会发现,这路径含有m3u8的url有些参数还不一样。比如:
https://vip.ffzy-play6.com/20221212/17184_84972b3a/2000k/hls/mixed.m3u8
和 https://s7.fsvod1.com/20220703/v8y3R2dU/1500kb/hls/index.m3u8
反正我是找不出规律。
4.然后就是有些m3u8格式的视频是有加密措施的,我看了一下大部分是AES-128加密,有没有其它加密方式我就不知道了(大不了遇到了再学嘛)
5.预览一下m3u8里面的内容,会发现有很多ts分流。将这些分流全部获取后,怎么将它们有序地拼成一整个视频?
以上大概就是我遇到的一些问题。接下来一个一个解决!
对于问题1,我打算先将所有的动漫名称都给爬一下顺带将他们相对应的网址路径也给爬了。然后保存到world文档里。这样可以利用world文档里的查找功能方便快捷地找到相对应地动漫名字和其路径。名字错了难不成路径还能错嘛。当然也可以直接到官网搜索动漫,获取相应的路径
对于问题2,由问题1,有了相对应的路径,再结合根目录就可以拼出一个完整的url,例如
Engage Kiss/契约之吻:/show/5608.html 用正则表达式匹配出冒号后面的路径,再将它与樱花动漫-专注动漫的门户网站 拼接在一起就实现了根据动漫名称转到相应的网页。
def fix_url(args): # 转到具体的动漫选集页面.用来显示当前一共有多少集
url = f'http://www.iyinghua.io{args}'
return scrape_page(url) # 此html用来找出总集数
def display_id(args): # 返回动漫的id
args_id = re.search('/show/(.*?).html', args).group(1)
return args_id
def select_episode(args_id, episode): # 参数为动漫的id和挑选的集数
url = f'http://www.iyinghua.io/v/{args_id}' + '-' + f'{episode}.html'
return url
def find_all_episodes(text):
if text is not None:
result = re.findall('<a href="/v.*?".*?>(.*?)</a>', text, re.S)
if result is not None:
return result[-1] # 输出列表的最后一个元素
else:
logging.error('总集数列表为空')
else:
logging.error('总集数html为空')
对于问题3,由开头所说,用playwright(当然其它的也可以做到),可以实时监听其网络请求。
def on_response(response): # 事件监听回调
if '.m3u8' in response.url and 'mp4' not in response.url and response.status == 200:
m3u8s.append(response.url)
if '.key' in response.url and response.status == 200: # 判断m3u8是否加密,一般是AES-128加密方式
keys.append(response.url)
with sync_playwright() as p: # 事件监听
browser = p.firefox.launch(headless=True, args=['--User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'], executable_path=r'D:\爬虫脚本\sakura\firefox\firefox.exe')
page = browser.new_page()
page.on('response', on_response)
page.goto(the_url)
# page.wait_for_load_state('networkidle')
browser.close()对于问题4,用python里的第三方库pycryptodome可以实现对AES-128加密方式的解密。
def aes_decode(encrypted_data, key, m3u8): # 参数为ts分流视频的二进制,和秘钥,还有m3u8的文本
"""先判断是否是AES-128加密方式,KEY:METHOD=AES-128 如果是则进行解密。如果不是则捕捉异常,并输出给控制台。"""
try:
encryption = re.search('KEY:.*?=(.*?),', m3u8, re.S).group(1).strip() if re.search('KEY:.*?=(.*?),', m3u8, re.S) else None
if encryption is not None:
if encryption == 'AES-128':
"""AES-128解密"""
cipher = AES.new(key, AES.MODE_CBC, key)
data = cipher.decrypt(encrypted_data)
return data # 这里返回的data是二进制,直接写入视频格式文件即可解密成功
else:
logging.info('不是AES-128加密,请检查加密方式')
else:
return False
except ValueError:
logging.error(ValueError)
print(encrypted_data)对于问题5,可以用ffmpeg,指令:ffmpeg -f concat -safe 0 -i filelist.txt -c copy output.mp4
def ffmpeg_combine(video_path, txt_path, name, num): # 这里是将txt里的视频路径依次合并,video_path需要用户输入
"""先查找txt_path是否存在,然后再依次合并, 并检查合并好的文件是否存在"""
if os.path.exists(txt_path):
name = name.replace('/', '')
order = f'ffmpeg -f concat -safe 0 -i {txt_path} -c copy {video_path}\\{name}第{num}集.mp4 -loglevel quiet'
subprocess.run(order)
if os.path.exists(f'{video_path}\\{name}第{num}集.mp4'):
logging.info('下载成功啦!')
else:
print('下载失败了,原因是合并时出现了问题')
else:
logging.error(f'{txt_path}不存在,请检查是否创建')总代码:
import re
import requests # 同步请求
from lxml import etree
import logging
import time
import tqdm # 进度条(迭代)
from playwright.sync_api import sync_playwright # 同步
import os
import subprocess
from Crypto.Cipher import AES
import keyboard
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
m3u8s = []
keys = []
def scrape_page(url): # 解析URL,返回html
if url is not None:
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
logging.error('%s', response.status_code)
except requests.RequestException:
logging.error('其他错误!', exc_info=True)
else:
logging.error('url为空!')
return None
def fix_url(args): # 转到具体的动漫选集页面.用来显示当前一共有多少集
url = f'http://www.iyinghua.io{args}'
return scrape_page(url) # 此html用来找出总集数
def display_id(args): # 返回动漫的id
args_id = re.search('/show/(.*?).html', args).group(1)
return args_id
def select_episode(args_id, episode): # 参数为动漫的id和挑选的集数
url = f'http://www.iyinghua.io/v/{args_id}' + '-' + f'{episode}.html'
return url
def find_all_episodes(text):
if text is not None:
result = re.findall('<a href="/v.*?".*?>(.*?)</a>', text, re.S)
if result is not None:
return result[-1] # 输出列表的最后一个元素
else:
logging.error('总集数列表为空')
else:
logging.error('总集数html为空')
def on_response(response): # 事件监听回调
if '.m3u8' in response.url and 'mp4' not in response.url and response.status == 200:
m3u8s.append(response.url)
if '.key' in response.url and response.status == 200: # 判断m3u8是否加密,一般是AES-128加密方式
keys.append(response.url)
def read_ts(json): # 如果判断没有加密,那么直接提取出ts分流(只是一半)
mid_ts_urls = re.findall('#EXTINF.*?,(.*?).ts', json, re.S)
if mid_ts_urls is not None:
for ts_urls in mid_ts_urls:
ts_urls = ts_urls.replace('\n', '')
full_ts_urls.append(f'{ts_urls}.ts')
if '/hls/' in full_ts_urls[0]: # 判断ts分流的url是不是统一的(有些带日期,有些不带)
return True
else:
return False
def makefile(name, base_url): # 创建相应的动漫文件夹
try:
name = name.replace('/', '')
path = f'{base_url}\\{name}'
if not os.path.exists(path):
os.makedirs(path)
return path
else:
return path
except PermissionError:
logging.error(PermissionError)
except OSError:
logging.error(OSError)
def make_txt(name, path): # 检测并创建合并txt
name = name.replace('/', '')
if os.path.exists(path):
txt_path = f'{path}\\{name}.txt'
if os.path.exists(txt_path):
logging.info(f'{name}.txt已经存在')
return txt_path
else:
with open(txt_path, 'w') as f:
f.write('')
if os.path.exists(txt_path):
return txt_path
else:
logging.error('txt创建失败')
else:
return False
def write_data(num, content, path): # 这里的path是动漫文件夹的路径, num可用循环
with open(f'{path}\\{num}.mp4', 'wb') as file:
file.write(content)
def translate_bytes(url): # 参数为ts分流的url
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.content
else:
return False
def aes_decode(encrypted_data, key, m3u8): # 参数为ts分流视频的二进制,和秘钥,还有m3u8的文本
"""先判断是否是AES-128加密方式,KEY:METHOD=AES-128 如果是则进行解密。如果不是则捕捉异常,并输出给控制台。"""
try:
encryption = re.search('KEY:.*?=(.*?),', m3u8, re.S).group(1).strip() if re.search('KEY:.*?=(.*?),', m3u8, re.S) else None
if encryption is not None:
if encryption == 'AES-128':
"""AES-128解密"""
cipher = AES.new(key, AES.MODE_CBC, key)
data = cipher.decrypt(encrypted_data)
return data # 这里返回的data是二进制,直接写入视频格式文件即可解密成功
else:
logging.info('不是AES-128加密,请检查加密方式')
else:
return False
except ValueError:
logging.error(ValueError)
print(encrypted_data)
def write_txt(txt_path, path, num): # 这里的path是文件夹路径, num与上面用法一样
if os.path.exists(txt_path):
with open(txt_path, 'a+', encoding='utf-8') as f:
f.write(f"file '{path}\\{num}.mp4'" + '\n')
def ffmpeg_combine(video_path, txt_path, name, num): # 这里是将txt里的视频路径依次合并,video_path需要用户输入
"""先查找txt_path是否存在,然后再依次合并, 并检查合并好的文件是否存在"""
if os.path.exists(txt_path):
name = name.replace('/', '')
order = f'ffmpeg -f concat -safe 0 -i {txt_path} -c copy {video_path}\\{name}第{num}集.mp4 -loglevel quiet'
subprocess.run(order)
if os.path.exists(f'{video_path}\\{name}第{num}集.mp4'):
logging.info('下载成功啦!')
else:
print('下载失败了,原因是合并时出现了问题')
else:
logging.error(f'{txt_path}不存在,请检查是否创建')
def handle_input(input_content): # 处理用户输入的数据,将其拆分成name,和url片段
name = re.search('(.*?):', input_content).group(1).strip() if re.search('(.*?):', input_content) else None
name = name.replace(' ', '')
args = re.search('.*?:(.*?).html', input_content).group(1).strip() if re.search('.*?:(.*?).html', input_content) else None
args = args + '.html'
return name, args
def main():
global full_ts_urls
full_ts_urls = []
input_content = input('请输入你要下载的动漫:')
base_path = input('请输入保存路径:')
handle_result = handle_input(input_content)
name = handle_result[0]
args = handle_result[1]
args_id = display_id(args)
episode_html = fix_url(args)
all_episode = find_all_episodes(episode_html)
if all_episode == '全集': # 纠正输出内容
all_episode = '1集'
if '第' in all_episode:
all_episode = re.sub('第', '', all_episode)
print(f'{name}一共有{all_episode}')
episode = input('你要下载第几集?:')
the_url = select_episode(args_id, episode)
logging.info('正在监听网络请求中...(可能稍慢~请耐心等待, 如果失败请检查网络并重新启动)')
with sync_playwright() as p: # 事件监听
browser = p.firefox.launch(headless=True, args=['--User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'])
page = browser.new_page()
page.on('response', on_response)
page.goto(the_url)
# page.wait_for_load_state('networkidle')
browser.close()
if m3u8s:
print(m3u8s[-1])
if m3u8s:
m3u8 = m3u8s[-1]
m3u8_text = scrape_page(m3u8)
file_path = makefile(name, base_path) # 创建文件夹
txt_path = make_txt(name, file_path) # 创建txt文档
front_url = re.search('(.*?)/hls/', m3u8).group(1).strip()
front_url = front_url + '/hls/'
true_false = read_ts(m3u8_text)
if true_false:
for i in range(len(full_ts_urls)):
full_ts_urls[i] = re.sub('.*?/hls/','', full_ts_urls[i])
full_ts_urls[i] = front_url + full_ts_urls[i]
else:
full_ts_urls = [f'{front_url}{url}' for url in full_ts_urls]
if keys:
key = keys[-1]
key = translate_bytes(key)
key_start = time.time()
for i in tqdm.trange(0, len(full_ts_urls)):
url = full_ts_urls[i]
# print(url)
content = translate_bytes(url)
if content is not False:
data = aes_decode(content, key, m3u8_text) # 解密(AES-128)
write_data(i, data, file_path) # 写入解密后的数据
write_txt(txt_path, file_path, i)
ffmpeg_combine(file_path, txt_path, name, episode)
try:
for i in range(len(full_ts_urls)):
os.remove(f'{file_path}\\{i}.mp4')
os.remove(txt_path)
except FileNotFoundError:
logging.error('FileNotFoundError')
key_end = time.time()
total_time = (key_end - key_start)/60
print('用时:' + f'{total_time}min')
else: # 没有加密
no_key_start = time.time()
for i in tqdm.trange(len(full_ts_urls)):
url = full_ts_urls[i]
content = translate_bytes(url)
write_data(i, content, file_path)
write_txt(txt_path, file_path, i)
ffmpeg_combine(file_path, txt_path, name, episode)
try:
for i in range(len(full_ts_urls)):
os.remove(f'{file_path}\\{i}.mp4')
os.remove(txt_path)
except FileNotFoundError:
logging.error('FileNotFoundError')
no_key_end = time.time()
total_time = (no_key_end - no_key_start)/60
print('用时:' + f'{total_time}min')
else:
print('动漫已经失效')
if __name__ == '__main__':
main()
print('按ESC结束进程~o( =∩ω∩= )m')
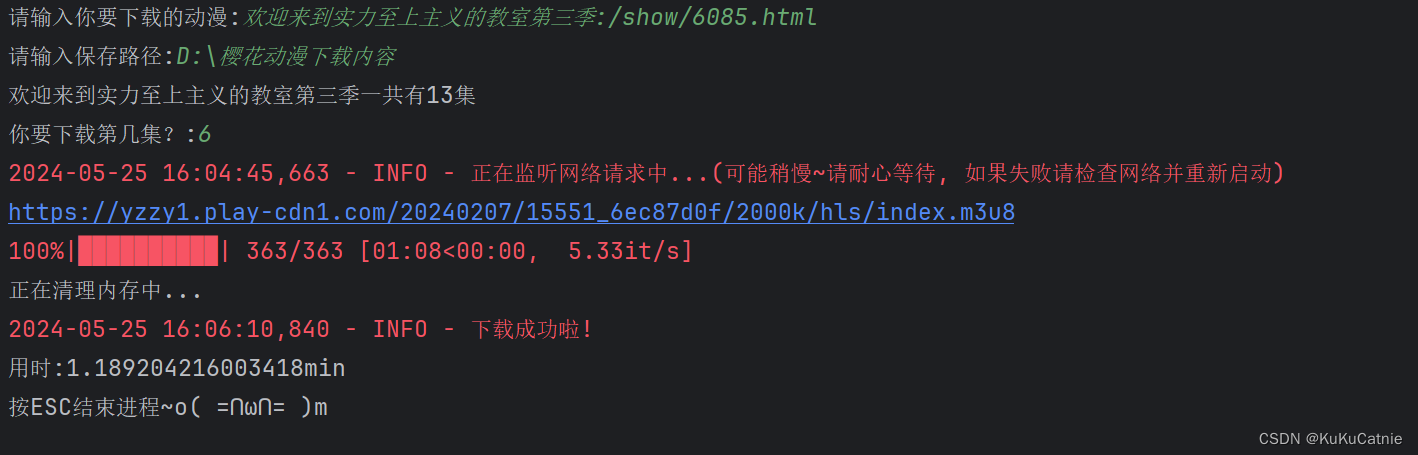
keyboard.wait('Esc')但是发现下载速度过于缓慢,一集最少也得8min。能不能加速代码呢?
我这里采用协程加速,测试了一下8min缩短到了1min,下一部电影只需要6min。
import re
import requests # 同步请求
from lxml import etree
import logging
import time
import tqdm # 进度条(迭代)
from playwright.sync_api import sync_playwright # 同步
from playwright.async_api import async_playwright # 异步
import asyncio
import aiohttp # 异步请求
import os
import subprocess
from Crypto.Cipher import AES
import keyboard
from tenacity import retry, stop_after_attempt # 错误重试
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
m3u8s = []
keys = []
limit = 5 # 限制信号量
semaphore = asyncio.Semaphore(limit) # 限制最高并发量为5
@retry(stop=stop_after_attempt(5))
def scrape_page(url): # 解析URL,返回html
if url is not None:
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
logging.error('%s', response.status_code)
except requests.RequestException:
logging.error('其他错误!', exc_info=True)
else:
logging.error('url为空!')
return None
def fix_url(args): # 转到具体的动漫选集页面.用来显示当前一共有多少集
url = f'http://www.iyinghua.io{args}'
return scrape_page(url) # 此html用来找出总集数
def display_id(args): # 返回动漫的id
args_id = re.search('/show/(.*?).html', args).group(1)
return args_id
def select_episode(args_id, episode): # 参数为动漫的id和挑选的集数
url = f'http://www.iyinghua.io/v/{args_id}' + '-' + f'{episode}.html'
return url
def find_all_episodes(text):
if text is not None:
result = re.findall('<a href="/v.*?".*?>(.*?)</a>', text, re.S)
if result is not None:
return result[-1] # 输出列表的最后一个元素
else:
logging.error('总集数列表为空')
else:
logging.error('总集数html为空')
def on_response(response): # 事件监听回调
if '.m3u8' in response.url and 'mp4' not in response.url and response.status == 200:
m3u8s.append(response.url)
if '.key' in response.url and response.status == 200: # 判断m3u8是否加密,一般是AES-128加密方式
keys.append(response.url)
def read_ts(json): # 如果判断没有加密,那么直接提取出ts分流(只是一半)
mid_ts_urls = re.findall('#EXTINF.*?,(.*?).ts', json, re.S)
if mid_ts_urls is not None:
for ts_urls in mid_ts_urls:
ts_urls = ts_urls.replace('\n', '')
full_ts_urls.append(f'{ts_urls}.ts')
if 'http' in full_ts_urls[0]:
return 'http'
if 'hls' in full_ts_urls[0]: # 判断ts分流的url是不是统一的(有些带日期,有些不带)
return 'hls'
else:
return None
def makefile(name, base_url): # 创建相应的动漫文件夹
try:
name = name.replace('/', '')
path = f'{base_url}\\{name}'
if not os.path.exists(path):
os.makedirs(path)
return path
else:
return path
except PermissionError:
logging.error(PermissionError)
except OSError:
logging.error(OSError)
def make_txt(name, path): # 检测并创建合并txt
name = name.replace('/', '')
if os.path.exists(path):
txt_path = f'{path}\\{name}.txt'
if os.path.exists(txt_path):
logging.info(f'{name}.txt已经存在')
return txt_path
else:
with open(txt_path, 'w') as f:
f.write('')
if os.path.exists(txt_path):
return txt_path
else:
logging.error('txt创建失败')
else:
return False
def write_data(num, content, path): # 这里的path是动漫文件夹的路径, num可用循环
with open(f'{path}\\{num}.mp4', 'wb') as file:
file.write(content)
@retry(stop=stop_after_attempt(5))
async def translate_bytes(session, num): # 参数为ts分流的url 异步函数有阻塞可协程加速
async with semaphore:
async with session.get(full_ts_urls[num], headers=headers) as res:
if res.status == 200:
content = await res.read()
return content, num # 设置阻塞
else:
return None
def translate_key(key_url):
res = requests.get(key_url)
if res.status_code == 200:
return res.content
else:
return None
@retry(stop=stop_after_attempt(5))
def aes_decode(encrypted_data, key, m3u8): # 参数为ts分流视频的二进制,和秘钥,还有m3u8的文本
"""先判断是否是AES-128加密方式,KEY:METHOD=AES-128 如果是则进行解密。如果不是则捕捉异常,并输出给控制台。"""
try:
encryption = re.search('KEY:.*?=(.*?),', m3u8, re.S).group(1).strip() if re.search('KEY:.*?=(.*?),', m3u8, re.S) else None
if encryption is not None:
if encryption == 'AES-128':
"""AES-128解密"""
cipher = AES.new(key, AES.MODE_CBC, key)
data = cipher.decrypt(encrypted_data)
return data # 这里返回的data是二进制,直接写入视频格式文件即可解密成功
else:
logging.info('不是AES-128加密,请检查加密方式')
else:
return False
except ValueError:
logging.error(ValueError)
print(encrypted_data)
def write_txt(txt_path, path, num): # 这里的path是文件夹路径, num与上面用法一样
if os.path.exists(txt_path):
with open(txt_path, 'a+', encoding='utf-8') as f:
f.write(f"file '{path}\\{num}.mp4'" + '\n')
def ffmpeg_combine(video_path, txt_path, name, num): # 这里是将txt里的视频路径依次合并,video_path需要用户输入
"""先查找txt_path是否存在,然后再依次合并, 并检查合并好的文件是否存在"""
if os.path.exists(txt_path):
name = name.replace('/', '')
order = f'ffmpeg -f concat -safe 0 -i {txt_path} -c copy {video_path}\\{name}第{num}集.mp4 -loglevel quiet'
subprocess.run(order)
if os.path.exists(f'{video_path}\\{name}第{num}集.mp4'):
logging.info('下载成功啦!')
else:
print('下载失败了,原因是合并时出现了问题')
else:
logging.error(f'{txt_path}不存在,请检查是否创建')
def handle_input(input_content): # 处理用户输入的数据,将其拆分成name,和url片段
name = re.search('(.*?):', input_content).group(1).strip() if re.search('(.*?):', input_content) else None
name = name.replace(' ', '')
args = re.search('.*?:(.*?).html', input_content).group(1).strip() if re.search('.*?:(.*?).html', input_content) else None
args = args + '.html'
return name, args
def clear(file_path, txt_path):
try:
for i in range(len(full_ts_urls)):
os.remove(f'{file_path}\\{i}.mp4')
os.remove(txt_path)
except FileNotFoundError:
logging.error('FileNotFoundError!')
@retry(stop=stop_after_attempt(5))
async def listen(url):
async with async_playwright() as p: # 事件监听
browser = await p.firefox.launch(headless=True, args=['--User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'])
# executable_path=r'firefox\firefox.exe
page = await browser.new_page()
page.on('response', on_response)
await page.goto(url)
# page.wait_for_load_state('networkidle')
await browser.close()
if m3u8s:
print(m3u8s[-1])
async def main():
global full_ts_urls
full_ts_urls = []
input_content = input('请输入你要下载的动漫:')
base_path = input('请输入保存路径:')
handle_result = handle_input(input_content)
name = handle_result[0]
args = handle_result[1]
args_id = display_id(args)
episode_html = fix_url(args)
all_episode = find_all_episodes(episode_html)
if all_episode == '全集': # 纠正输出内容
all_episode = '1集'
if '第' in all_episode:
all_episode = re.sub('第', '', all_episode)
if all_episode == 'PV':
all_episode = '1集'
print(f'{name}一共有{all_episode}')
episode = input('你要下载第几集?:')
the_url = select_episode(args_id, episode)
logging.info('正在监听网络请求中...(可能稍慢~请耐心等待, 如果失败请检查网络并重新启动)')
await listen(the_url)
if m3u8s:
m3u8 = m3u8s[-1]
m3u8_text = scrape_page(m3u8)
file_path = makefile(name, base_path) # 创建文件夹
txt_path = make_txt(name, file_path) # 创建txt文档
front_url = re.search('(.*?)/hls/', m3u8).group(1).strip() if re.search('(.*?)/hls/', m3u8) else None
if front_url is not None:
front_url = front_url + '/hls/'
true_false = read_ts(m3u8_text)
if true_false == 'hls':
for i in range(len(full_ts_urls)):
full_ts_urls[i] = re.sub('.*?/hls/', '', full_ts_urls[i])
full_ts_urls[i] = front_url + full_ts_urls[i]
elif true_false == 'http':
pass
else:
full_ts_urls = [f'{front_url}{url}' for url in full_ts_urls]
if keys:
key_url = keys[-1]
key = translate_key(key_url)
# print(key)
key_start = time.time()
async with aiohttp.ClientSession(headers=headers) as session: # 协程
# key = await translate_bytes(key_url, session)
# print(full_ts_urls[0])
tasks = [asyncio.ensure_future(translate_bytes(session, num)) for num in range(len(full_ts_urls))]
# contents = await asyncio.gather(*tasks)
pbar = tqdm.tqdm(total=len(full_ts_urls))
for coroutine in asyncio.as_completed(tasks):
content = await coroutine
# print(content)
data = aes_decode(content[0], key, m3u8_text) # 解密(AES-128)
write_data(content[1], data, file_path)
pbar.update(1)
pbar.close()
for i in range(len(full_ts_urls)):
write_txt(txt_path, file_path, i)
print('正在清理内存中...')
ffmpeg_combine(file_path, txt_path, name, episode)
clear(file_path, txt_path)
key_end = time.time()
total_time = (key_end - key_start) / 60
print('用时:' + f'{total_time}min')
else: # 没有加密
no_key_start = time.time()
async with aiohttp.ClientSession(headers=headers) as session: # 协程
tasks = [asyncio.ensure_future(translate_bytes(session, num)) for num in range(len(full_ts_urls))]
# contents = await asyncio.gather(*tasks)
pbar = tqdm.tqdm(total=len(full_ts_urls))
for coroutine in asyncio.as_completed(tasks):
content = await coroutine
write_data(content[1], content[0], file_path) # 写入解密后的数据
pbar.update(1)
pbar.close()
for i in range(len(full_ts_urls)):
write_txt(txt_path, file_path, i)
print('正在清理内存中...')
ffmpeg_combine(file_path, txt_path, name, episode)
clear(file_path, txt_path)
no_key_end = time.time()
total_time = (no_key_end - no_key_start) / 60
print('用时:' + f'{total_time}min')
else:
print('动漫已经失效')
if __name__ == '__main__':
asyncio.run(main())
print('按ESC结束进程~o( =∩ω∩= )m')
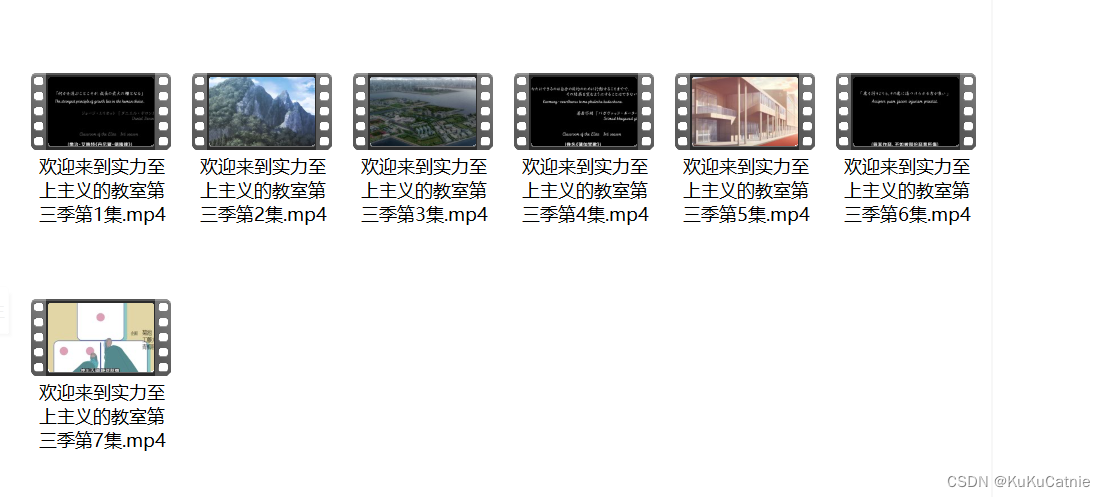
keyboard.wait('Esc')最后展示一下成果吧:

















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









