







GraphCAR: Content-aware Multimedia Recommendation with Graph Autoencoder
这是第一篇论文阅读笔记,阅读过程借助AI(纯英文真的头疼),不知道现在开始来不来得及,今天衣服还找不着了
摘要
从海量候选项目中为用户精准推荐相关多媒体内容,是当前众多平台不可或缺却极具挑战性的任务。一种有效方法是将用户和项目映射到潜在空间,通过潜在因子向量的内积运算实现推荐。然而,既有研究往往忽视多媒体内容本身特性,且未能充分利用隐式反馈等偏好数据。为此,我们提出基于图自编码器的内容感知多媒体推荐模型(GraphCAR),通过融合多媒体内容信息与用户-项目交互实现推荐。具体而言,模型将用户-项目交互数据、用户属性及多媒体内容(如图像、视频、音频等)作为自编码器输入,生成面向每个用户的项目偏好评分。通过在Amazon和Vine两大真实多媒体网络服务平台的实验表明,GraphCAR在协同过滤和基于内容的推荐方法上均显著优于现有最优技术。
介绍
近年来,推荐系统在多媒体领域发挥了重要的作用。然而,在大多数这些Web服务中,用户数量和图像/视频数量急剧增长,使得多媒体推荐比以往任何时候都更具挑战性。占主导地位的Web多媒体内容要求现代推荐系统,特别是基于协同过滤( CF )的推荐系统,在高度动态的环境中为用户筛选海量多媒体内容。
协同过滤方法将具有相似兴趣的人群进行分组,并在此基础上进行推荐。在多媒体推荐中,项目表示不同种类的多媒体内容。大多数CF方法依赖于项目的星级评分,提供显式反馈。
然而,传统的CF方法在应用于多媒体领域时,有两个缺点。首先,CF方法没有关注多媒体内容本身,而多媒体内容是用户选择图像或视频时最重要的因素。由于物品的内容信息是可用的,因此引入了内容感知方法。这种对内容信息的融入通常会带来更好的推荐性能。第二,在许多应用中,显式评分并不总是可用的。更多时候,照片的"喜欢"、电影的"观看"等动作间数据更便于收集。这样的数据是基于隐式反馈的。
为了将多媒体内容与CF方法相结合,并充分利用隐式反馈,本文提出了一种新颖的基于图自动编码的内容感知多媒体推荐框架( GraphCAR )。我们使用两个图卷积网络作为编码器,分别对用户和物品的潜在因子进行建模。之后,我们利用两个潜在因子向量的内积生成偏好分数。
主要贡献
提出了一种新颖的基于图自编码器的内容感知多媒体推荐模型( GraphCAR ),将图自动编码器应用于隐式反馈的CF中。
在两个真实数据集上的实验表明,Graph CAR显著优于CF和基于内容的方法。
模型学习
用户集合是 u = [1, 2, ..., N],也就是总共有 N 个用户;
物品集合是 v = [1, 2, ..., M],表示有 M 个物品。
R 是一个用户和物品之间的交互矩阵(interaction matrix)
- 这个矩阵的大小是
N × M,行表示用户,列表示物品; - 每个元素
Rij表示用户i是否与物品j发生过交互(如点击、浏览、点赞等); - 通常这是一种隐式反馈,不像评分那样明确打分。
Rij 表示:第 i 个用户对第 j 个物品的交互情况;
- 如果
Rij = 1,表示这个用户浏览/点击/喜欢过这个物品; - 如果
Rij = 0,则表示没有互动,或者我们不知道是否喜欢。
我们用一个集合 R 来收集所有发生过互动的“用户-物品对”。
- 这个集合里只包含那些交互值
Rij = 1的(i, j)组合; - 换句话说,R 是一个“已知互动行为的记录集合”。
潜在因子模型(Latent Factor Models)
这是协同过滤的一种核心实现方式,潜在因子模型会把用户和物品共同映射到一个 D 纬向量空间中,
每个用户和每个物品都被表示成一个“向量”;这个向量背后代表了某些抽象的偏好维度(如用户喜欢动作片 vs 爱情片、物品风格等)。
用户矩阵为 U = [u1, ..., uN],每个 ui 是一个 D 维向量;
物品矩阵为 V = [v1, ..., vM],每个 vj 也是一个 D 维向量;
- 这个 D 是“潜在维度数”,通常比用户数 N 和物品数 M 小很多;
- 这样可以降维、压缩数据,同时提取出本质的偏好特征。
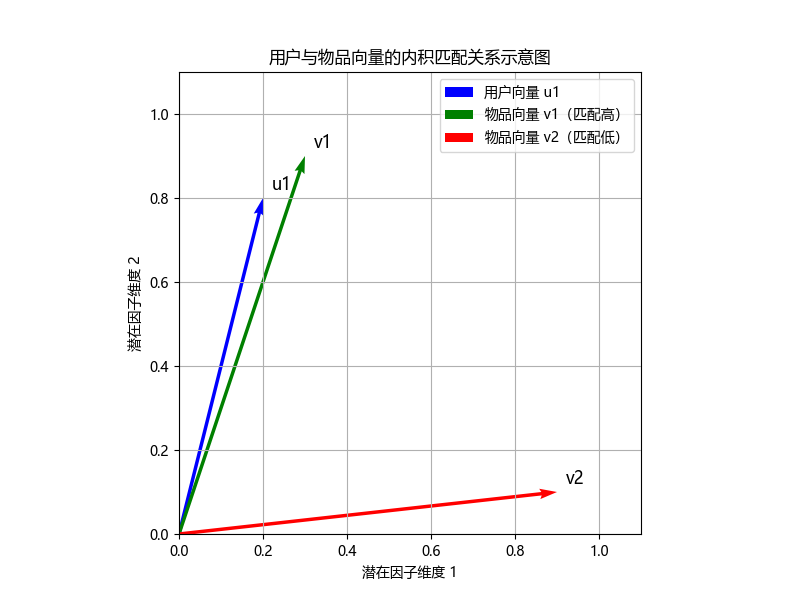
我们用 内积 来预测用户对物品的喜好程度:
R
^
i
j
=
u
i
T
v
j
\hat{R}_{ij} = u_i^T v_j
R^ij=uiTvj
-
如果
ui和vj很相似(方向接近),内积值大,代表用户可能喜欢该物品; -
如果两者相差很大,内积小,代表兴趣不大。
用一张图来表示:
The objective is to minimize the following regularized squared loss on observed ratings:
min
U
,
V
∑
(
i
,
j
)
∈
R
(
R
i
j
−
R
^
i
j
)
2
+
λ
(
∥
U
∥
2
+
∥
V
∥
2
)
\min_{U,V} \sum_{(i,j)\in R} (R_{ij} - \hat{R}_{ij})^2 + \lambda \left( \|U\|^2 + \|V\|^2 \right)
U,Vmin(i,j)∈R∑(Rij−R^ij)2+λ(∥U∥2+∥V∥2)
这个是模型的目标函数(损失函数):
-
目标是让预测值 ( R ^ i j \hat{R}_{ij} R^ij) 尽量接近实际交互值 ( R i j R_{ij} Rij);
-
其中 ( R ) 是用户和物品之间已知交互的集合;
-
同时加了一个正则项(L2范数):
-
- ( λ ( ∣ U ∣ 2 + ∣ V ∣ 2 ) \lambda (|U|2 + |V|2) λ(∣U∣2+∣V∣2)) 是为了防止过拟合(让参数不要太大);
- λ 是正则化系数,控制惩罚力度。
BPR(Bayesian Personalized Ranking)模型。
BPR 是一种用于解决协同过滤中隐式反馈问题的框架。
- 隐式反馈(implicit feedback):指的是用户没有明确打分,而是通过点击、浏览、点赞等行为间接表达喜好;
- 传统的评分预测方法不适用于这种没有明确评分的情况;
- BPR 就是为了解决这个问题而设计的。
BPR 将训练数据建模为三元组:(user, positive item, negative item)
- 对于每个用户
i,选出一个他喜欢的物品j(有交互),再选出一个他没互动的物品k; - 假设用户更喜欢
j而非k,即:用户偏好排序而不是具体评分!
The widely used BPR objective is given as :
min U , V ∑ ( i , j , k ) ∈ R B − ln σ ( R ^ i j − R ^ i k ) + λ ( ∥ U ∥ 2 + ∥ V ∥ 2 ) \min_{U,V} \sum_{(i,j,k)\in R_B} -\ln \sigma(\hat{R}_{ij} - \hat{R}_{ik}) + \lambda (\|U\|^2 + \|V\|^2) U,Vmin(i,j,k)∈RB∑−lnσ(R^ij−R^ik)+λ(∥U∥2+∥V∥2)
这是 BPR 的目标函数:
-
(
R
^
i
j
)
(\hat{R}_{ij})
(R^ij) 是预测用户对物品
j的偏好得分; - 希望$ (\hat{R}{ij} > \hat{R}{ik})$,即更偏好
j; - ( σ ( ⋅ ) ) (\sigma(\cdot)) (σ(⋅)) 是sigmoid函数,可以将差值转化为概率;
- − ln σ ( . . . ) -\ln σ(...) −lnσ(...) 是交叉熵损失,用于衡量排序是否正确;
- 加上 L2 正则化项避免过拟合。
The training data RB is generated as:
R B = { ( i , j , k ) ∣ j ∈ R ( i ) , k ∈ I ∖ R ( i ) } R_B = \{(i,j,k) \mid j \in R(i), k \in I \setminus R(i) \} RB={(i,j,k)∣j∈R(i),k∈I∖R(i)}
表示训练样本是所有可能的 ( 用户 i , 正例 j , 负例 k ) (用户i, 正例j, 负例k) (用户i,正例j,负例k) 三元组的集合:
- R ( i ) R(i) R(i) 是用户 i i i 曾经交互过的物品集合;
- k ∈ I ∖ R ( i ) k \in I \setminus R(i) k∈I∖R(i) 是他没交互过的物品;
- 用这种构造方法生成训练样本。
The semantics of (i, j, k) ∈ RB is that user i is assumed to prefer item j over k.
( i , j , k ) (i, j, k) (i,j,k) 的含义是:假设用户 i 更喜欢物品 j 而不是 k
In this work, we use BPR as our basic learning model.
本文以 BPR 排序模型作为推荐系统的基本优化目标。
图卷积网络(Graph Convolutional Networks, GCN)
推荐系统可以被建模成用户-物品二分图,Graph Convolutional Network(GCN)是一种有效的方式来学习节点表示,用于预测潜在的用户-物品链接。但由于用户和物品的数量和类型不同,标准的 GCN 传播方式需要被修改以适应推荐任务。
如果我们把用户和物品看做是一个二分图中的两个节点集合,推荐问题就可以转换为链接预测问题
- 即:判断“哪些用户可能会与哪些物品形成连接”,本质就是预测用户是否会喜欢某个物品。
Graph Convolutional Networks have proved effective in various tasks related to graphs, including collaborative filtering recommendation, but there is not much attention paid on content-aware recommendation.
GCN 在图相关任务(包括协同过滤推荐)中表现优秀,但很少用于**结合内容信息(如图片、文本等)**的推荐。
- 本文的创新点就是尝试将 GCN 与内容信息结合(即 Content-aware Recommendation)。
Graph Convolutional Networks take adjacency matrix A and feature matrix X as the input, and produce the node-level output Z.
📌 GCN 的输入:
A:邻接矩阵,表示图中节点间的连接关系;X:节点特征矩阵,比如用户/物品的属性;- 输出
Z:每个节点的表示向量(经过多层卷积后的结果)。
Layer-wise propagation rule is given as:
H ( l + 1 ) = a ( A ⋅ H ( l ) ⋅ W ( l ) ) H^{(l+1)} = a(A \cdot H^{(l)} \cdot W^{(l)}) H(l+1)=a(A⋅H(l)⋅W(l))
📌 每一层的更新规则(第 l 层到第 l+1 层)是:
- 把上一层的特征 H ( l ) H^{(l)} H(l) 和权重矩阵 W ( l ) W^{(l)} W(l) 做矩阵乘法;
- 再和邻接矩阵
A相乘; - 最后通过非线性函数 a a a(如 ReLU 或 sigmoid)处理;
- 得到当前层新的表示 H ( l + 1 ) H^{(l+1)} H(l+1)。
However, we can not directly use Equation (5) for our task. When we apply it to recommendation, the adjacency matrix is not symmetric anymore, since the number of user doesn’t equal to that of item.
📌 但对于推荐系统中的二分图,这种标准的 GCN 传播公式并不能直接用。
- 因为用户数 ≠ 物品数;
- 图的邻接矩阵
A不是对称的(用户和物品不是同一类节点); - 所以需要特殊设计 GCN 的传播结构,适应这种异构图的推荐场景。
GraphCAR模型设计
整体框架
GraphCAR 是一个神经网络模型,它的目标是预测用户对多媒体内容的偏好分数(比如:点击/点赞图片或视频的可能性)。
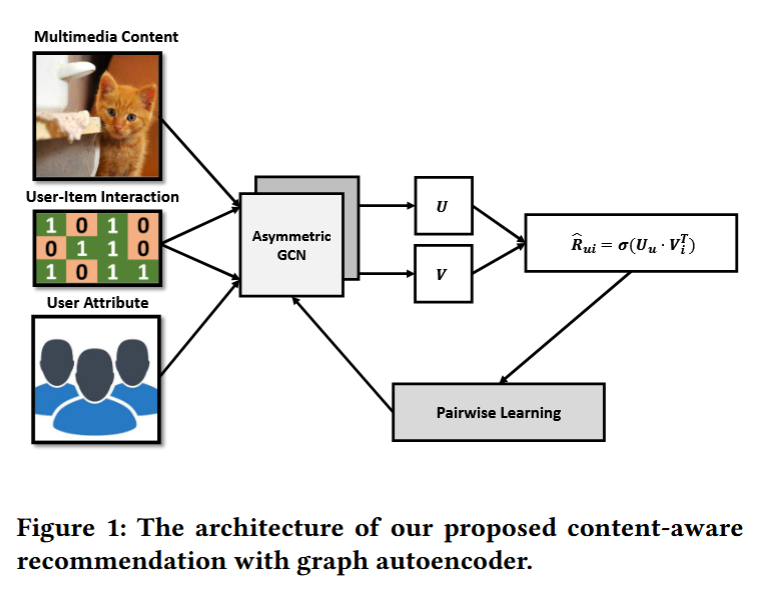
用户和物品分别由两个**两层的图卷积网络(GCN)**编码,目的是提取用户兴趣和物品内容的隐藏特征
然后,用户和物品的向量做内积(dot product),得到一个偏好分数:
R ^ u i = u u ⊤ v i \hat{R}_{ui} = \mathbf{u}_u^\top \mathbf{v}_i R^ui=uu⊤vi
使用 BPR 损失函数(排序损失)+ 反向传播算法来训练 GCN 网络里的权重参数。 一旦训练完成,我们就可以用预测分数进行排序,把最高分的物品推荐给用户。
3.2 Encoder: Graph Convolutional Networks(编码器)
有 m 个用户、n 个物品;
- 每个用户用
du维向量表示(如性别、年龄); - 每个物品用
di维多媒体特征表示(如图片 CNN 特征);
作者设计了一个非对称 GCN(Asymmetric GCN),因为用户数和物品数不一样,需要分别编码。
用户表示公式:
U
0
=
ReLU
(
R
T
⋅
I
⋅
P
0
)
(6)
U_0 = \text{ReLU}(R^T \cdot I \cdot P_0) \tag{6}
U0=ReLU(RT⋅I⋅P0)(6)
U
=
σ
(
R
⋅
U
0
⋅
P
1
)
(7)
U = \sigma(R \cdot U_0 \cdot P_1) \tag{7}
U=σ(R⋅U0⋅P1)(7)
I是用户属性矩阵(大小 m × du)R是交互矩阵(m × n),R^T是转置;P₀、P₁是训练得到的权重;σ是激活函数(sigmoid)
含义:利用图结构 + 用户属性,通过两层卷积得到用户的最终潜在向量 U
物品表示公式:
V
0
=
ReLU
(
R
⋅
X
⋅
W
0
)
(8)
V_0 = \text{ReLU}(R \cdot X \cdot W_0) \tag{8}
V0=ReLU(R⋅X⋅W0)(8)
V
=
σ
(
R
T
⋅
V
0
⋅
W
1
)
(9)
V = \sigma(R^T \cdot V_0 \cdot W_1) \tag{9}
V=σ(RT⋅V0⋅W1)(9)
- X X X 是物品特征(n × di);
- W 0 W₀ W0、 W 1 W₁ W1 是物品端权重矩阵;
- 同样是两层卷积处理。
含义:通过交互关系和多媒体特征,得到物品的潜在向量 V
Decoder and Objective Function(解码器和损失函数)
预测分数(Decoder)
R ^ = U ⋅ V T (10) \hat{R} = U \cdot V^T \tag{10} R^=U⋅VT(10)
- 这就是经典的潜在因子模型:用户向量 × 物品向量转置,得到预测分数矩阵。
优化目标函数(使用 BPR):
min Θ ∑ ( u , i , j ) ∈ R B − log σ ( R ^ u i − R ^ u j ) + λ 2 ∑ Θ ∥ Θ ∥ 2 (11) \min_\Theta \sum_{(u,i,j)\in R_B} -\log \sigma(\hat{R}_{ui} - \hat{R}_{uj}) + \frac{\lambda}{2} \sum_{\Theta} \|\Theta\|^2 \tag{11} Θmin(u,i,j)∈RB∑−logσ(R^ui−R^uj)+2λΘ∑∥Θ∥2(11)
- ( u , i , j ) (u,i,j) (u,i,j) 是三元组:用户 u 喜欢物品 i,不喜欢物品 j;
- R ^ u i \hat{R}_{ui} R^ui 是 u 对 i 的预测分数;
- σ σ σ 是 sigmoid 函数,把差值转成概率;
- Θ Θ Θ 是所有权重参数的集合( P 0 , P 1 , W 0 , W 1 P₀, P₁, W₀, W₁ P0,P1,W0,W1);
- λ λ λ 是正则化系数,防止过拟合。
总结一句话:
GraphCAR 的整个流程是:输入用户属性 + 多媒体特征 + 用户行为,使用两路 GCN 提取向量,再通过内积预测偏好得分,并用 BPR 排序损失训练。
由于本人还太菜,实验复原部分就不总结了,有兴趣可以去原论文看看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









