






目录
一、导入数据
#将华南地区的数据作为样本数据,导入data变量中
import pandas
data = pandas.read_csv('华南地区.csv',encoding='utf8')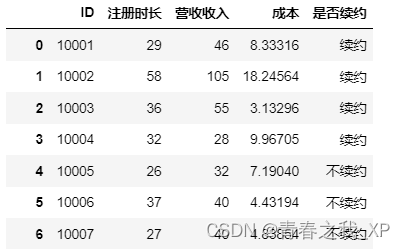
#导入需要预测的华北地区数据
import pandas
华北地区数据 = pandas.read_csv('华北地区.csv',encoding='utf8')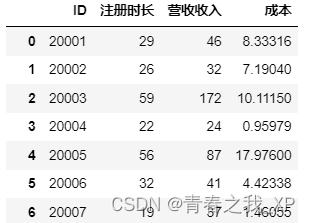
二、选择特征变量
#特征变量
x = data[['注册时长', '营收收入', '成本']]
#目标变量
y = data['是否续约']三、划分训练集和测试集
from sklearn.model_selection import train_test_split
#把数据集分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3
)四、训练KNN模型
from sklearn.neighbors import KNeighborsClassifier
#新建一个KNN模型,设置个数为3
knnModel = KNeighborsClassifier(n_neighbors=3)
#使用训练集训练KNN模型
knnModel.fit(x_train, y_train)
#使用测试集测试KNN模型
knnModel.score(x_test, y_test)在测试集上的准确率分数如下:
![]()
五、进行预测
#预测测试数据集的目标变量
y_test_predict = knnModel.predict(x_test)
六、计算混淆矩阵
#计算混淆矩阵
from sklearn.metrics import confusion_matrix
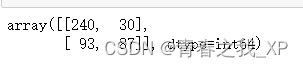
confusion_matrix(
y_test,
y_test_predict,
labels=['续约', '不续约']
)
七、计算准确率
#准确率
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_test_predict)
#混淆矩阵
#array([[225, 82],
# [ 56, 87]], dtype=int64)
#(225+87)/(225+82+56+87)![]()
八、计算精确度
#精确率
from sklearn.metrics import precision_score
precision_score(y_test, y_test_predict, pos_label="续约")
precision_score(y_test, y_test_predict, pos_label="不续约")
#混淆矩阵
#array([[225, 82],
# [ 56, 87]], dtype=int64)
#(225)/(225+56)![]()
九、计算召回率
#召回率
from sklearn.metrics import recall_score
recall_score(y_test, y_test_predict, pos_label="续约")
recall_score(y_test, y_test_predict, pos_label="不续约")
#混淆矩阵
#array([[225, 82],
# [ 56, 87]], dtype=int64)
#(225)/(225+82)![]()
十、计算F1值
#f1值
from sklearn.metrics import f1_score
f1_score(y_test, y_test_predict, pos_label="续约")
f1_score(y_test, y_test_predict, pos_label="不续约")
#混淆矩阵
#array([[225, 82],
# [ 56, 87]], dtype=int64)
#2/(1/((225)/(225+56)) + 1/((225)/(225+82)))十一、计算十折交叉验证
from sklearn.model_selection import cross_val_score
#进行K折交叉验证
knnModel = KNeighborsClassifier(n_neighbors=3)
cvs = cross_val_score(knnModel, x, y, cv=10)
cvs
cvs.mean()十二、选取最优参数K值
(一)设置空列表用于储存分数
from sklearn.metrics import make_scorer
#用来保存KNN模型的邻居个数
ks = []
#用来保存准确率
accuracy_means = []
#用来保存精确率
precision_means = []
#用来保存召回率
recall_means = []
#用来保存f1值
f1_means = [](二) 通过for循环遍历K值
#n_neighbors参数,从2到29,一个个尝试
for k in range(2, 30):
#把n_neighbors参数保存起来
ks.append(k)
#改变KNN模型的参数n_neighbors为k
knnModel = KNeighborsClassifier(n_neighbors=k)
#计算10折交叉验证的准确率
accuracy_cvs = cross_val_score(
knnModel,
x, y, cv=10,
scoring=make_scorer(accuracy_score)
)
#将10折交叉验证的准确率的均值保存起来
accuracy_means.append(accuracy_cvs.mean())
#计算10折交叉验证的精确率
precision_cvs = cross_val_score(
knnModel,
x, y, cv=10,
scoring=make_scorer(
precision_score,
pos_label="续约"
)
)
#将10折交叉验证的精确率的均值保存起来
precision_means.append(precision_cvs.mean())
#计算10折交叉验证的召回率
recall_cvs = cross_val_score(
knnModel,
x, y, cv=10,
scoring=make_scorer(
recall_score,
pos_label="续约"
)
)
#将10折交叉验证的召回率的均值保存起来
recall_means.append(recall_cvs.mean())
#计算10折交叉验证的f1值
f1_cvs = cross_val_score(
knnModel,
x, y, cv=10,
scoring=make_scorer(
f1_score,
pos_label="续约"
)
)
#将10折交叉验证的f1值的均值保存起来
f1_means.append(f1_cvs.mean())(三) 生成各个K值对应的模型评分
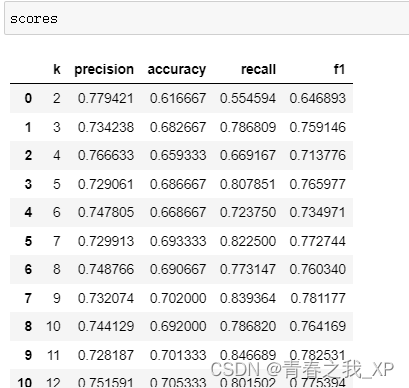
#生成参数对应的模型评分
scores = pandas.DataFrame({
'k': ks,
'precision': precision_means,
'accuracy': accuracy_means,
'recall': recall_means,
'f1': f1_means
})
(四) 绘制不同参数K对应的评分的折线图
#绘制不同参数对应的评分的折线图
scores.plot(
x='k',
y=['accuracy', 'precision', 'recall', 'f1']
)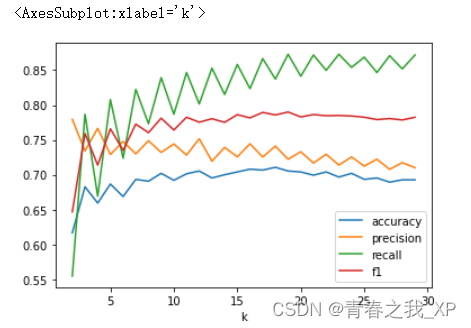
(五) 使用最佳参数n_neighbors=17建模
#使用最佳参数n_neighbors=17建模
knnModel = KNeighborsClassifier(n_neighbors=17)
#使用所有训练样本训练模型
knnModel.fit(x, y)
#对未知的目标数据进行预测
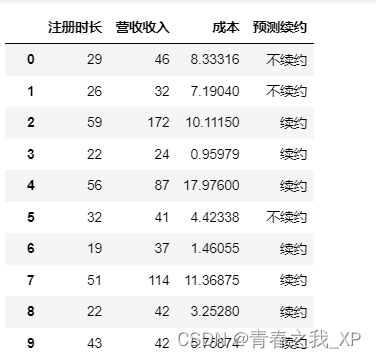
华北地区数据['预测续约'] = knnModel.predict(
华北地区数据[['注册时长', '营收收入', '成本']]
)pandas.options.display.max_columns = None
pandas.options.display.max_rows = None
华北地区数据[['注册时长','营收收入','成本','预测续约']]预测结果如下:


















 6469
6469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









