






目录
(六)补充:X_pca 和y是怎么联系的,当时X_pca = pca.fit_transform(X) 其中也没有用到y呀
本文旨在为读者提供一个关于过采样技术的全面概述,包括其基本概念、实现方法以及与数据增强的关系。过采样是处理不平衡数据集的常用技术之一,通过增加少数类的样本来平衡类别分布。我们将重点介绍SMOTE(合成少数过采样技术)算法,并通过Python代码示例演示如何在不平衡数据集上应用SMOTE进行过采样。文章还将探讨过采样和欠采样是否属于数据增强的范畴,并解释在PCA降维过程中X_pca与y之间的内在联系。最后,我们将对比展示过采样前后的数据分布情况,以直观地理解过采样对数据集的影响。无论您是数据科学新手还是希望深化对不平衡学习问题处理方法的理解,本文都将为您提供有价值的见解和实用技巧。
一、过采样简介
过采样(Oversampling)是一种用于处理数据集中类别不平衡问题的技术。在数据集中,当一个类的样本数量远少于另一个类时(例如,正类样本远少于负类样本),模型训练可能会偏向于数量较多的类,导致模型在少数类上的性能不佳。过采样通过增加少数类的样本数量来尝试解决这个问题,使得类别分布更加均匀。
二、过采样的实现方法
简单复制(Random Oversampling): 这是最简单的过采样方法,直接通过随机复制少数类中的样本来实现。这种方法操作简单,但容易导致过拟合,因为复制的数据并没有增加新的信息。
SMOTE(Synthetic Minority Oversampling Technique): SMOTE是一种更为先进的过采样技术。它不是简单复制现有的少数类样本,而是通过在少数类样本之间进行插值来创建新的合成样本。具体来说,对于每个少数类样本,算法会找到其k个最近邻,然后在这些近邻之间随机选择一个点,并与原始样本之间进行线性插值来生成新的样本。
ADASYN(Adaptive Synthetic Sampling): ADASYN是一种改进的SMOTE算法,它根据少数类样本在特征空间中的分布自动调整采样过程。在类别边界附近,ADASYN会更多地生成新的合成样本。
SMOTE-ENN(SMOTE with Edited Nearest Neighbors): 结合了SMOTE和Tomek Links的过采样方法。在生成合成样本之后,使用ENN(Edited Nearest Neighbors)方法删除那些可能导致过拟合的样本。
SMOTE-RSB(SMOTE with Repeated Simplified Basic): 该方法结合了SMOTE和简化基本过采样(Simplified Basic Oversampling)的策略,通过重复采样来增强少数类的样本。
其他变种: 还有一些其他基于SMOTE的变种方法,比如使用不同的距离度量(如马氏距离)或考虑样本权重等因素。
过采样方法的选择取决于具体的数据集和任务。需要注意的是,过采样可能会引入噪声,增加模型的复杂度,因此在实际应用中需要谨慎使用,并常常结合交叉验证等技术来评估模型性能。在Python中,
imbalanced-learn(或imblearn)库提供了多种过采样方法的实现。
三、过采样和欠采样是数据增强吗
过采样和欠采样通常不被视为数据增强技术。虽然它们都涉及到对数据集的操作,但它们的目的和方法与数据增强有所不同。
数据增强(Data Augmentation): 数据增强是一种在训练数据集中创建新的训练样本的技术,通常用于图像、语音和文本等领域。数据增强的目的是通过增加数据的多样性来提高模型的泛化能力。例如,在图像处理中,数据增强可能包括旋转、缩放、裁剪、翻转等操作。
四、Python实现SMOTE过采样
(一) 生成不平衡数据集
我们使用sklearn的make_classification函数来生成一个不平衡的数据集,然后使用SMOTE算法对少数类进行过采样
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
from collections import Counter
import pandas as pd
# 生成一个不平衡的数据集
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
print('原始数据集的类别分布:', Counter(y))![]()
make_classification:这是用于生成分类数据集的函数。
n_classes=2:指定生成的数据集应该有2个类别(二分类问题)。
class_sep=2:指定类别之间的分离程度。值越大,类别之间的分离越明显。
weights=[0.1, 0.9]:指定每个类别的样本权重,或者可以理解为每个类别在总样本中的比例。这里,类别0的样本占总样本的10%,类别1的样本占90%,这表明生成的数据集是不平衡的。
n_informative=3:指定有多少特征是信息性的,即这些特征与目标变量有关联。
n_redundant=1:指定有多少特征是冗余的,即这些特征与信息性特征相关联,但与目标变量关联不大。
n_features=20:指定生成的数据集应该有多少个特征。
n_clusters_per_class=1:指定每个类别是否由一个单独的聚类中心生成。这里设置为1,意味着每个类别由一个聚类中心生成。
n_samples=1000:指定每个类别的样本数量。由于weights参数指定了类别比例,这里的1000是对总样本数的近似值,实际上会根据指定的权重来生成具体的样本数。
random_state=10:指定随机种子,以确保每次生成的数据集都是相同的,便于重现结果。
(二) 将数据集转换为DataFrame,便于展示
df = pd.DataFrame(X)
df['target'] = y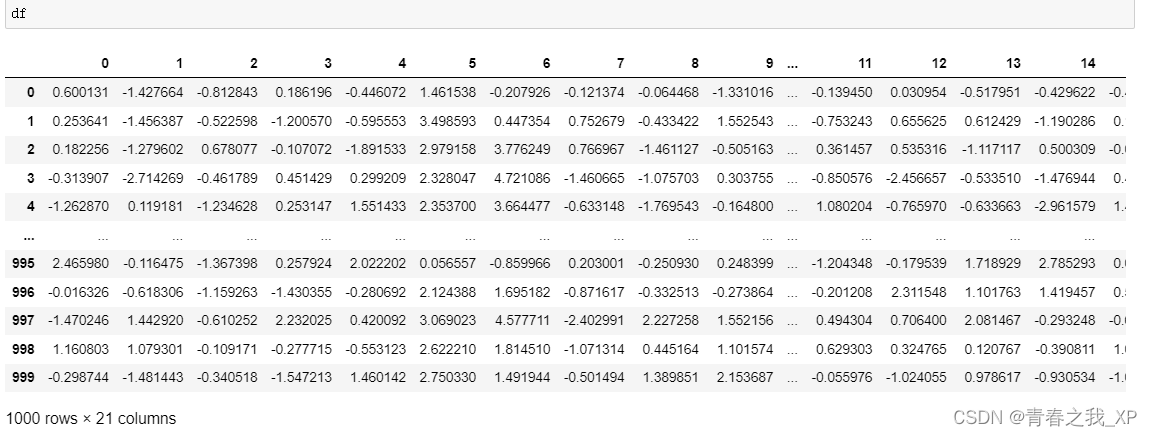
(三) 应用SMOTE算法进行过采样
# 应用SMOTE算法进行过采样
# sampling_strategy = {0: 100, 1: 100}
smote = SMOTE(random_state=42,sampling_strategy=0.6,k_neighbors=4)
X_resampled, y_resampled = smote.fit_resample(X,y)sampling_strategy:这个参数定义了少数类的采样策略。它可以是一个浮点数或字典。
- 如果是浮点数,表示最终少数类占多数类的比例,
sampling_strategy=0.6意味着最终的少数类样本的数量将是多数类样本数量的0.6倍。- 如果是字典,可以针对数据集中的每个类别指定不同的采样策略。如:sampling_strategy = {0: 540, 1: 900} ,就是希望0类样本是540个,1类样本是900个。
k_neighbors:这个参数指定了在合成新样本时考虑的最近邻的数量。在SMOTE中,合成样本是基于少数类的现有样本和它们在特征空间中的最近邻之间的差异生成的。k_neighbors=4意味着在合成新样本时,将考虑每个少数类样本的4个最近的邻居。这个值应该是一个整数,且大于1。
# 打印过采样后的类别分布
print('过采样后数据集的类别分布:', Counter(y_resampled))![]()
(四) 可视化原始数据分布
# 可视化原始和过采样后的数据分布
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 使用PCA降维以便可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
from matplotlib.ticker import FormatStrFormatter
# 绘制原始数据集
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(8, 6),dpi=100)
plt.scatter(X_pca[y == 0, 0], X_pca[y == 0, 1], s=30, edgecolors='k', c='blue', label='Class #0')
plt.scatter(X_pca[y == 1, 0], X_pca[y == 1, 1], s=30, edgecolors='k', c='red', label='Class #1')
# X_pca[y == 0, 0] 表示所有标签为0的样本在PCA降维后的第一个主成分上的坐标。
# X_pca[y == 0, 1] 表示所有标签为0的样本在PCA降维后的第二个主成分上的坐标。
plt.title('原始数据集')
plt.legend()
plt.tight_layout()
# 获取当前坐标轴并设置格式化
ax = plt.gca()
ax.xaxis.set_major_formatter(FormatStrFormatter('%f')) # 设置x轴格式化为浮点数
ax.yaxis.set_major_formatter(FormatStrFormatter('%f')) # 设置y轴格式化为浮点数
plt.show()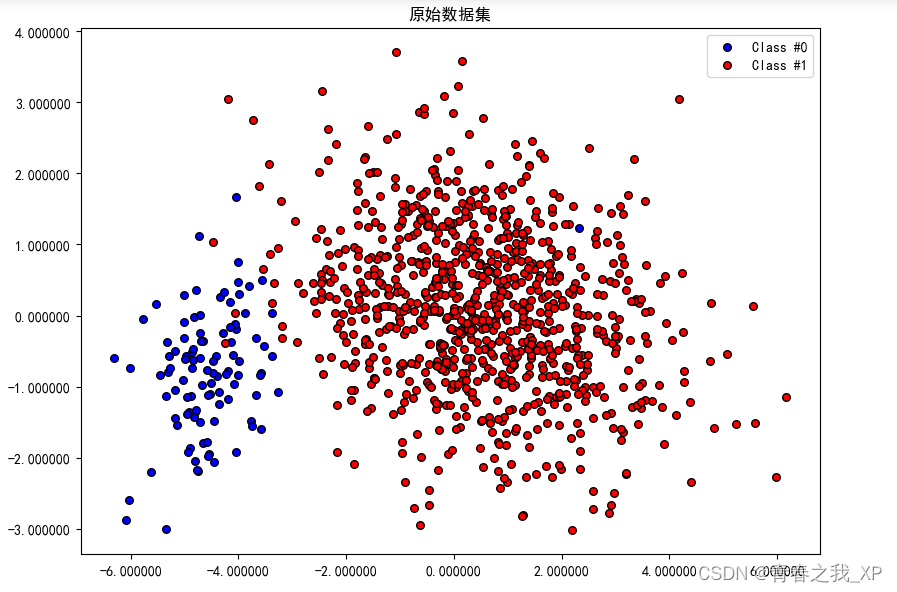
(五) 可视化过抽样后的数据分布
X_resampled_pca = pca.transform(X_resampled)# 绘制过采样后的数据集
plt.figure(figsize=(8, 6),dpi=100)
plt.scatter(X_resampled_pca[y_resampled == 0, 0], X_resampled_pca[y_resampled == 0, 1], s=30, edgecolors='k', c='blue', label='Class #0')
plt.scatter(X_resampled_pca[y_resampled == 1, 0], X_resampled_pca[y_resampled == 1, 1], s=30, edgecolors='k', c='red', label='Class #1')
plt.title('过采样后的数据集')
plt.legend()
plt.tight_layout()
# 获取当前坐标轴并设置格式化
ax = plt.gca()
ax.xaxis.set_major_formatter(FormatStrFormatter('%f')) # 设置x轴格式化为浮点数
ax.yaxis.set_major_formatter(FormatStrFormatter('%f')) # 设置y轴格式化为浮点数
plt.show()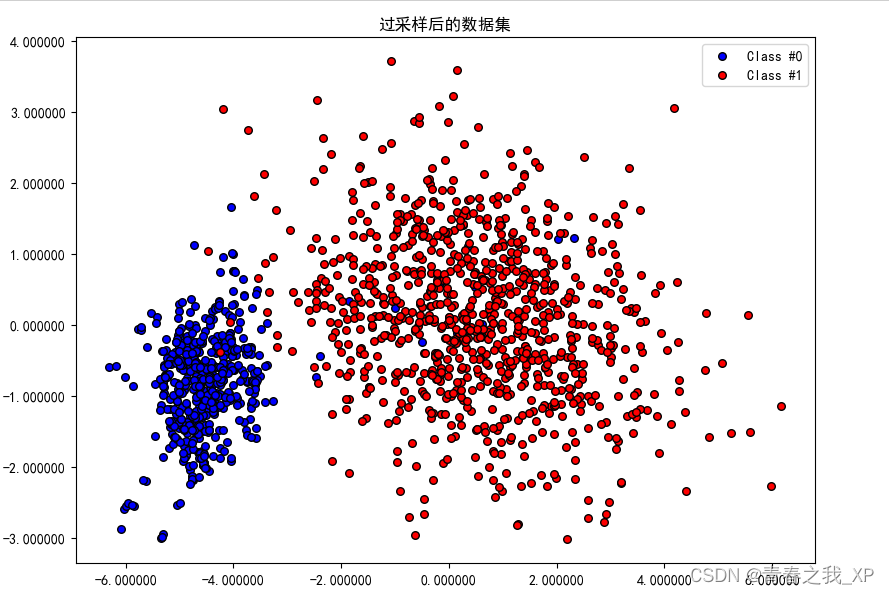
(六)补充:X_pca 和y是怎么联系的,当时X_pca = pca.fit_transform(X) 其中也没有用到y呀
X_pca 和 `y` 的联系并不体现在PCA的计算过程中,而是在于后续的数据分析和可视化过程中。
当执行 `X_pca = pca.fit_transform(X)` 时,PCA算法仅作用于输入的特征数据 `X`,目的是找出数据中的主要变化模式(即主成分),并将数据投影到这些主成分上以实现降维。这个过程是完全独立于标签 `y` 的,因为PCA是一种无监督的降维技术,它不考虑数据的类别标签。
尽管PCA的计算与 `y` 无关,但 `X_pca` 和 `y` 的联系体现在以下两个方面:
1. 样本对应:`X_pca` 和 `y` 是按照样本顺序对应的。即使PCA计算时没有用到 `y`,但 `X_pca` 中的每一行仍然代表 `X` 中相应行的降维表示,而 `y` 中的每一个标签仍然对应于 `X` 中相应行的类别。这种对应关系是数据分析的基础,因为我们需要知道每个降维后的样本点属于哪个类别。
2. 数据分析与可视化:在PCA计算完成后,我们通常希望了解不同类别在降维空间中的分布情况。为了实现这一点,我们需要将 `y` 中的类别标签与 `X_pca` 中的样本点结合起来。例如,在绘制散点图时,我们可以根据 `y` 中的值将样本点分类,并用不同的颜色或形状来表示不同的类别。这样,我们就可以直观地看到哪些样本点属于同一类别,以及不同类别在降维空间中的相对位置和重叠程度。
简而言之,尽管PCA的计算独立于类别标签 `y`,但在进行数据解释和可视化时,`y` 提供了必要的上下文,使我们能够将降维后的样本点与它们各自的类别关联起来,从而进行更深入的数据分析。
















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









