






1. SMOTE过采样

2. 要实现的效果
-
采样前(26x7),label为1的有6个,label为0的有20个
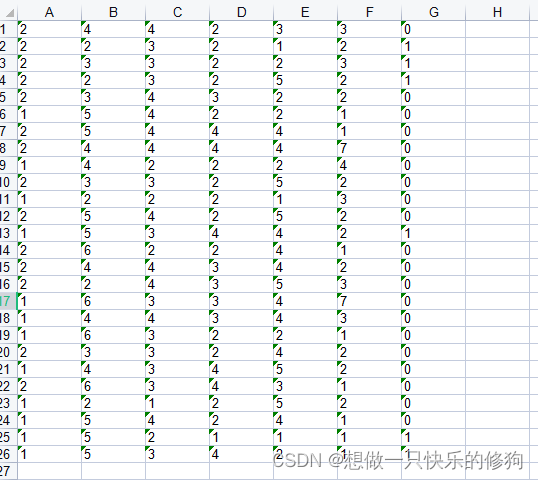
-
采样后(label为0和1的均有20个)
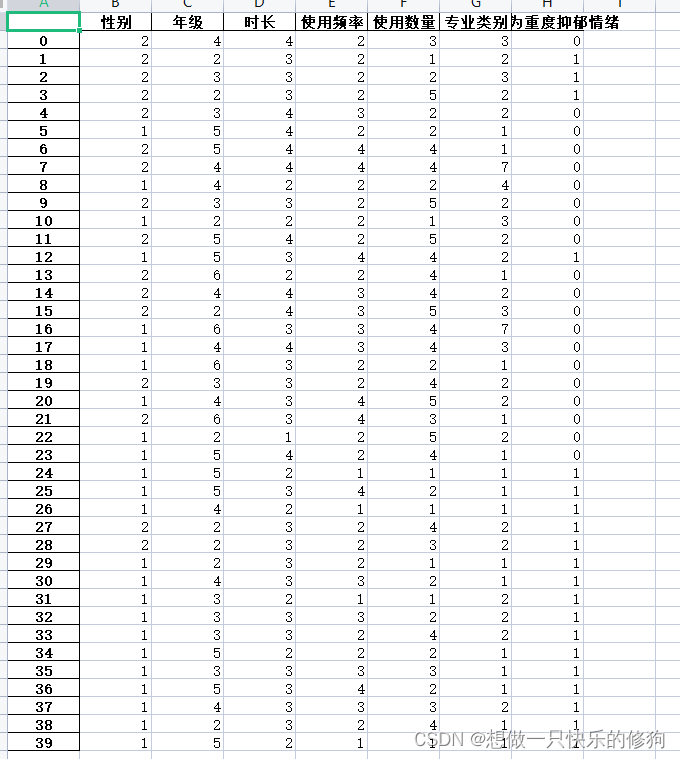
3. 代码
import xlwt # 负责写excel
import numpy as np
import pandas as pd
from imblearn.over_sampling import SMOTE
# 少数类(label为1):只有6个
# 多数类(label为0):有20个
matrix = [
[2, 4, 4, 2, 3, 3, 0],
[2, 2, 3, 2, 1, 2, 1],
[2, 3, 3, 2, 2, 3, 1],
[2, 2, 3, 2, 5, 2, 1],
[2, 3, 4, 3, 2, 2, 0],
[1, 5, 4, 2, 2, 1, 0],
[2, 5, 4, 4, 4, 1, 0],
[2, 4, 4, 4, 4, 7, 0],
[1, 4, 2, 2, 2, 4, 0],
[2, 3, 3, 2, 5, 2, 0],
[1, 2, 2, 2, 1, 3, 0],
[2, 5, 4, 2, 5, 2, 0],
[1, 5, 3, 4, 4, 2, 1],
[2, 6, 2, 2, 4, 1, 0],
[2, 4, 4, 3, 4, 2, 0],
[2, 2, 4, 3, 5, 3, 0],
[1, 6, 3, 3, 4, 7, 0],
[1, 4, 4, 3, 4, 3, 0],
[1, 6, 3, 2, 2, 1, 0],
[2, 3, 3, 2, 4, 2, 0],
[1, 4, 3, 4, 5, 2, 0],
[2, 6, 3, 4, 3, 1, 0],
[1, 2, 1, 2, 5, 2, 0],
[1, 5, 4, 2, 4, 1, 0],
[1, 5, 2, 1, 1, 1, 1],
[1, 5, 3, 4, 2, 1, 1],
]
def generateExcel(matrix):
matrix = np.array(matrix)
filename =xlwt.Workbook() # 创建工作簿
sheet1 = filename.add_sheet(u'sheet1',cell_overwrite_ok=True) # 创建sheet
[h,l] = matrix.shape # h为行数,l为列数
for i in range (h):
for j in range (l):
sheet1.write(i,j,str(matrix[i,j]))
filename.save('data.xlsx') #保存到当前工作目录
def savaToExcel(df):
'''
将dataframe存储到excel中
'''
outputPath = 'C:\work-file\pythonProject\Demo练习\output\output.xlsx'
writer = pd.ExcelWriter(outputPath)
data_resampled.to_excel(writer)
writer.save() # 保存文件
writer.close() # 关闭文件
if __name__ == '__main__':
# generateExcel(matrix)
col_name = ['性别', '年级', '时长', '使用频率', '使用数量', '专业类别', '是否为重度抑郁情绪']
data = pd.read_excel('C:\\work-file\\pythonProject\\Demo练习\\data.xlsx', sheet_name=0, names=col_name, header=None)
X = data.iloc[:, 0:6].values
y = data.iloc[:, 6].values
# 核心代码
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
data_resampled = np.zeros([len(y_resampled), 7]) # 构造 40 x 7 的元素为0的矩阵
# 合并数据(SMOTE过采样后的数据:少数、多数的样本都是20,共40个)
data_resampled[:, :6] = X_resampled
data_resampled[:, 6] = y_resampled
# 将数据保存成dataframe,为了后面保存到Excel中
data_resampled = pd.DataFrame(data_resampled, columns=col_name)
print(data_resampled)
# 保存数据至excel
savaToExcel(data_resampled)
4. 参考
P.S.我是根据这个文章,将他的数据保存至excel中然后再读取,数据稍微改了下,因为SMOTE去采样的时候报错了,所以我将数据增加至26行。因为python版本的问题,很多原博客里面的API(ix、fit_sample)也不能用了,我都更新到了python3.8可以用的api。
















 7911
7911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











