






一.引言
Facebook的SlowFast模型是一个用于视频行为识别的深度学习框架,由Facebook AI Research(FAIR)开发。以下是对SlowFast模型的详细介绍:
1.模型结构
- 双路径网络架构:SlowFast模型采用了一种独特的双路径网络结构,包括一个慢路径(Slow pathway)和一个快路径(Fast pathway)。慢路径以较低的帧率捕捉视频中的空间信息,使用较深的网络结构来提取高级的空间特征;快路径则以较高的帧率捕捉视频中的动态信息,使用较浅的网络结构来迅速响应动态变化。
- 融合策略:在网络的某些阶段,SlowFast模型会将快路径和慢路径的特征进行融合,以强化模型的判别能力。这种融合策略有助于同时捕获视频中的精细动态和关键空间信息,提高了对复杂动作的识别能力和效率。
2.技术特点
- 双流网络:SlowFast模型结合了慢速和快速处理路径,优化了信息的捕获和处理。这种设计使得模型能够同时处理视频中的时间序列信息和空间语义信息,提高了模型的准确性和效率。
- 3D卷积:SlowFast模型利用3D卷积处理视频数据,能够更好地理解时间维度上的信息。
- 轻量级设计:尽管SlowFast模型具有两条路径,但其体量却很轻,只占总计算资源的约20%左右。这是因为第二个路径通道较少,处理空间信息的能力较差,但这些信息完全可以由第一个路径以一种简单的方式来提供。
3.应用前景
- SlowFast模型可用于安全监控、体育分析、健康监测、自动驾驶等多种场景,具有广泛的应用前景和实际价值。例如,在体育分析中,SlowFast模型可以用于识别运动员的动作和姿态;在健康监测中,它可以用于检测老年人的行为异常等。
- 此外,SlowFast模型还可以帮助公共平台寻找和删除有害视频,为视频个性化提供更好的推荐建议。
二.复现过程
1.在AutoDL上租用GPU
登入AutoDL,在算力市场界面租用GPU。我这里选择的GPU是RTX4090D*1,显存24GB,CPU内存80GB,系统盘30GB。框架选择的是Pytorch 1.10.1,Python 3.8(Ubuntu20.04),Cuda 11.3也参考了其他博客,大部分用的是Pytorch 1.8.1,但是我没有跑通。后来试了一下Pytorch 1.10.1,会有点麻烦,因为在 PyTorch 1.8.0 版本之后,有些模块已经被移除了,但后面也可以解决。

2.环境搭建
租用完成后,进入JupyterLab,打开终端。
接下来按照官网上install.md中的要求,不断pip install就好了。
这里给出的代码可以直接复制,执行完后就编译成功啦。注意,我这里并没有指定av的版本,是先安装了ffmpeg,和官网有点不太一样,但是我运行下来也没有问题。
pip install --upgrade pip
pip install 'git+https://github.com/facebookresearch/fvcore'
pip install simplejson
pip install ffmpeg
pip install av
pip install -U iopath
pip install psutil
pip install opencv-python
pip install tensorboard
pip install cython
git clone https://github.com/facebookresearch/detectron2
pip install -e detectron2
git clone https://gitee.com/qiang_sun/SlowFast.git
export PYTHONPATH=/root/SlowFast/slowfast:$PYTHONPATH
pip install pandas
pip install scikit-learn
cd SlowFast
python setup.py build develop如果在编译过程中,遇到ModuleNotFoundError: No module named 'torch._six'或者是ImportError: cannot import name 'int_classes' from 'torch._six' (/root/miniconda3/lib/python3.8/site-packages/torch/_six.py),就需要回退到旧版本的 PyTorch:
pip uninstall torch torchvision
pip install torch==1.8.1+cu111 torchvision==0.11.1+cu111看到Finished processing dependencies for slowfast==1.0就代表编译成功了
3.下载预训练模型
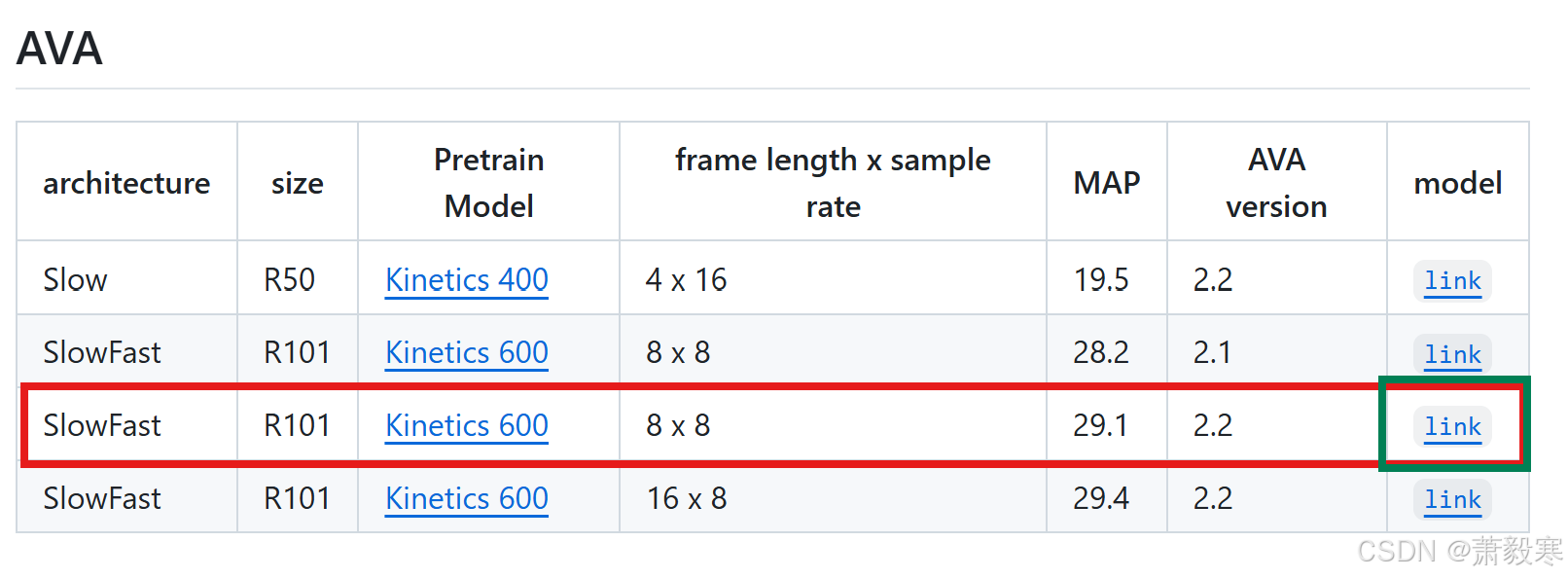
在官网上下载如下如所示的权重文件(点击link即可下载),放到/root/SlowFast/configs/AVA/c2目录下
4.修改代码
首先,需要在在/SlowFast/demo/AVA目录下新建ava.json,填入以下内容:
{"bend/bow (at the waist)": 0, "crawl": 1, "crouch/kneel": 2, "dance": 3, "fall down": 4, "get up": 5, "jump/leap": 6, "lie/sleep": 7, "martial art": 8, "run/jog": 9, "sit": 10, "stand": 11, "swim": 12, "walk": 13, "answer phone": 14, "brush teeth": 15, "carry/hold (an object)": 16, "catch (an object)": 17, "chop": 18, "climb (e.g., a mountain)": 19, "clink glass": 20, "close (e.g., a door, a box)": 21, "cook": 22, "cut": 23, "dig": 24, "dress/put on clothing": 25, "drink": 26, "drive (e.g., a car, a truck)": 27, "eat": 28, "enter": 29, "exit": 30, "extract": 31, "fishing": 32, "hit (an object)": 33, "kick (an object)": 34, "lift/pick up": 35, "listen (e.g., to music)": 36, "open (e.g., a window, a car door)": 37, "paint": 38, "play board game": 39, "play musical instrument": 40, "play with pets": 41, "point to (an object)": 42, "press": 43, "pull (an object)": 44, "push (an object)": 45, "put down": 46, "read": 47, "ride (e.g., a bike, a car, a horse)": 48, "row boat": 49, "sail boat": 50, "shoot": 51, "shovel": 52, "smoke": 53, "stir": 54, "take a photo": 55, "text on/look at a cellphone": 56, "throw": 57, "touch (an object)": 58, "turn (e.g., a screwdriver)": 59, "watch (e.g., TV)": 60, "work on a computer": 61, "write": 62, "fight/hit (a person)": 63, "give/serve (an object) to (a person)": 64, "grab (a person)": 65, "hand clap": 66, "hand shake": 67, "hand wave": 68, "hug (a person)": 69, "kick (a person)": 70, "kiss (a person)": 71, "lift (a person)": 72, "listen to (a person)": 73, "play with kids": 74, "push (another person)": 75, "sing to (e.g., self, a person, a group)": 76, "take (an object) from (a person)": 77, "talk to (e.g., self, a person, a group)": 78, "watch (a person)": 79}
接着,修改/SlowFast/demo/AVA/SLOWFAST_32x2_R101_50_50.yaml,内容改为如下:
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: "/root/SlowFast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl" #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "/root/SlowFast/demo/AVA/ava.json"
#WEBCAM: 0
#下面两个文件夹是自己建立的(VINPUT和VOUTPUT)
INPUT_VIDEO: "/root/SlowFast/VINPUT/1.mp4" #自己上传一段测试视频
OUTPUT_FILE: "/root/SlowFast/VOUTPUT/2.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
最后,由于pythrch更新后有些模块不再被使用,需要将from torch._six import int_classes as _int_classes修改为:
int_classes = int
string_classes = str
三.测试
注意需要自己上传视频至VINPUT文件夹中
cd SlowFast
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml
最后结果
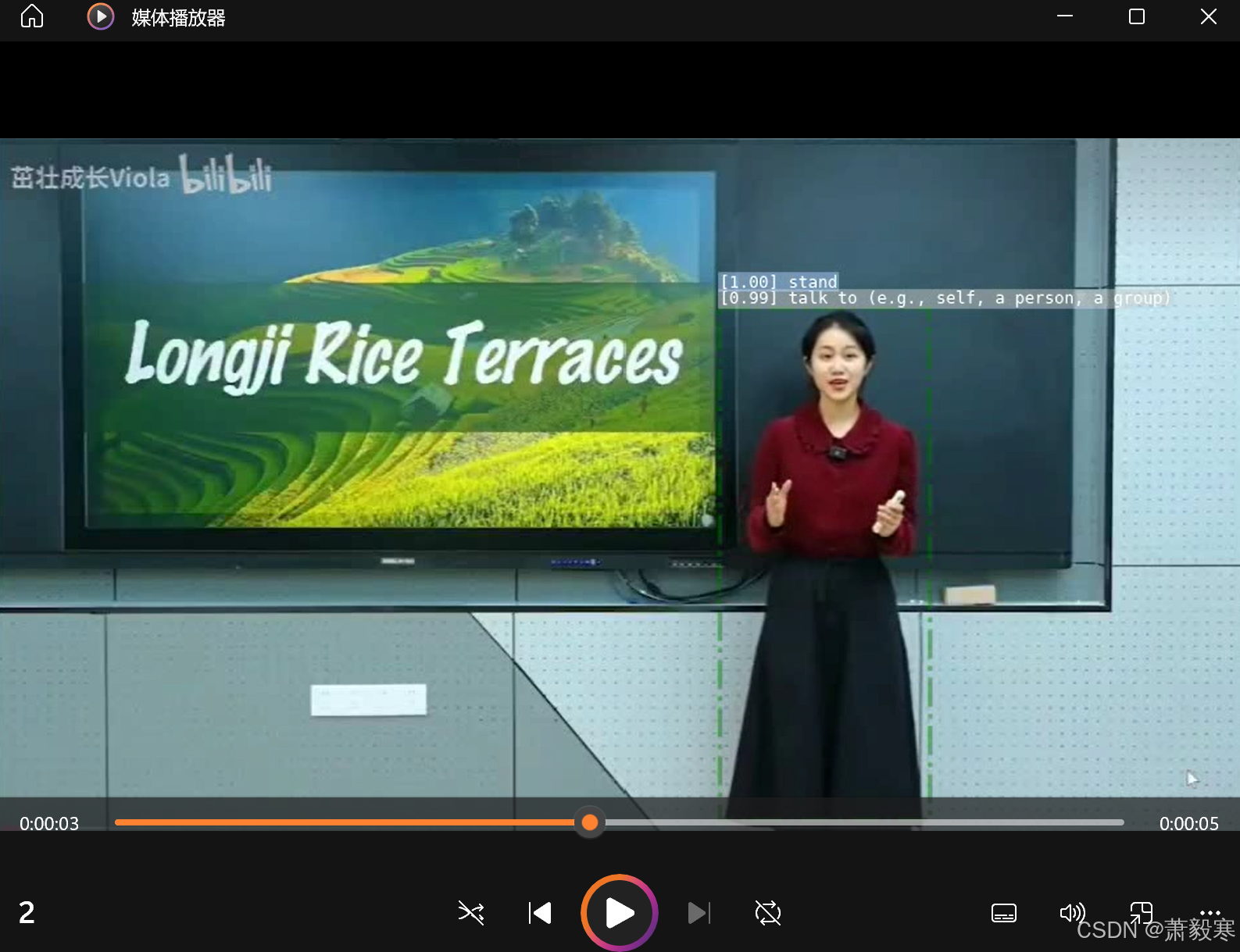
本文参考文章如下:(推荐大家也看看这位大佬的文章,我也是跟着他的操作实现的)
https://blog.csdn.net/qq_51223728/article/details/127915758


















 8156
8156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









