






前言、slowfast模型介绍
-
SlowFast 模型是一种在视频动作识别领域表现卓越的深度学习模型,其核心创新在于采用了独特的双通道架构来有效处理视频中的时空信息。
-
该模型由慢速(Slow)和快速(Fast)两条通路组成,其中慢速通路以较低的帧率对视频进行采样,通常每隔一定帧数选取一帧,重点聚焦于提取视频中的空间语义信息,捕捉物体的外观、场景的布局等相对稳定的特征;而快速通路则以高帧率采样,能够捕捉到快速的动作变化和瞬间的运动信息,但其通道容量较低,通过较少的卷积核来减少计算量。
-
为了充分融合两条通路的优势,模型引入了侧向链接机制,将快速通路的特征单向融合到慢速通路中,使得慢速通路不仅拥有丰富的空间信息,还能整合快速通路捕捉到的动态信息。
-
这种设计巧妙地平衡了计算成本与性能,让模型在处理视频动作识别任务时,能够高效且精准地识别各种复杂动作,在多个公开数据集上取得了优异的成绩,被广泛应用于视频监控、体育赛事分析、智能娱乐等多个领域。
-
简单来说,就是一种可以识别视频中各种动作的模型
-
本文历时一个多月,详细介绍了slowfast的使用,希望大家多多支持!
一、数据集视频准备
- 准备至少一个视频,各个视频的时长需为15min,如下所示,AVA数据集的时间戳为900-1800,历时15min,如需修改,可按照下图所示对参数进行修改

二、视频抽帧
需要对视频进行抽帧,分为1s抽1帧和1s抽30帧
-
1s抽一帧用于标注
-
1s抽30帧用于训练
以下是1s抽1帧的代码,路径记得自己修改。图片命名为“视频名称_帧数”(帧数固定六位数,不足用0补齐)
import os
import cv2
count = 0
def extract_frames(video_path, output_folder):
# 打开视频文件
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS) # 获取视频的帧率
frame_interval = int(fps) # 每秒抽取一帧
global count
if not os.path.exists(output_folder):
os.makedirs(output_folder)
frame_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_interval == 0:
count+=1
frame_filename = os.path.join(output_folder,
f"5_{count:06d}.jpg")
cv2.imwrite(frame_filename, frame)
print(f"Saved {frame_filename}")
frame_count += 1
cap.release()
def process_videos_in_folder(input_folder, output_folder):
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.endswith(('.mp4', '.avi', '.mov', '.mkv')): # 支持的视频格式
video_path = os.path.join(root, file)
print(f"Processing {video_path}...")
extract_frames(video_path, output_folder)
if name == "__main__":
input_folder = r"D:\AI+edu\teacher dataset\5" # 输入视频文件夹路径
output_folder = r"D:\AI+edu\data\ava\labelframes\5" # 输出图片文件夹路径
process_videos_in_folder(input_folder, output_folder)抽帧完后每个视频分别存入命名为“1、2、3...”的文件夹,这些文件夹都在labelframes文件夹下,之后1s抽30帧的均存在rawframes文件夹中。
labelframes和rawframes文件夹都在ava文件夹下
以下是1s抽30帧的代码,路径记得自己修改。图片命名为“视频名称_帧数”(帧数固定六位数,不足用0补齐)
import os
import cv2
count = 1
def extract_frames(video_path, output_folder, fps=30):
# 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频文件: {video_path}")
return
# 获取视频的帧率
video_fps = cap.get(cv2.CAP_PROP_FPS)
if video_fps <= 0:
print(f"视频文件 {video_path} 的帧率无效,使用默认帧率 30 fps")
video_fps = 30 # 设置默认帧率
frame_interval = int(video_fps / fps) # 计算抽帧间隔
if frame_interval <= 0:
frame_interval = 1 # 确保 frame_interval 至少为 1
frame_count = 0
saved_frame_count = 0
global count
while True:
ret, frame = cap.read()
if not ret:
break
# 每隔frame_interval帧保存一次
if frame_count % frame_interval == 0:
saved_frame_count += 1
frame_name = f"5_{count:06d}.jpg"
frame_path = os.path.join(output_folder, frame_name)
cv2.imwrite(frame_path, frame)
print(f"保存帧: {frame_path}")
count += 1
frame_count += 1
cap.release()
print(f"抽帧完成,共保存了 {saved_frame_count} 帧")
def process_folder(input_folder, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for filename in os.listdir(input_folder):
if filename.endswith(".mp4") or filename.endswith(".avi"): # 支持常见的视频格式
video_path = os.path.join(input_folder, filename)
extract_frames(video_path, output_folder)
if name == "__main__":
input_folder = r"D:\AI+edu\teacher dataset\5" # 替换为你的视频文件夹路径
output_folder = r"D:\AI+edu\data\ava\rawframes\5" # 替换为保存抽帧图片的文件夹路径
process_folder(input_folder, output_folder)文件结构如下图所示:
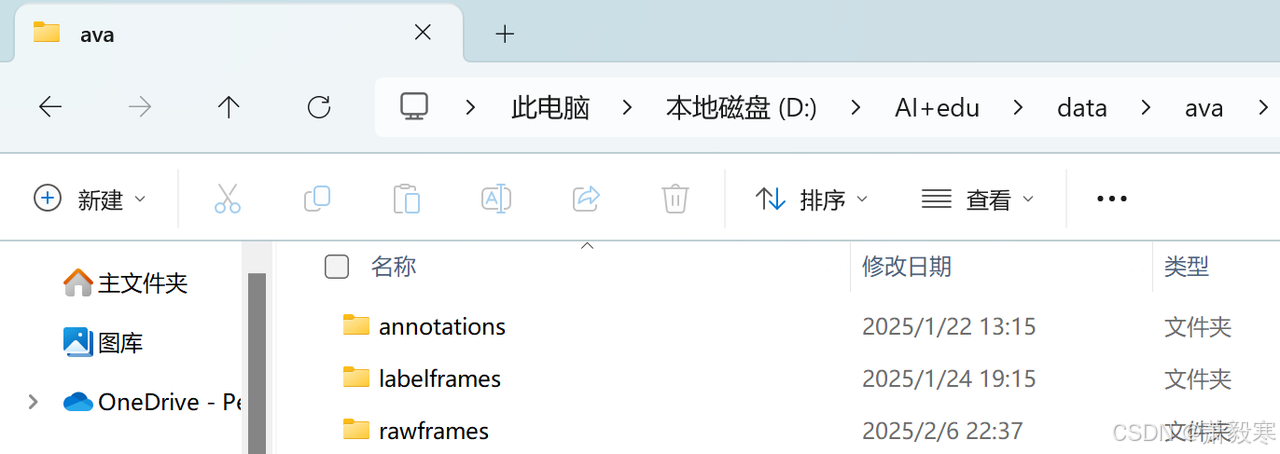
三、标注数据集
用VIA进行标注(我使用的版本是via-3.0.11),步骤如下:
-
点击下载地址进行下载:https://gitlab.com/vgg/via/tree/master
-
下载后打开文件夹,点击via_image_annotator.html打开

-
进入网页后,点击加号图标,将labelframes下的图片全部导入
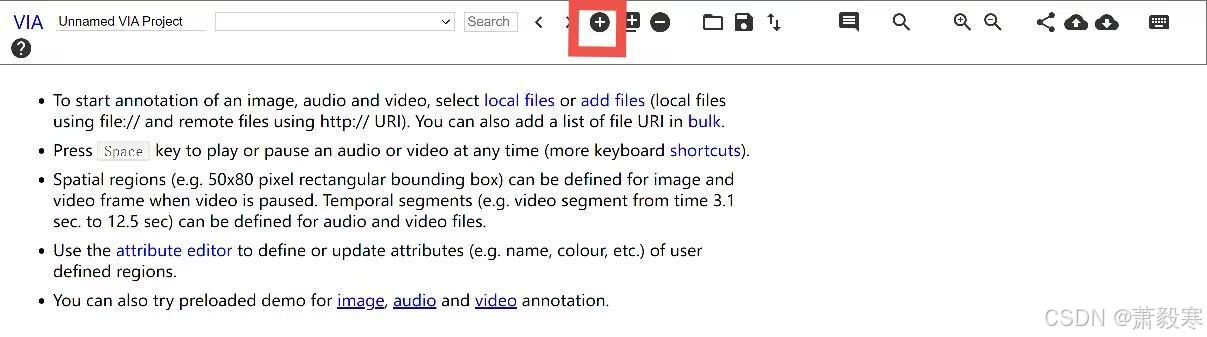
-
点击下图所示的图标,创建一个attribute
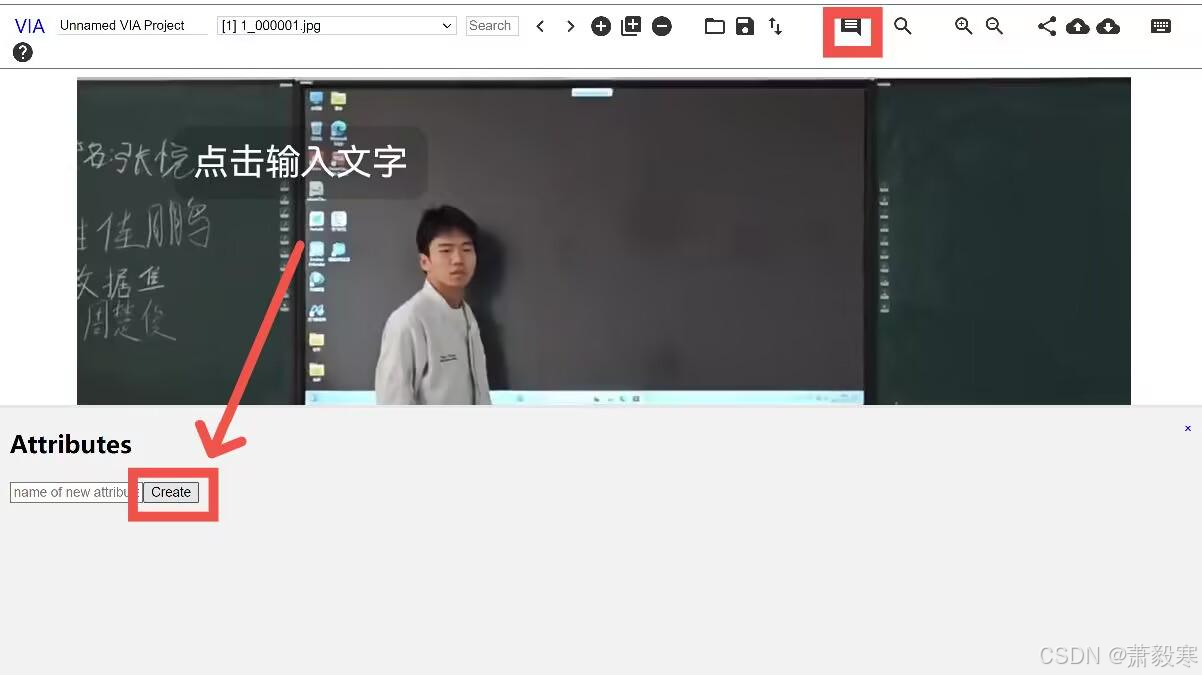
-
anchor选择第二项,input type选择checkbox,在options中定义人的四个行为:stand,sit,talk to,listen,用英文状态下的逗号分割开,然后preview中勾选四个行为
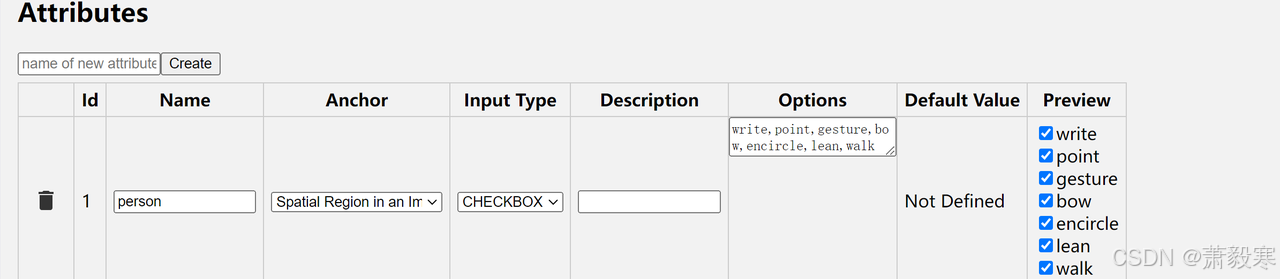
-
开始标注图片,框选图片中的人,然后点击矩形框,勾选你认为人出现的行为,如下图所示:
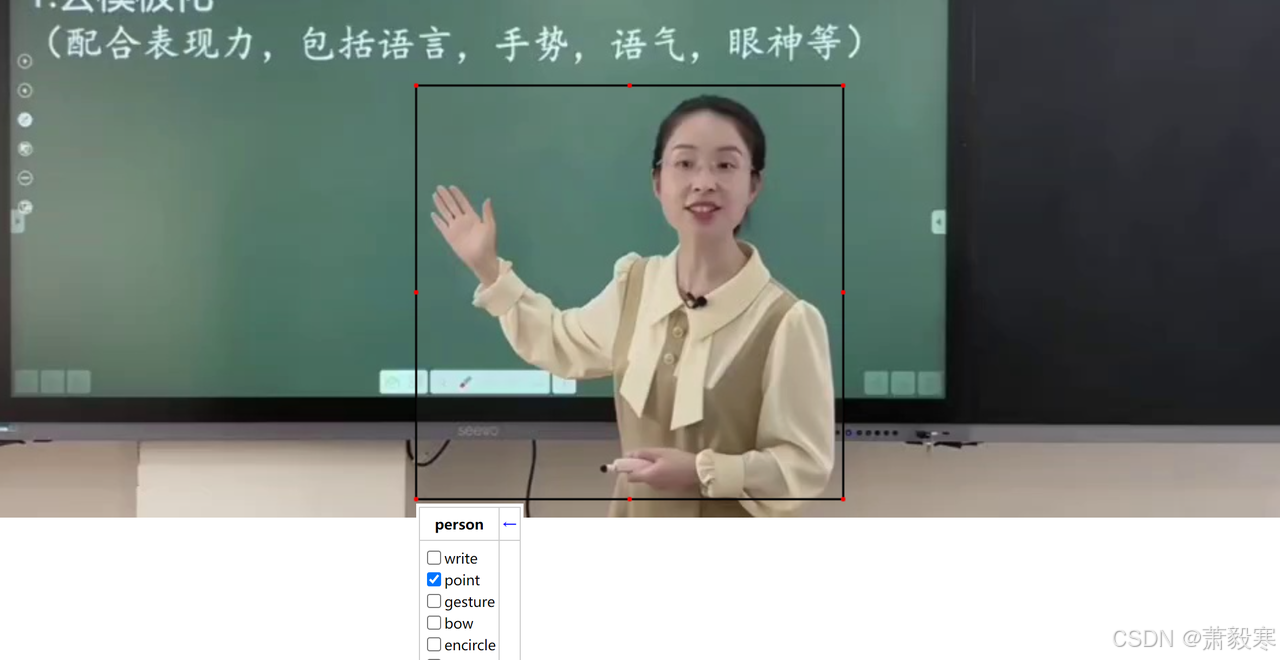
-
全部标注完成后,点击如下图所示图标:
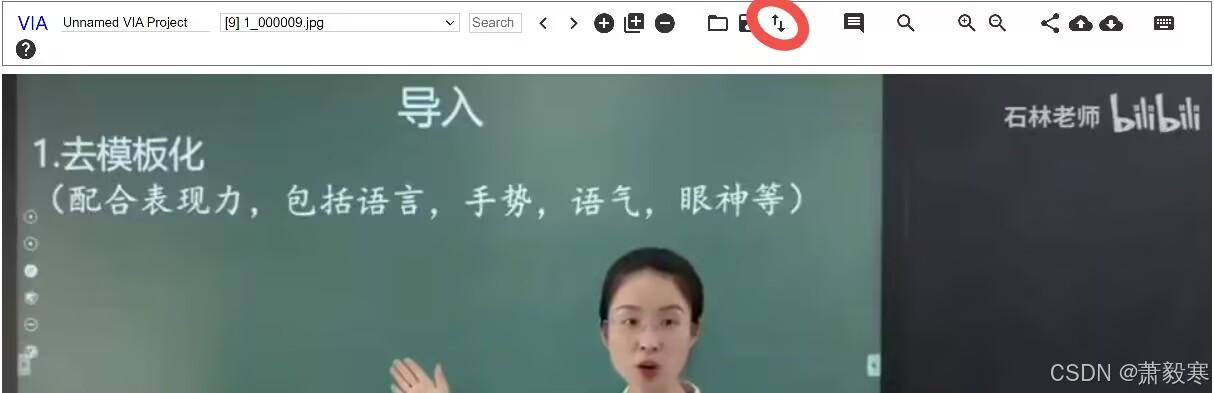
保持默认选项,点击“Export”导出csv文件,注意,该csv文件最好不要用Excel打开进行编辑!!!
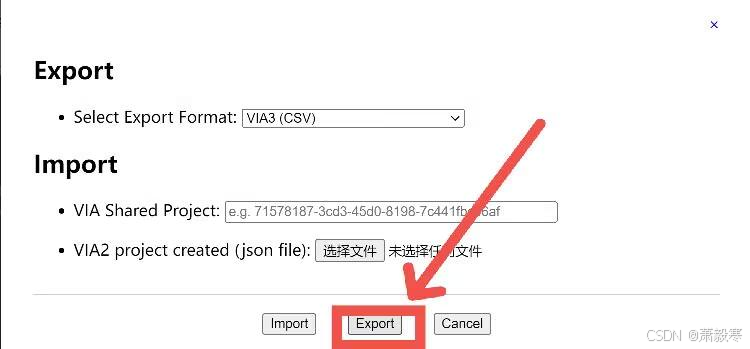
此时会得到一个csv文件
四、via数据集转为slowfast格式
-
slowfast数据集要求ava格式,同时需要提供pkl文件,使用以下python脚本可一键生成全部所需配置文件(注意这里ava版本是2.1)
"""
Theme:ava format data transformer
author:Hongbo Jiang
time:2022/3/14/1:51:51
description:
这是一个数据格式转换器,根据mmaction2的ava数据格式转换规则将来自网站:
https://www.robots.ox.ac.uk/~vgg/software/via/app/via_video_annotator.html
的、标注好的、视频理解类型的csv文件转换为mmaction2指定的数据格式。
转换规则:
# AVA Annotation Explained
In this section, we explain the annotation format of AVA in details:
```
mmaction2
├── data
│ ├── ava
│ │ ├── annotations
│ │ | ├── ava_dense_proposals_train.FAIR.recall_93.9.pkl
│ │ | ├── ava_dense_proposals_val.FAIR.recall_93.9.pkl
│ │ | ├── ava_dense_proposals_test.FAIR.recall_93.9.pkl
│ │ | ├── ava_train_v2.1.csv
│ │ | ├── ava_val_v2.1.csv
│ │ | ├── ava_train_excluded_timestamps_v2.1.csv
│ │ | ├── ava_val_excluded_timestamps_v2.1.csv
│ │ | ├── ava_action_list_v2.1.pbtxt
```
## The proposals generated by human detectors
In the annotation folder, ava_dense_proposals_[train/val/test].FAIR.recall_93.9.pkl are human proposals generated by a human detector. They are used in training, validation and testing respectively. Take ava_dense_proposals_train.FAIR.recall_93.9.pkl as an example. It is a dictionary of size 203626. The key consists of the videoID and the timestamp. For example, the key -5KQ66BBWC4,0902 means the values are the detection results for the frame at the $$902_{nd}$$ second in the video -5KQ66BBWC4. The values in the dictionary are numpy arrays with shape $$N \times 5$$ , $$N$$ is the number of detected human bounding boxes in the corresponding frame. The format of bounding box is $$[x_1, y_1, x_2, y_2, score], 0 \le x_1, y_1, x_2, w_2, score \le 1$$. $$(x_1, y_1)$$ indicates the top-left corner of the bounding box, $$(x_2, y_2)$$ indicates the bottom-right corner of the bounding box; $$(0, 0)$$ indicates the top-left corner of the image, while $$(1, 1)$$ indicates the bottom-right corner of the image.
## The ground-truth labels for spatio-temporal action detection
In the annotation folder, ava_[train/val]_v[2.1/2.2].csv are ground-truth labels for spatio-temporal action detection, which are used during training & validation. Take ava_train_v2.1.csv as an example, it is a csv file with 837318 lines, each line is the annotation for a human instance in one frame. For example, the first line in ava_train_v2.1.csv is '-5KQ66BBWC4,0902,0.077,0.151,0.283,0.811,80,1': the first two items -5KQ66BBWC4 and 0902 indicate that it corresponds to the $$902_{nd}$$ second in the video -5KQ66BBWC4. The next four items ($$[0.077(x_1), 0.151(y_1), 0.283(x_2), 0.811(y_2)]$$) indicates the location of the bounding box, the bbox format is the same as human proposals. The next item 80 is the action label. The last item 1 is the ID of this bounding box.
## Excluded timestamps
ava_[train/val]_excludes_timestamps_v[2.1/2.2].csv contains excluded timestamps which are not used during training or validation. The format is video_id, second_idx .
## Label map
ava_action_list_v[2.1/2.2]_for_activitynet_[2018/2019].pbtxt contains the label map of the AVA dataset, which maps the action name to the label index.
"""
import csv
import os
from distutils.log import info
import pickle
from matplotlib.pyplot import contour, show
import numpy as np
import cv2
from sklearn.utils import shuffle
def transformer(origin_csv_path, frame_image_dir,
train_output_pkl_path, train_output_csv_path,
valid_output_pkl_path, valid_output_csv_path,
exclude_train_output_csv_path, exclude_valid_output_csv_path,
out_action_list, out_labelmap_path, dataset_percent=0.8):
"""
输入:
origin_csv_path:从网站导出的csv文件路径。
frame_image_dir:以"视频名_第n秒.jpg"格式命名的图片,这些图片是通过逐秒读取的。
output_pkl_path:输出pkl文件路径
output_csv_path:输出csv文件路径
out_labelmap_path:输出labelmap.txt文件路径
dataset_percent:训练集和测试集分割
输出:无
"""
# -----------------------------------------------------------------------------------------------
get_label_map(origin_csv_path, out_action_list, out_labelmap_path)
-----------------------------------------------------------------------------------------------
information_array = [[], [], []]
# 读取输入csv文件的位置信息段落
with open(origin_csv_path, 'r') as csvfile:
count = 0
content = csv.reader(csvfile)
for line in content:
if count >= 10:
try:
frame_image_name = eval(line[1])[0] str
location_info = eval(line[4])[1:] list
action_list_str = line[5]
if action_list_str and action_list_str != 'None':
action_list = list(eval(action_list_str).values())[0].split(',')
action_list = [int(x) for x in action_list]
else:
action_list = []
except Exception as e:
print(f"Error processing line {line}: {e}")
continue
information_array[0].append(frame_image_name)
information_array[1].append(location_info)
information_array[2].append(action_list)
count += 1
# 将:对应帧图片名字、物体位置信息、动作种类信息汇总为一个信息数组
information_array = np.array(information_array, dtype=object).transpose()
information_array = np.array(information_array)
# -----------------------------------------------------------------------------------------------
num_train = int(dataset_percent * len(information_array))
train_info_array = information_array[:num_train]
valid_info_array = information_array[num_train:]
get_pkl_csv(train_info_array, train_output_pkl_path, train_output_csv_path, exclude_train_output_csv_path, frame_image_dir)
get_pkl_csv(valid_info_array, valid_output_pkl_path, valid_output_csv_path, exclude_valid_output_csv_path, frame_image_dir)
def get_label_map(origin_csv_path, out_action_list, out_labelmap_path):
classes_list = 0
classes_content = ""
labelmap_strings = ""
# 提取出csv中的第9行的行为下标
with open(origin_csv_path, 'r') as csvfile:
count = 0
content = csv.reader(csvfile)
for line in content:
if count == 8:
classes_list = line
break
count += 1
# 截取种类字典段落
st = 0
ed = 0
for i in range(len(classes_list)):
if classes_list[i].startswith('options'):
st = i
if classes_list[i].startswith('default_option_id'):
ed = i
for i in range(st, ed):
if i == st:
classes_content = classes_content + classes_list[i][len('options:'):] + ','
else:
classes_content = classes_content + classes_list[i] + ','
classes_dict = eval(classes_content)[0]
# 写入labelmap.txt文件
with open(out_action_list, 'w') as f: # 写入action_list文件
for v, k in classes_dict.items():
labelmap_strings = labelmap_strings + "label {{\n name: \"{}\"\n label_id: {}\n label_type: PERSON_MOVEMENT\n}}\n".format(k, int(v)+1)
f.write(labelmap_strings)
labelmap_strings = ""
with open(out_labelmap_path, 'w') as f: # 写入label_map文件
for v, k in classes_dict.items():
labelmap_strings = labelmap_strings + "{}: {}\n".format(int(v)+1, k)
f.write(labelmap_strings)
def get_pkl_csv(information_array, output_pkl_path, output_csv_path, exclude_output_csv_path, frame_image_dir):
# 在遍历之前需要对我们的字典进行初始化
pkl_data = dict() # 存储pkl键值对信的字典(其值为普通list)
csv_data = [] # 存储导出csv文件的2d数组
read_data = {} # 存储pkl键值对的字典(方便字典的值化为numpy数组)
for i in range(len(information_array)):
img_name = information_array[i][0]
-------------------------------------------------------------------------------------------
video_name, frame_name = '_'.join(img_name.split('_')[:-1]), format(int(img_name.split('_')[-1][:-4]), '04d') # 我的格式是"视频名称_帧名称",格式不同可自行更改
-------------------------------------------------------------------------------------------
pkl_key = video_name + ',' + frame_name
pkl_data[pkl_key] = []
# 遍历所有的图片进行信息读取并写入pkl数据
for i in range(len(information_array)):
img_name = information_array[i][0]
-------------------------------------------------------------------------------------------
video_name, frame_name = '_'.join(img_name.split('_')[:-1]), str(int(img_name.split('_')[-1][:-4])) # 我的格式是"视频名称_帧名称",格式不同可自行更改
-------------------------------------------------------------------------------------------
imgpath = frame_image_dir + '/' + img_name
location_list = information_array[i][1]
action_info = information_array[i][2]
image_array = cv2.imread(imgpath)
h, w = image_array.shape[:2]
# 进行归一化
location_list[0] /= w
location_list[1] /= h
location_list[2] /= w
location_list[3] /= h
location_list[2] = location_list[2]+location_list[0]
location_list[3] = location_list[3]+location_list[1]
# 置信度置为1
# 组装pkl数据
for kind_idx in action_info:
csv_info = [video_name, frame_name, *location_list, kind_idx+1, 1]
csv_data.append(csv_info)
location_list = location_list [1]
pkl_key = video_name + ',' + format(int(frame_name), '04d')
pkl_value = location_list
pkl_data[pkl_key].append(pkl_value)
for k, v in pkl_data.items():
read_data[k] = np.array(v)
with open(output_pkl_path, 'wb') as f: # 写入pkl文件
pickle.dump(read_data, f)
with open(output_csv_path, 'w', newline='') as f: # 写入csv文件, 设定参数newline=''可以不换行。
f_csv = csv.writer(f)
f_csv.writerows(csv_data)
with open(exclude_output_csv_path, 'w', newline='') as f: # 写入csv文件, 设定参数newline=''可以不换行。
f_csv = csv.writer(f)
f_csv.writerows([])
def showpkl(pkl_path):
with open(pkl_path, 'rb') as f:
content = pickle.load(f)
return content
def showcsv(csv_path):
output = []
with open(csv_path, 'r') as f:
content = csv.reader(f)
for line in content:
output.append(line)
return output
def showlabelmap(labelmap_path):
classes_dict = dict()
with open(labelmap_path, 'r') as f:
content = (f.read().split('\n'))[:-1]
for item in content:
mid_idx = -1
for i in range(len(item)):
if item[i] == ":":
mid_idx = i
classes_dict[item[:mid_idx]] = item[mid_idx + 1:]
return classes_dict
os.makedirs('./ava/annotations', exist_ok=True)
transformer("./Unnamed-VIA Project13Jan2025_20h10m01s_export.csv", './ava/labelframes',
'./ava/annotations/ava_dense_proposals_train.FAIR.recall_93.9.pkl', './ava/annotations/ava_train_v2.1.csv',
'./ava/annotations/ava_dense_proposals_val.FAIR.recall_93.9.pkl', './ava/annotations/ava_val_v2.1.csv',
'./ava/annotations/ava_train_excluded_timestamps_v2.1.csv', './ava/annotations/ava_val_excluded_timestamps_v2.1.csv',
'./ava/annotations/ava_action_list_v2.1.pbtxt', './ava/annotations/labelmap.txt', 0.9)
print(showpkl('./ava/annotations/ava_dense_proposals_train.FAIR.recall_93.9.pkl'))
print(showcsv('././ava/annotations/ava_train_v2.1.csv'))
print(showlabelmap('././ava/annotations/labelmap.txt')) 这里讲一个参数data_percent用于切分训练集和验证集,可自行修改
五、slowfast环境部署
这里用的是MMAction2 里的 SlowFast 模型(经杨帆老师修改调整)。我是在autodl上租的GPU拿来训练,显卡和pytorch版本选择如下图:

-
以下是在autodl上部署的代码:
git clone https://gitee.com/YFwinston/mmaction2_YF.git pip install mmcv-full==1.3.17 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html pip install opencv-python-headless==4.1.2.30 pip install moviepy cd mmaction2_YF pip install -r requirements/build.txt pip install -v -e . mkdir -p ./data/ava cd .. git clone https://gitee.com/YFwinston/mmdetection.git cd mmdetection pip install -r requirements/build.txt pip install -v -e . cd ../mmaction2_YF wget https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth -P ./Checkpionts/mmdetection/ wget https://download.openmmlab.com/mmaction/recognition/slowfast/slowfast_r50_8x8x1_256e_kinetics400_rgb/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth -P ./Checkpionts/mmaction/ -
配置文件
在 /mmaction2_YF/configs/detection/ava/下创建 my_slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py
# model setting
model = dict(
type='FastRCNN',
backbone=dict(
type='ResNet3dSlowFast',
pretrained=None,
resample_rate=8,
speed_ratio=8,
channel_ratio=8,
slow_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=True,
conv1_kernel=(1, 7, 7),
dilations=(1, 1, 1, 1),
conv1_stride_t=1,
pool1_stride_t=1,
inflate=(0, 0, 1, 1),
spatial_strides=(1, 2, 2, 1)),
fast_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=False,
base_channels=8,
conv1_kernel=(5, 7, 7),
conv1_stride_t=1,
pool1_stride_t=1,
spatial_strides=(1, 2, 2, 1))),
roi_head=dict(
type='AVARoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor3D',
roi_layer_type='RoIAlign',
output_size=8,
with_temporal_pool=True),
bbox_head=dict(
type='BBoxHeadAVA',
in_channels=2304,
num_classes=81,
multilabel=True,
dropout_ratio=0.5)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
type='MaxIoUAssignerAVA',
pos_iou_thr=0.9,
neg_iou_thr=0.9,
min_pos_iou=0.9),
sampler=dict(
type='RandomSampler',
num=32,
pos_fraction=1,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=1.0,
debug=False)),
test_cfg=dict(rcnn=dict(action_thr=0.002)))
dataset_type = 'AVADataset'
data_root = '/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/rawframes'
anno_root = '/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/annotations'
#ann_file_train = f'{anno_root}/ava_train_v2.1.csv'
ann_file_train = f'{anno_root}/train.csv'
#ann_file_val = f'{anno_root}/ava_val_v2.1.csv'
ann_file_val = f'{anno_root}/val.csv'
#exclude_file_train = f'{anno_root}/ava_train_excluded_timestamps_v2.1.csv'
#exclude_file_val = f'{anno_root}/ava_val_excluded_timestamps_v2.1.csv'
exclude_file_train = f'{anno_root}/train_excluded_timestamps.csv'
exclude_file_val = f'{anno_root}/val_excluded_timestamps.csv'
#label_file = f'{anno_root}/ava_action_list_v2.1_for_activitynet_2018.pbtxt'
label_file = f'{anno_root}/action_list.pbtxt'
proposal_file_train = (f'{anno_root}/dense_proposals_train.pkl')
proposal_file_val = f'{anno_root}/dense_proposals_val.pkl'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
train_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='RandomRescale', scale_range=(256, 320)),
dict(type='RandomCrop', size=256),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
dict(
type='ToDataContainer',
fields=[
dict(key=['proposals', 'gt_bboxes', 'gt_labels'], stack=False)
]),
dict(
type='Collect',
keys=['img', 'proposals', 'gt_bboxes', 'gt_labels'],
meta_keys=['scores', 'entity_ids'])
]
# The testing is w/o. any cropping / flipping
val_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals']),
dict(type='ToDataContainer', fields=[dict(key='proposals', stack=False)]),
dict(
type='Collect',
keys=['img', 'proposals'],
meta_keys=['scores', 'img_shape'],
nested=True)
]
data = dict(
#videos_per_gpu=9,
#workers_per_gpu=2,
videos_per_gpu=5,
workers_per_gpu=2,
val_dataloader=dict(videos_per_gpu=1),
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type=dataset_type,
ann_file=ann_file_train,
exclude_file=exclude_file_train,
pipeline=train_pipeline,
label_file=label_file,
proposal_file=proposal_file_train,
person_det_score_thr=0.9,
data_prefix=data_root,
start_index=1,),
val=dict(
type=dataset_type,
ann_file=ann_file_val,
exclude_file=exclude_file_val,
pipeline=val_pipeline,
label_file=label_file,
proposal_file=proposal_file_val,
person_det_score_thr=0.9,
data_prefix=data_root,
start_index=1,))
data['test'] = data['val']
#optimizer = dict(type='SGD', lr=0.1125, momentum=0.9, weight_decay=0.00001)
optimizer = dict(type='SGD', lr=0.0125, momentum=0.9, weight_decay=0.00001)
# this lr is used for 8 gpus
optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
step=[10, 15],
warmup='linear',
warmup_by_epoch=True,
warmup_iters=5,
warmup_ratio=0.1)
#total_epochs = 20
total_epochs = 100
checkpoint_config = dict(interval=1)
workflow = [('train', 1)]
evaluation = dict(interval=1, save_best='mAP@0.5IOU')
log_config = dict(
interval=20, hooks=[
dict(type='TextLoggerHook'),
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = ('./work_dirs/ava/'
'slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb')
load_from = ('https://download.openmmlab.com/mmaction/recognition/slowfast/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb_20200704-bcde7ed7.pth')
resume_from = None
find_unused_parameters = False
以上配置文件需要注意以下四点:
-
文件的路径
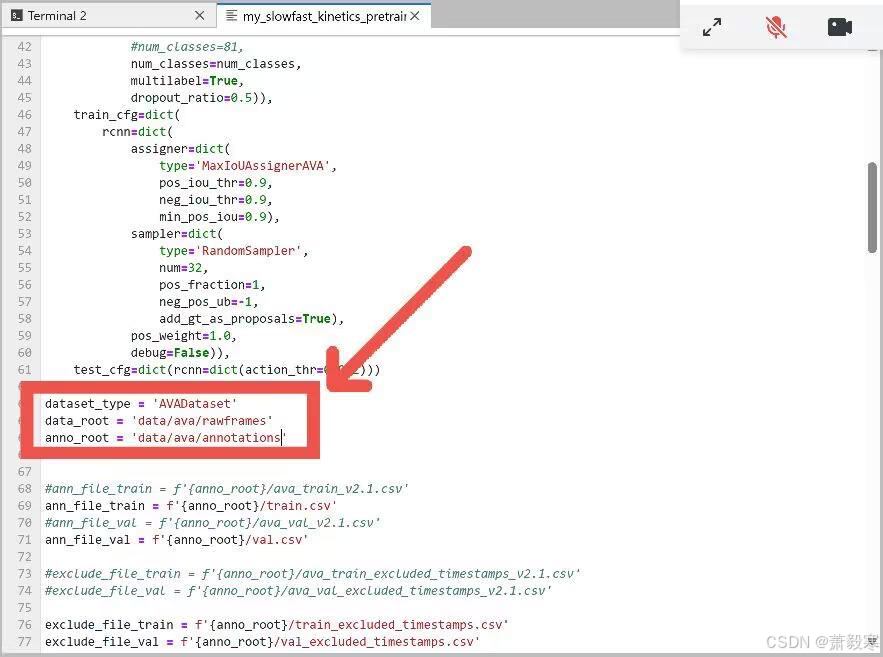
-
num_classes的值等于行为数+1,修改时需要修改以下几处:
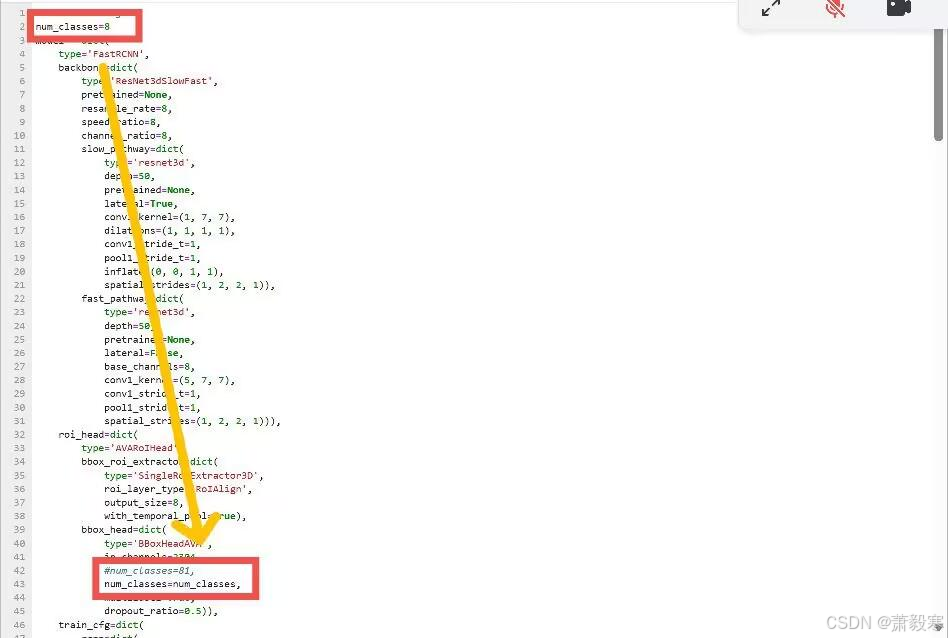
在data中也要加入num_classes,因为默认的是80,不添加的话,训练时会出现维度不匹配的情况:
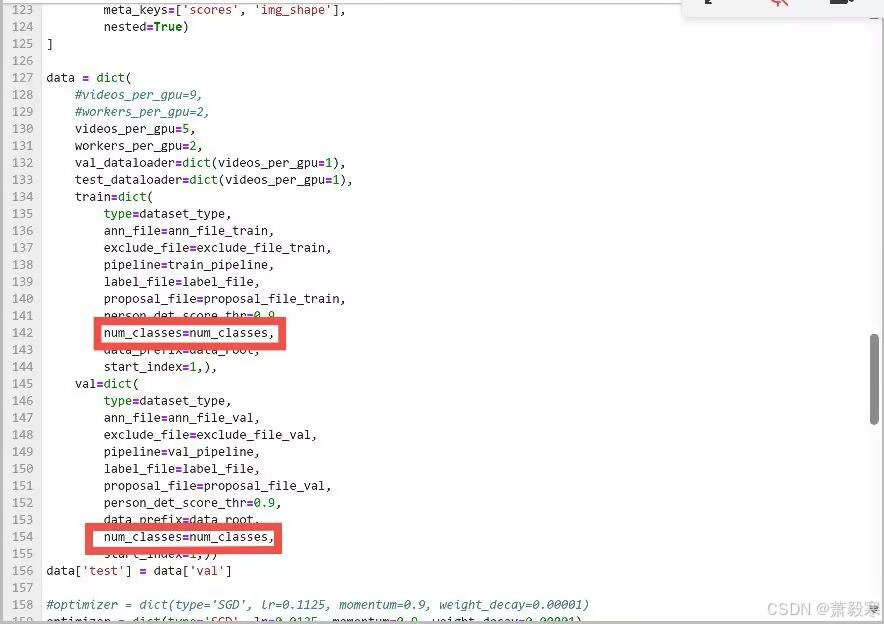
-
annotations下的文件名需要修改
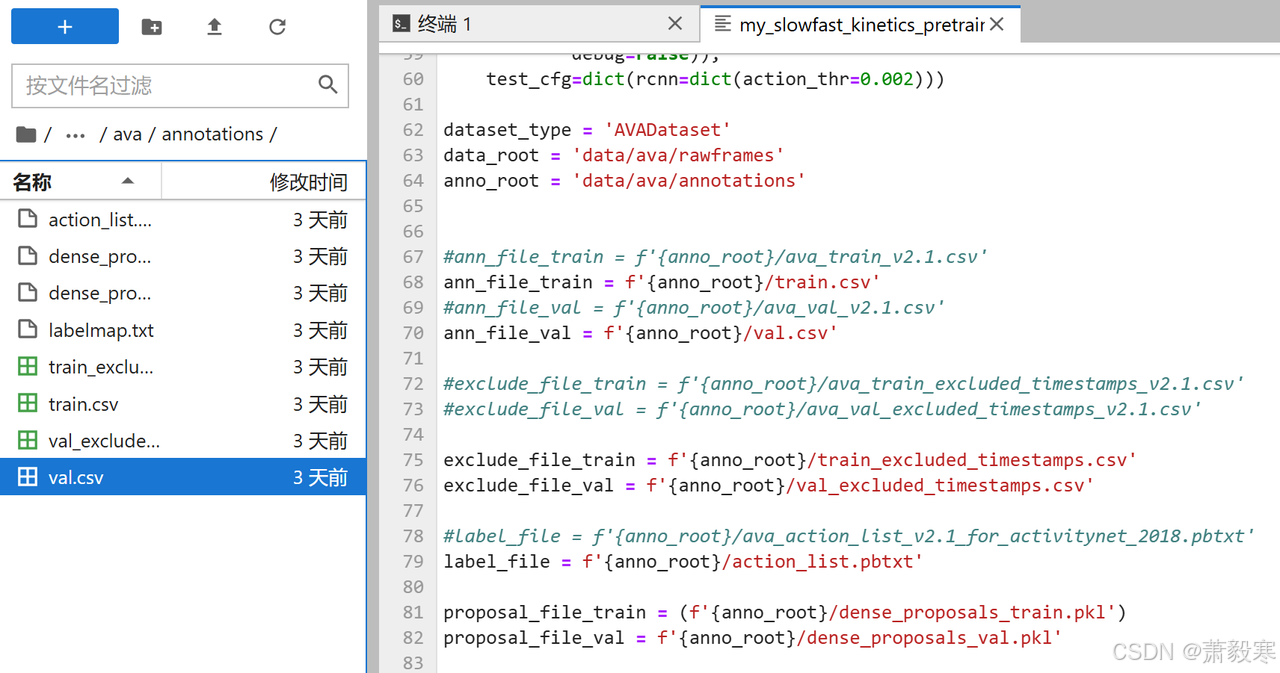
根据代码中的文件名进行修改
-
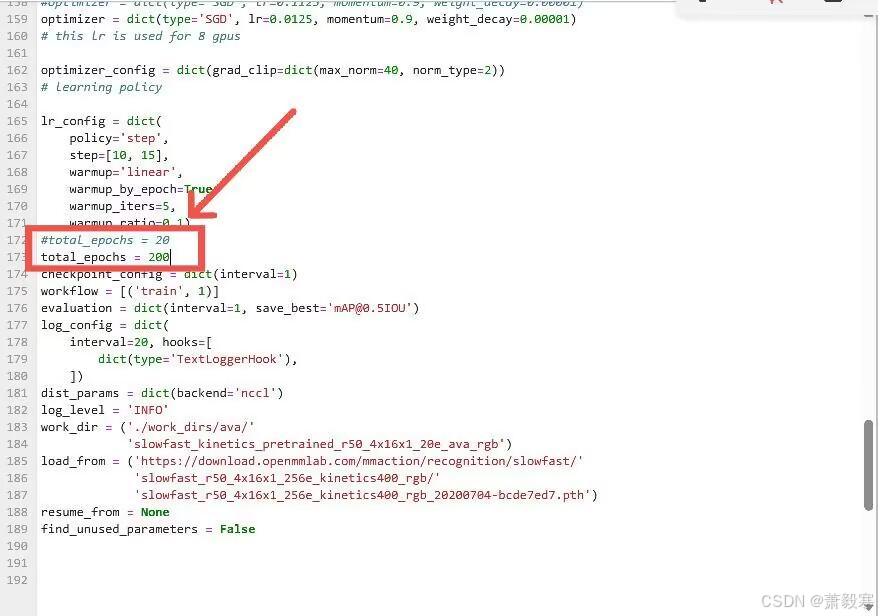
训练轮数修改
修改total_epochs的值为合适即可(默认为100)
六、常见问题及解决方案
-
opencv的版本问题
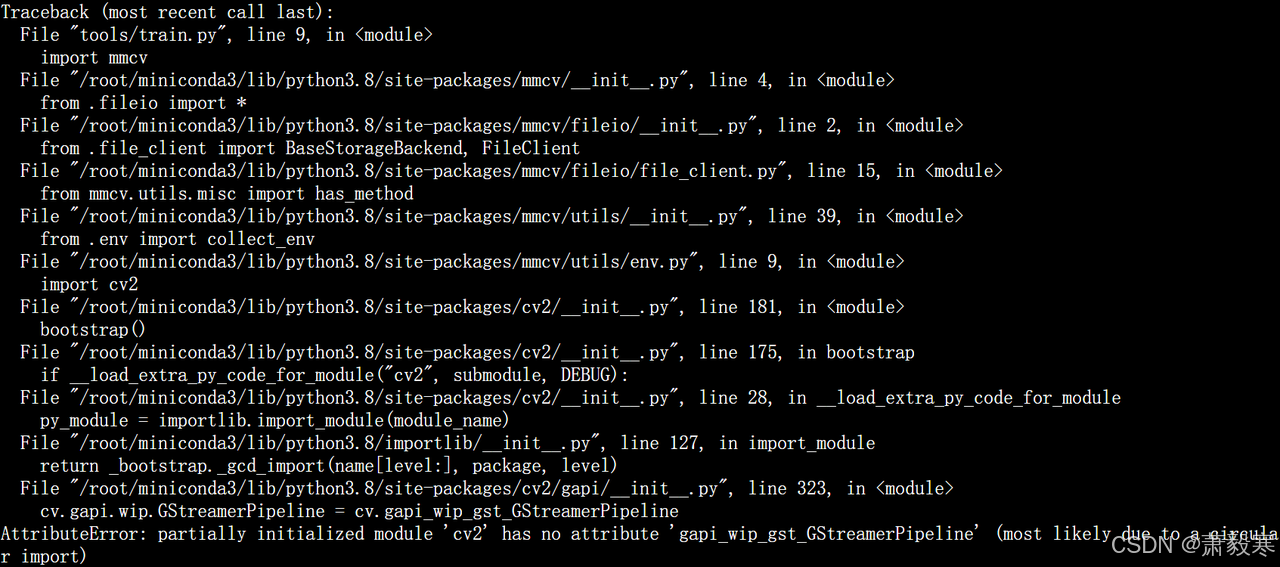
在终端输入pip list,找到下图的三个库,需要对其统一版本,统一成4.1.2.30

pip install opencv-contrib-python==4.1.2.30
pip install opencv-python==4.1.2.30-
yapf版本问题
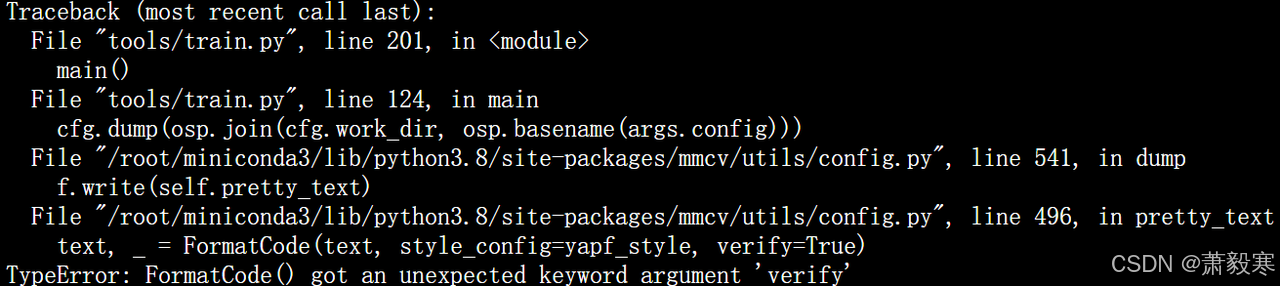
yapf版本过高,执行如下代码即可:
pip install yapf==0.31.0-
rawframes图片名称修改
在取名上,裁剪的视频帧存在与训练不匹配的问题,需要修改图片名称 例如: 原本的名字:rawframes/1/1_000001.jpg 目标名字:rawframes/1/img_00001.jpg
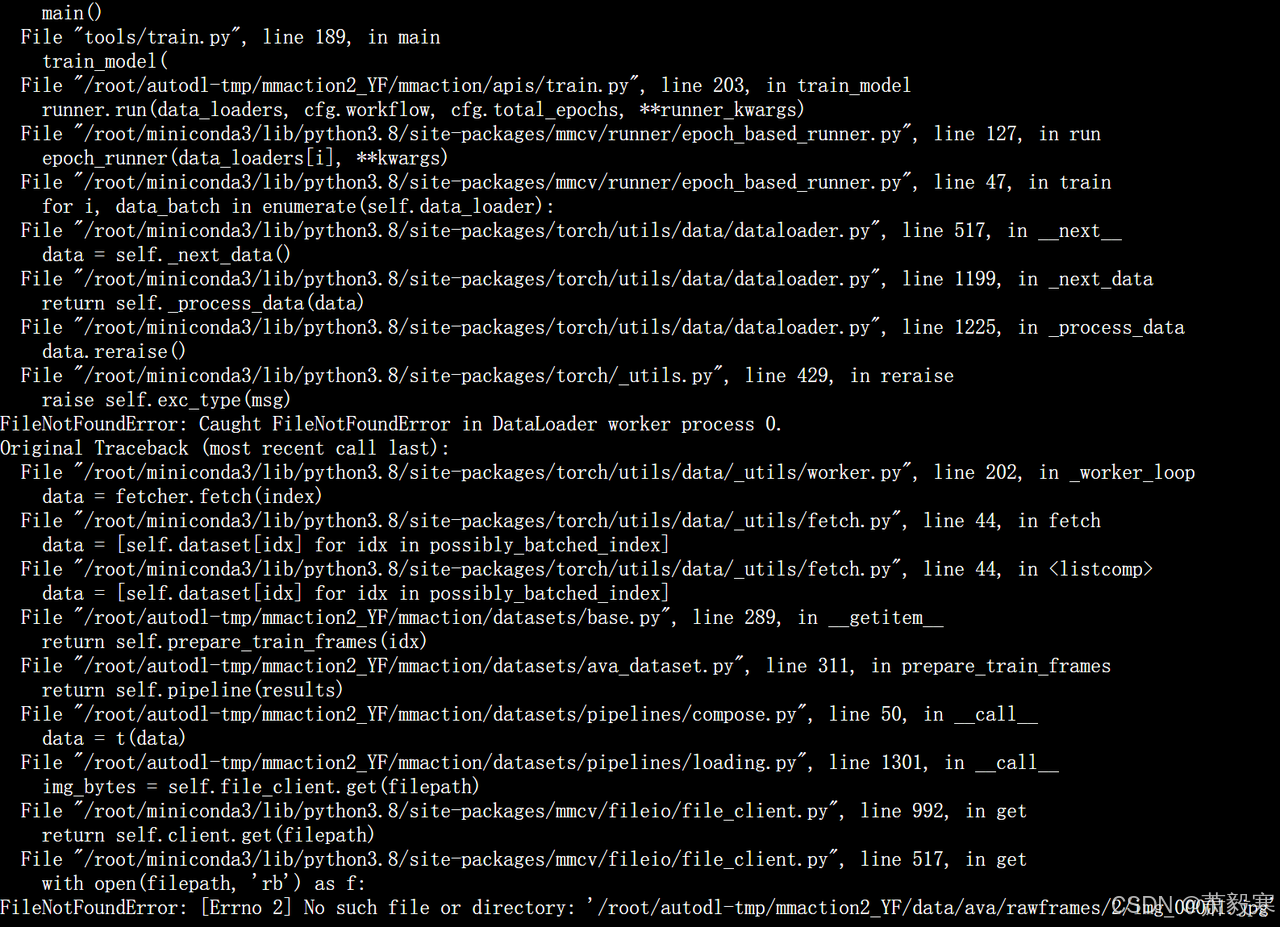
以下代码用于修改图片名称,注意修改路径
import os
count = 1
def rename_images(folder_path, prefix="image_"):
# 获取文件夹中所有文件的列表
files = os.listdir(folder_path)
# 过滤出图片文件(可以根据需要添加更多图片扩展名)
image_extensions = ['.jpg', '.jpeg', '.png', '.gif']
image_files = [f for f in files if any(f.lower().endswith(ext) for ext in image_extensions)]
global count
# 按文件在文件夹中的顺序重命名图片
for i, image in enumerate(image_files):
# 获取文件扩展名
file_extension = os.path.splitext(image)[1]
# 生成新的文件名
new_name = f"img_{count:05d}.jpg"
count += 1
# 构建旧文件的完整路径
old_path = os.path.join(folder_path, image)
# 构建新文件的完整路径
new_path = os.path.join(folder_path, new_name)
# 重命名文件
os.rename(old_path, new_path)
print(f"Renamed {image} to {new_name}")
if __name__ == "__main__":
# 指定要处理的文件夹路径
folder_path = "mmaction2_YF/data/ava/rawframes/5"
# 调用重命名函数
rename_images(folder_path)
-
GPU内存不足, RuntimeError: CUDA out of memory.
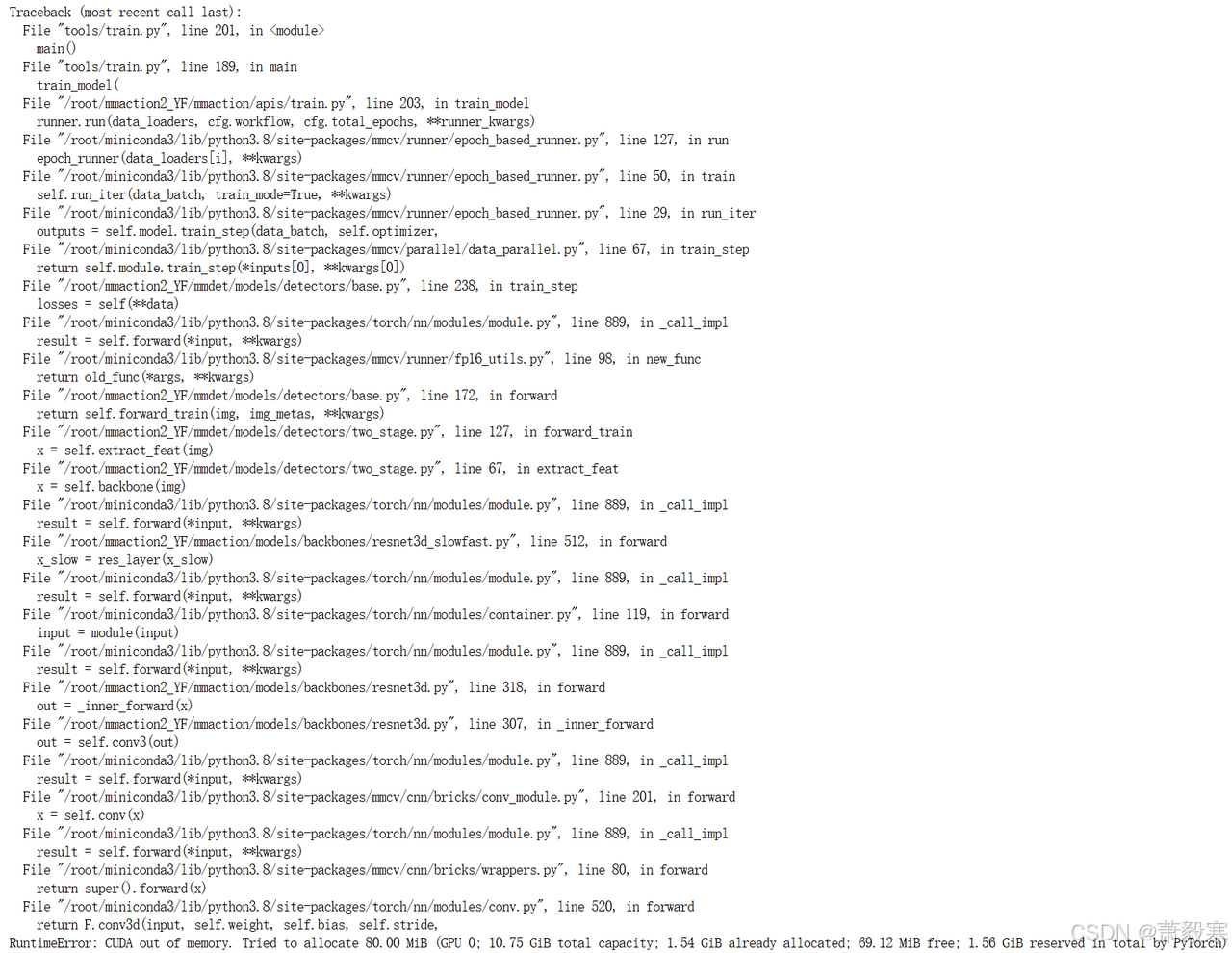
在train.py中加入以下代码即可解决
import torch
gc gc.collect()
torch.cuda.empty_cache()
七、训练
运行以下代码:
cd mmaction2_YF
python tools/train.py configs/detection/ava/my_slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py --validate八、测试
运行以下代码:
cd mmaction2_YF
python demo/demo_spatiotemporal_det.py --config configs/detection/ava/my_slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py --checkpoint work_dirs/ava/slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb/best_mAP@0.5IOU_epoch_10.pth --det-config demo/faster_rcnn_r50_fpn_2x_coco.py --det-checkpoint Checkpionts/mmdetection/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth --video data/1.mp4 --out-filename demo/det_1.mp4 --det-score-thr 0.5 --action-score-thr 0.5 --output-stepsize 4 --output-fps 6 --label-map tools/data/ava/label_map.txt-
其中 best_mAP@0.5IOU_epoch_10.pth 是训练后的权重,在mmaction2_YF/work_dirs/ava/slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb中:
-
测试视频放在data文件夹中,命名为1.mp4,检测后的结果在demo文件夹中

本文参考文章如下:
自定义ava数据集及训练与测试 完整版 时空动作/行为 视频数据集制作 yolov5, deep sort, VIA MMAction, SlowFast-CSDN博客
【mmaction2】AVA数据集处理遇到的问题-CSDN博客


















 3295
3295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









