







监督式机器学习
监督式机器学习是指数据集中的每条记录都包含标签或标志的问题类型。
请考虑下表,其中包含有关最高温度、最低温度和最大振动的信息。
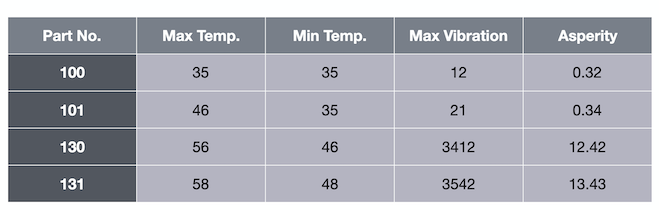
最后一列 asperity 是标签。给定温度和振动数据,我们想要预测粗糙度。这是一个带标签的数据集。
使用这个包含标签的数据集,我们可以训练一种算法来预测未标记数据的未来。你把它拟合到你的算法中,算法现在会预测这个数据的标签。这称为监督学习。回归和分类是监督学习的两种类型。
回归
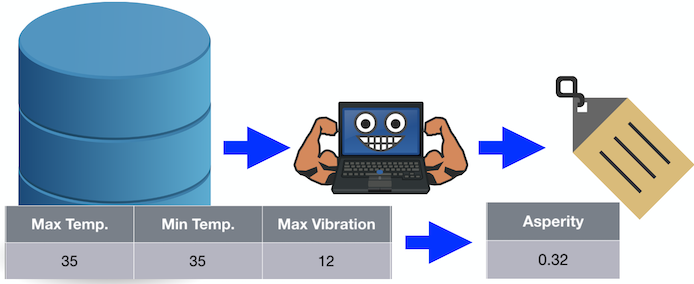
必须预测连续值的用例类型称为回归。例如,如果我们向算法传递值 35、35 和 12,则预测粗糙度的值为 0.32。
分类
输出为二进制值或至少是离散值而不是连续值的用例类型称为分类。换句话说,该算法不预测数字,而是预测类变量。
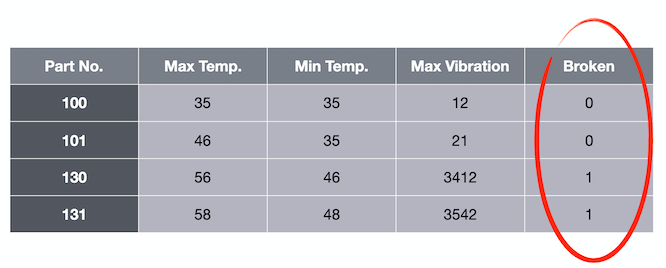
例如,如果我们将值 35、35 和 12 传递给算法,则预测值 0 表示损坏。
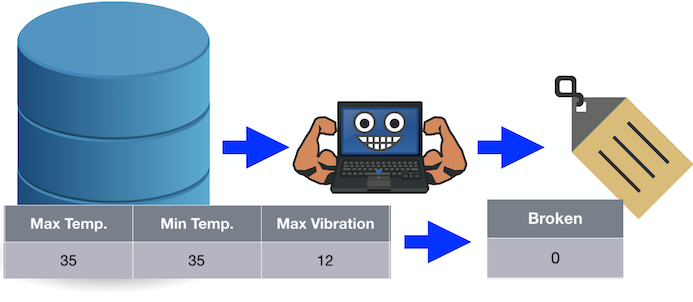
如果只有两个类,则称为二元分类。如果有两个以上的类,则具有多类分类。
无监督学习
无监督机器学习是指数据集中没有记录包含任何标签或标志的问题类型。聚类是一种无监督机器学习。
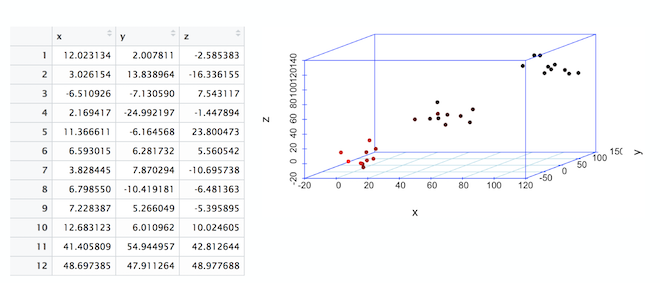
聚类
在前面显示的 3 维图中,请注意 3 个数据簇或云。仅通过绘制表格,我们就可以看到数据以三个聚类为中心。此过程称为聚类分析。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









