






MapReduce介绍
1.流程
(1)MapReduce是一种编程模型,主要用于大规模数据集(大于1TB) 的并行运算。其名称来源于两个主要操作:Map (映射)和Reduce'(归约),这两个概念都是从函数式编程语言中借鉴而来的。MapReduce的设计极大地简化了编程人员在分布式系统上进行并行编程的复杂性。
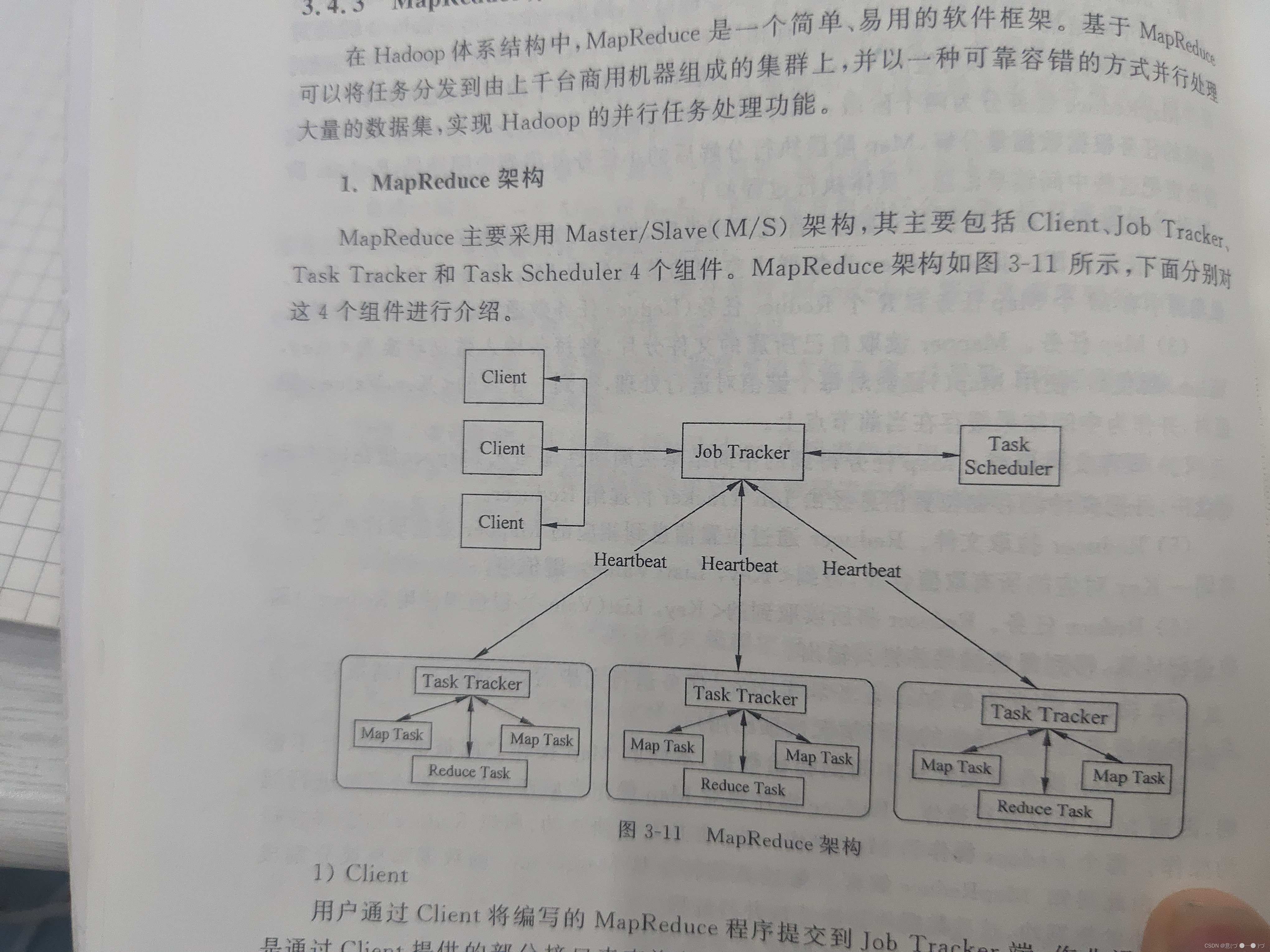
(2)一个MapReduce任务需要由以下4部分协作完成。
(1)Client(客户端):客户端与集群进行交互的接口,可以进行任务提交、结果获取等工作,
(2)Job Tracker(作业追踪器):Job Tracker是集群的总负责节点,主要起到集群的调度作用,一个集群中只能有一个Job Tracker。将任务分为map任务和reduce任务
(3) Task Tracker:Task Tracker是作业的真正执行者,可以执行两类任务:Map任务和Reduce任务。执行Map任务的Task Tracker称为Mapper,执行Reduce任务的Task Tracker称为Reducer, 一个集群中可以有多个Task Tracker。
(4)分布式文件系统:分布式文件系统用来存储输入/输出的数据,通常使用HDFS。
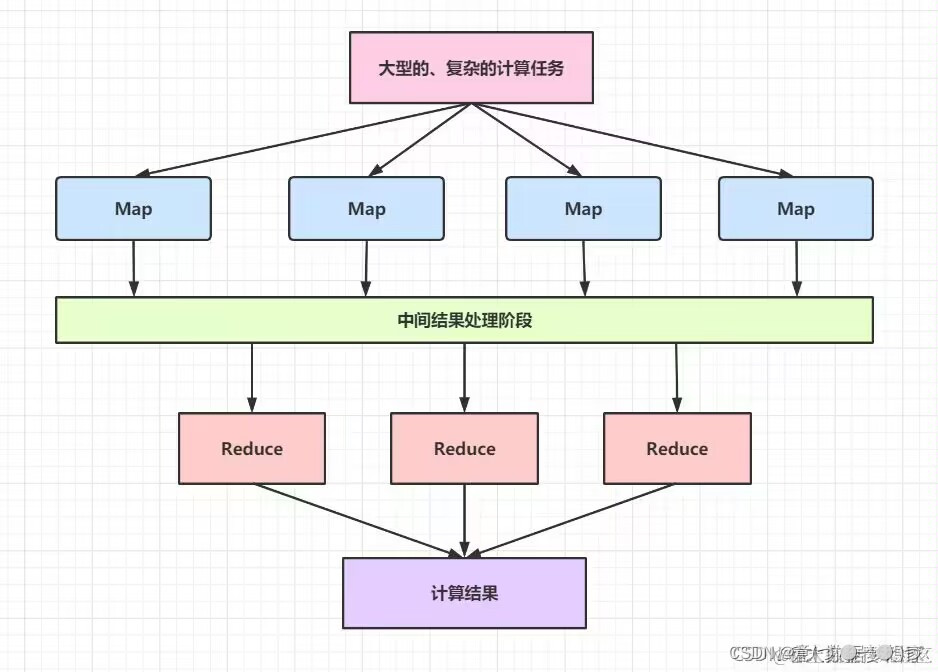
2.核心思想
在MapReduce的工作流程中,主要包括两个阶段:Map阶段和Reduce阶段。在Map阶段,输入数据被切分成多个小的数据块,并由多个并行的Map任务进行处理。每个Map任务将输入数据块映射为一系列键值对。这些键值对被传递给Reduce任务进行处理。在Reduce阶段,所有具有相同键的键值对被分组在一起,并由多个并行的Reduce任务进行处理。每个Reduce任务将一组键值对作为输入,并根据具体的业务逻辑进行处理和聚合,生成最终的输出结果。整个MapReduce过程由一个主节点进行协调和管理,负责分配任务、监控任务的执行进度,并在所有任务完成后收集和整合最终的结果
• Map阶段完全并行运行互不干扰
· Reduce阶段完全并行运行互不干扰,但是
依赖上一阶段的Map的运行结果
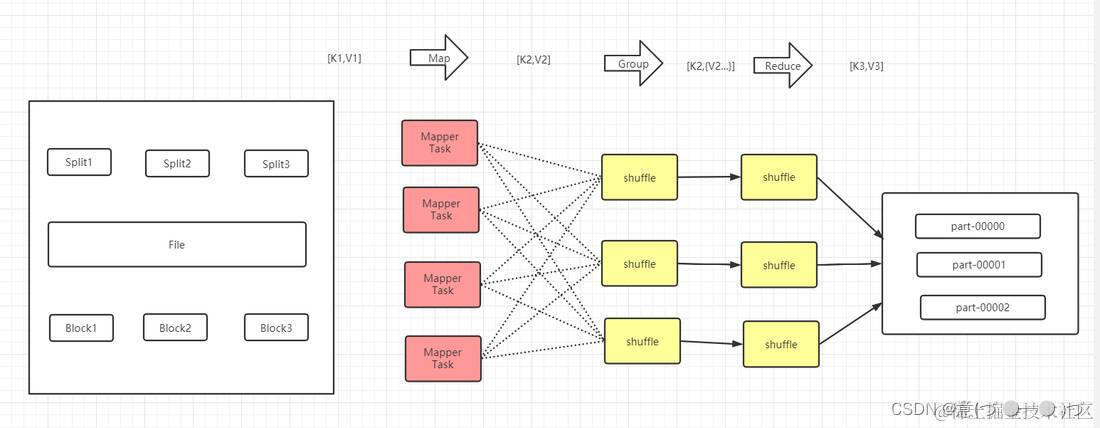
3.MapReduce 编程规范
• 用户编写的程序分成三个部分。
·1、Mapper 阶段
• map()方法负责处理输入数据并产生中间的键值对 (key-value pairs) 作为输出。
。2、Reduce 阶段
reduce()方法会对具有相同键(key)的
所有值 (values) 进行处理,并产生最终的输出结果。
• 3、Driver 阶段
• 相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是
· 封装了MapReduce程序相关运行参数的job对象
4.优缺点
优点
编程模型与方法:MapReduce提供了一种简便的并行程序设计方法,通过Map和Reduce两个函数编程实现基本的并行计算任务。这为大规模数据的编程和计算处理提供了抽象的操作和并行编程接口。
并行计算与运行软件框架:MapReduce是一个并行计算与运行软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果。这使得开发人员可以专注于业务逻辑的实现,而无需关心系统底层的复杂细节。高性能并行计算平台:MapReduce基于集群的高性能并行计算平台,可以使用普通的商用服务器构建包含数十、数百至数千个节点的分布和并行计算集群
缺点
执行速度慢:对于某些复杂的数据处理任务,MapReduce可能需要相对较长的时间来完成。普通的MapReduce作业可能几分钟就能完成,但处理大量数据时,可能需要几个小时甚至更长的时间。这主要是由于MapReduce的批处理特性它更适合处理静态数据集,而不适合实时数据处理。
编程复杂性:虽然MapReduce提供了高级抽象,隐藏了底层的并行和分布式处理细节,但对于某些复杂的计算任务,编写和调试MapReduce作业仍然可能是一项复杂的任务。开发人员需要熟悉MapReduce的编程模型和框架,并理解分布式计算的概念和原理。
资源利用率低:在某些情况下,MapReduce可能无法充分利用集群的计算资源。例如,当处理的数据量较小时MapReduce可能会因为启动和调度任务的开销而降低效率。此外,MapReduce的槽位资源分配模型也可能导致资源利用率低下,因为通常一个任务无法使用完槽位对应的资源,而其他任务又无法使用这些空闲资源。
数据移动开销:在MapReduce中,数据需要在Map和Reduce阶段之间进行磁盘IO操作,这可能会导致性能瓶颈。尽管可以通过合理的数据分区和调优来减少磁盘IO的开销,但仍然需要考虑和处理数据移动和复制的开销。
适用性有限:MapReduce更适用于批处理任务,如大规模数据集的分析和挖掘。但对于需要实时计算和交互式查询的场景,MapReduce的延迟较高,可能不太适合。此外,MapReduce并不适合处理具有复杂依赖关系或需要状态共享的任务,如某些机器学习模型的训练。
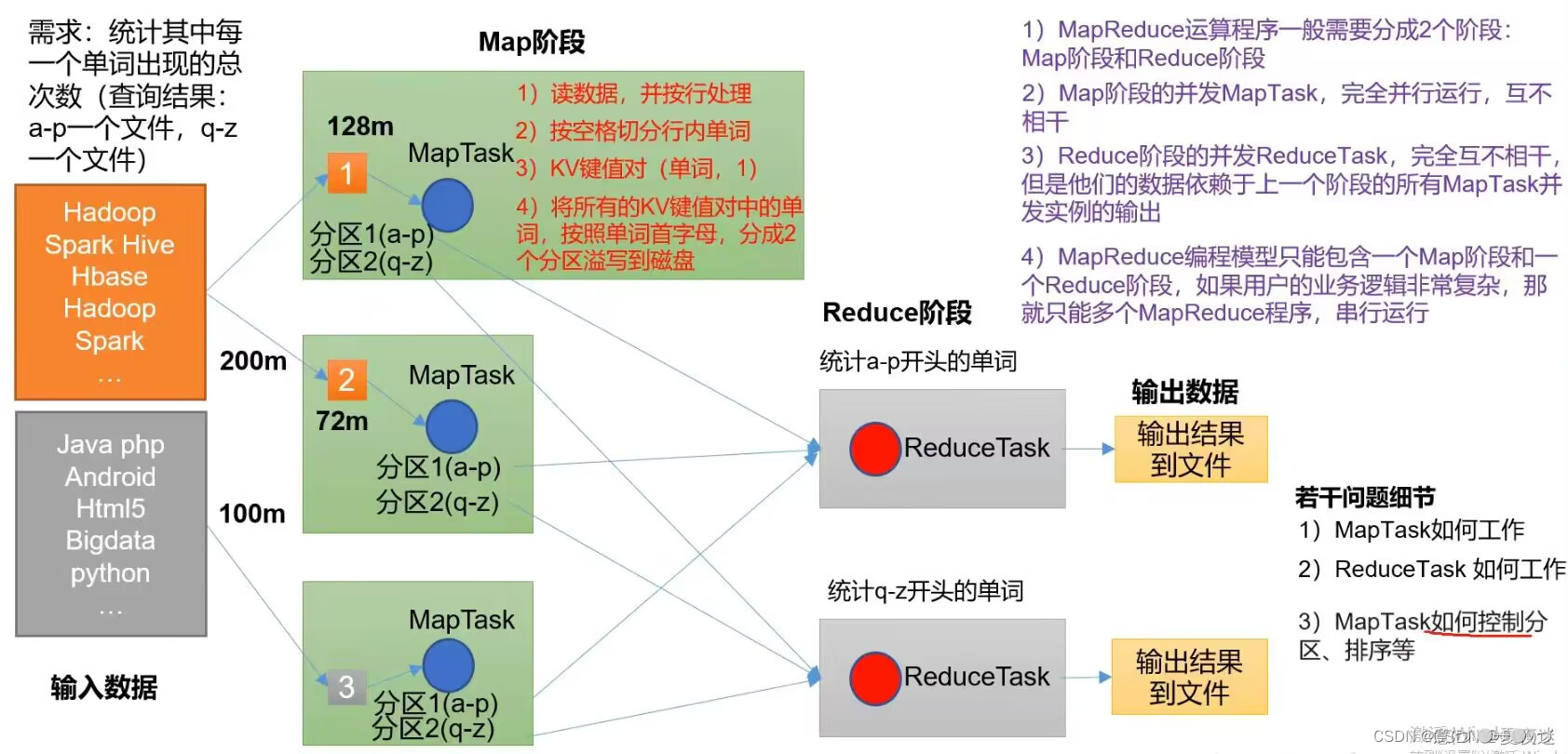
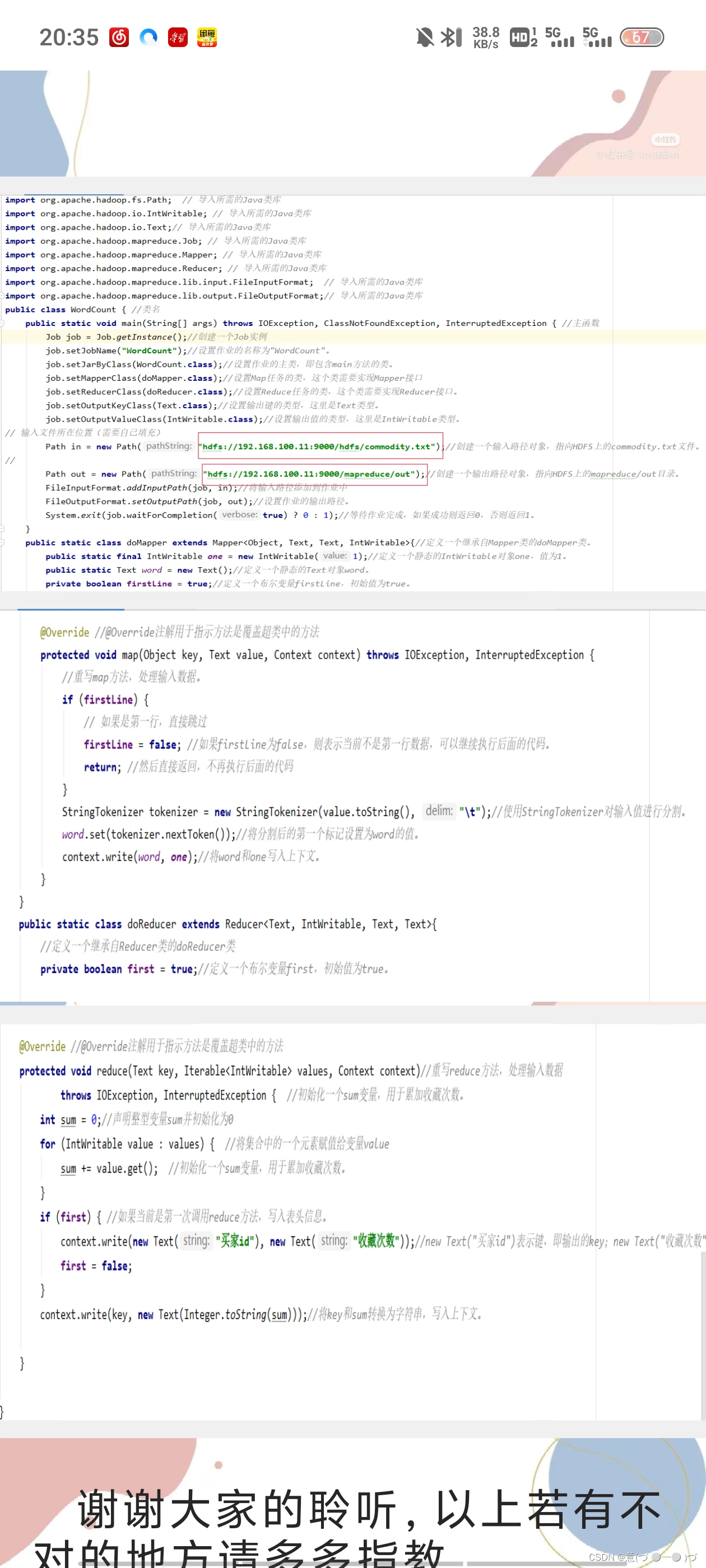
WordCount运行案例















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









