






好不容易把Python入门网课给看完了,也去看了看Python爬虫的相关网课,花了2天时间捣鼓出了本人的首个爬虫代码。(这里真的想要感慨一下,自学Python,真的需要不断给自己定一个小目标,搞个小脚本,搞个小爬虫什么的,然后得到一些成就感并以此坚持下去)
这次想分享一下我研究爬小说的过程。
这是我用到的库
import requests
from bs4 import BeautifulSoup
import re
import time被爬的网页域名为
"https://luoxiadushu.com/santi/"。
整体思路:
1.向网站发送访问请求,获得该网页的全部http内容。
2.通过beautifulsoup来筛选特定的标签并提取其中的超链接到一个info_list空列表中
3.循环这个列表,进入各个章节的网页
4.在这个循环下,发出访问请求获取每个网页的http内容(即获取数据)
5.通过beautifulsoup解析数据
6.对数据进行换行调整
7.存入本地txt文本
具体过程:首先访问"https://luoxiadushu.com/santi/",
右键->检查->观察得每一个章节的http长这样,
由此可以知道要想获取超链接要用beautifulsoup这么打
response=requests.get("https://luoxiadushu.com/santi/",headers=headers)
print(response)
soup1 = BeautifulSoup(response.text,'html.parser')
#获取所有<a>标签开头的http内容
a_tag=soup1.findAll("a")
info_list=[]
#因为还有别的一些不是表示章节的内容是<a>开头的所以要用以下循环筛选
#我们需要的章节包含以下标签<a target=... title='' href='https://....'</a>
#所以从a_tag中找出同时含href,target,title的http内容
for tag in a_tag:
href = tag.get('href')
target = tag.get('target')
title = tag.get('title')
if href and target and title:
#把符合条件的href和title放进空列表中
info_list.append([href,title])
#info_list.append(tag.get('href'))
print(info_list)(我查了一些别的爬小说的教程,看到一般都是用正则表达式的,但我还是不太会用正则表达式匹配符合条件的http内容,所以还是用beautifulsoup,所以其实完整代码中都没有用到re库)
点进任意章节,再打开观察它的http内容
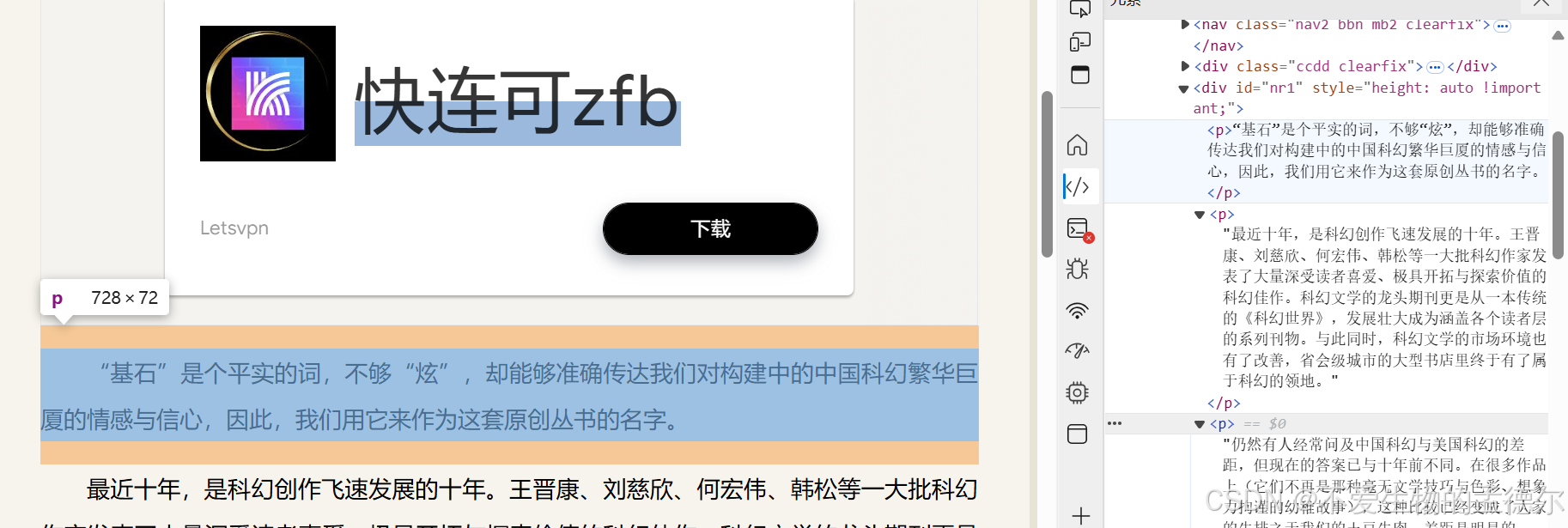
然后一样的思路 ->获取数据->用soup.findAll("p")获得小说文本
for info in info_list:
url=info[0]
print(url)
#获取数据
response1=requests.get(url,headers=headers)
html_txt=response1.text
#print(html_txt)
soup=BeautifulSoup(html_txt,"html.parser")
contents=soup.find_all('p')
#print(contents)得到的其中一个contents元素长这样

然后对爬来的数据进行调整换行
#换行调整
text = '\n\n' + info[1] + '\n\n'
for element in contents:
# 替换元素内的文本
if element.string is not None:
element.string= element.string.replace('<p></p>', '\n')
#print(element.string)
text+=element.string+'\n'
print("正在获取"+ url)
最后保存到文件
# 保存到文件
with open('三体.txt', mode='a', encoding='utf-8') as f:
print("三体文件已打开")
#print(text)
f.write(text)
f.flush()
time.sleep(10)最后附上完整源码
import requests
from bs4 import BeautifulSoup
import re
import time
headers={'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'}
if __name__=='__main__':
response=requests.get("https://luoxiadushu.com/santi/",headers=headers)
print(response)
soup1 = BeautifulSoup(response.text,'html.parser')
a_tag=soup1.findAll("a")
info_list=[]
for tag in a_tag:
href = tag.get('href')
target = tag.get('target')
title = tag.get('title')
if href and target and title:
info_list.append([href,title])
#info_list.append(tag.get('href'))
print(info_list)
for info in info_list:
url=info[0]
print(url)
#获取数据
response1=requests.get(url,headers=headers)
html_txt=response1.text
#print(html_txt)
soup=BeautifulSoup(html_txt,"html.parser")
contents=soup.find_all('p')
print(contents)
#换行调整
text = '\n\n' + info[1] + '\n\n'
for element in contents:
# 替换元素内的文本
if element.string is not None:
element.string= element.string.replace('<p></p>', '\n')
#print(element.string)
text+=element.string+'\n'
print("正在获取"+ url)
#print(text)
# 保存到文件
with open('三体副本.txt', mode='a', encoding='utf-8') as f:
print("三体副本文件已打开")
#print(text)
f.write(text)
f.flush()
time.sleep(10)成果长这样



















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









