






一. Requests库高级用法
1、会话设置:
使用requests.session()可以维护一个会话,自动处理Cookies问题。通过session.post()和session.get()方法可以实现登录后的数据获取。
2、文件上传:
可以通过requests.post()方法上传文件,使用files参数指定要上传的文件。
3、SSL证书验证:
使用verify参数控制是否验证SSL证书。默认为True,设置为False可以忽略证书验证。
4、代理设置:
通过proxies参数设置代理,可以解决IP被封禁等问题。
二. XPath基本用法
1、XPath简介:
XPath是一种在XML/HTML文档中查找信息的语言,使用路径表达式来选取节点。
2、常用规则:
/:从根节点选取。 //:从当前节点选取文档中的节点,而不考虑它们的位置。.:选取当前节点。..:选取父节点。@:选取属性。
3、谓语:
用于查找特定的节点或包含特定值的节点,例如//book[price>35.00]。
4、通配符:
*:匹配任何元素节点。 @*:匹配任何属性节点 node():匹配任何类型的节点。
5、组合路径:
使用|运算符可以选取多个路径,例如//book/title | //book/price。
三. etree模块
1、HTML解析:
使用etree.HTML()方法解析HTML字符串,自动补全不完整的HTML文档。
2、XPath规则:
//li/a:选取所有<a>标签的子节点或子孙节点。../@class:选取父节点的class属性。//li[@class="item-1"]:通过属性过滤节点。//li[@class="item-1"]/a/text():获取节点中的文本。//li/a/@href:获取属性内容。contains():用于配置多值属性。
四、爬虫案例
1、人邮图书爬取案例:
代码复现: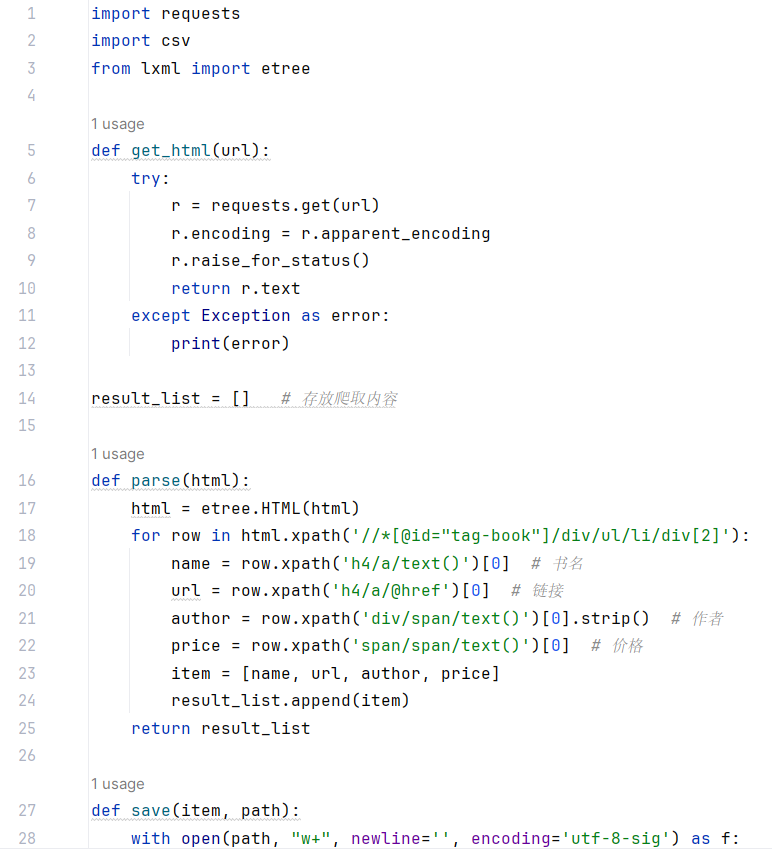
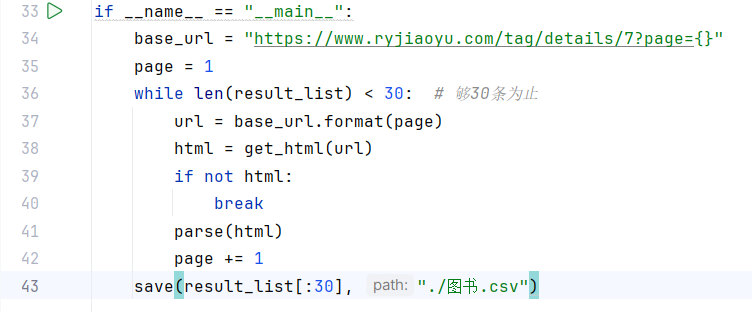

分析:代码通过爬取人邮教育社区的图书页面,提取书名、链接、作者和价格信息,并将这些信息保存到 CSV 文件中,直到获取到 30 条数据为止。
2、酷狗音乐华语新歌榜爬取案例:
代码复现: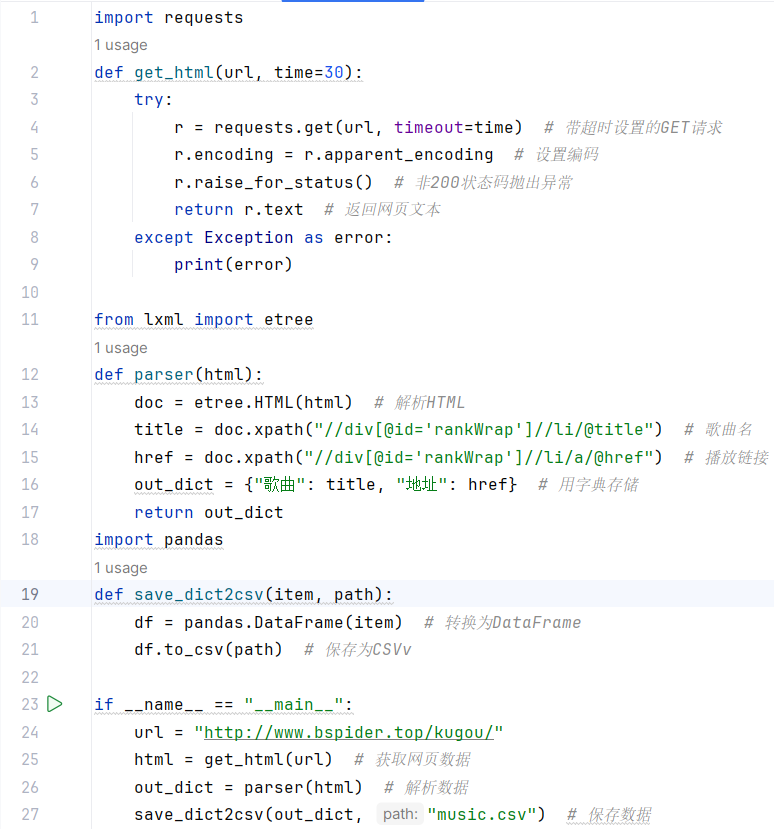
 分析:通过爬取酷狗音乐华语新歌榜页面,提取歌曲名和播放链接,并将这些信息保存到 CSV 文件中。
分析:通过爬取酷狗音乐华语新歌榜页面,提取歌曲名和播放链接,并将这些信息保存到 CSV 文件中。
3、起点中文网原创风云榜爬取案例:
代码复现: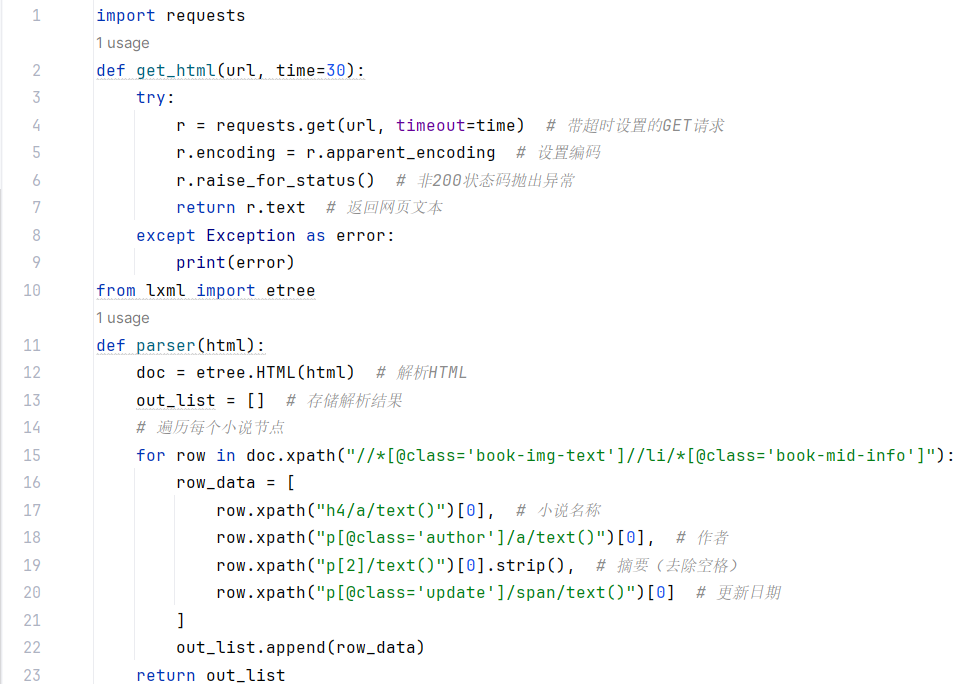
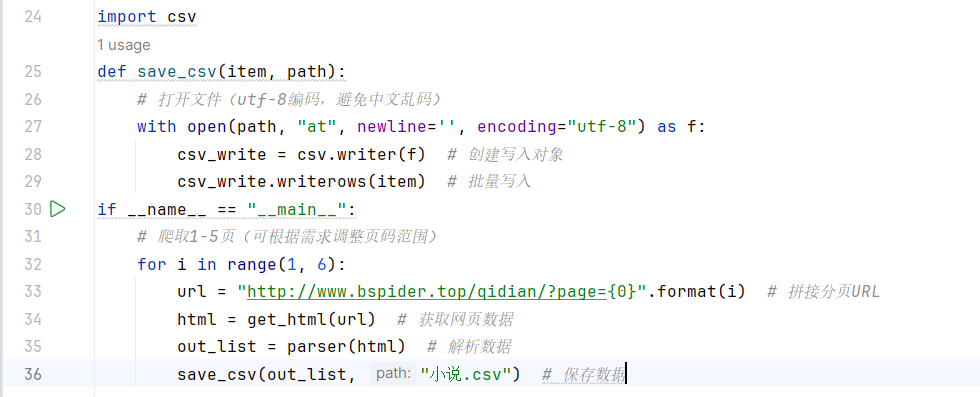

分析:爬取起点中文网原创风云榜的小说信息(包括小说名称、作者、摘要和更新日期),并将这些信息保存到 CSV 文件中。
五、任务
1、分析:
我的代码是一个简单的豆瓣读书 Top 250 数据爬取程序,使用了 requests 和 lxml 库来获取和解析网页内容,并将数据保存到 CSV 文件中。
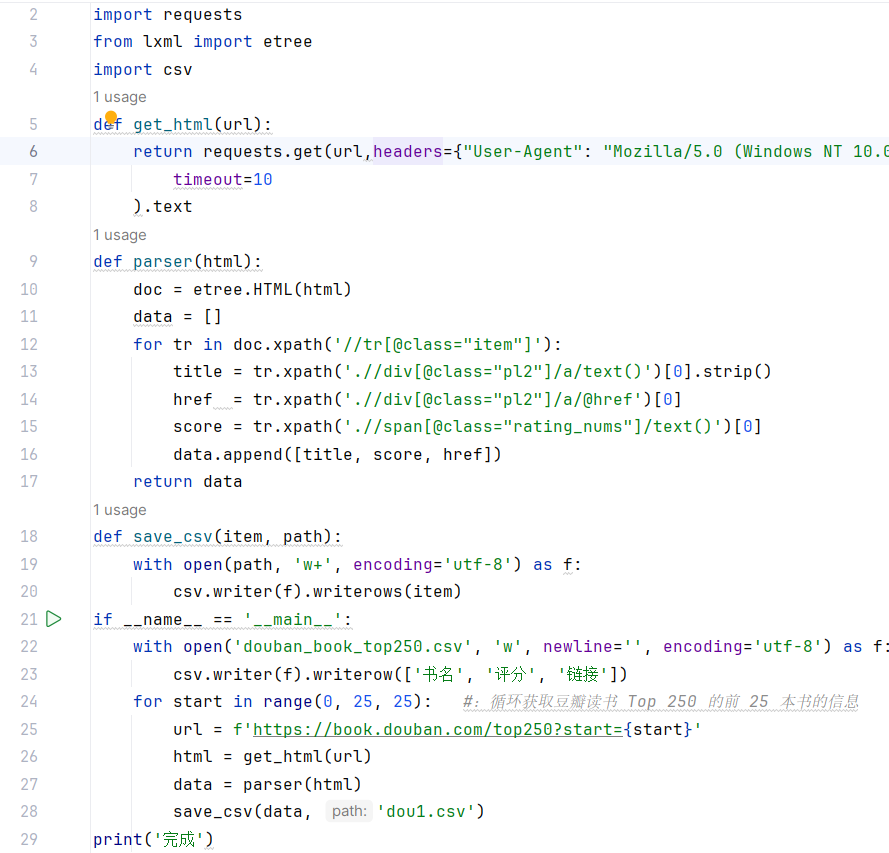
2、知识点:
网络请求、HTML 解析、XPath 表达式、CSV 文件操作、异常处理。

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









