







总结
至此,文章终于到了尾声。总结一下,我们谈论了简历制作过程中需要注意的以下三个部分,并分别给出了一些建议:
- 技术能力:先写岗位所需能力,再写加分能力,不要写无关能力;
- 项目经历:只写明星项目,描述遵循 STAR 法则;
- 简历印象:简历遵循三大原则:清晰,简短,必要,要有的放矢,不要海投;
以及最后为大家准备的福利时间:简历模板+Java面试题+热门技术系列教程视频



# 状态转移概率矩阵
self.A = torch.zeros(N, N)
# 观测概率矩阵
self.B = torch.zeros(N, M)
# 初始状态概率
self.Pi = torch.zeros(N)
def train(self, word_lists, tag_lists, word2id, tag2id): # word2id: 将字映射为ID; tag2id: 将标注映射为ID
# 使用极大似然估计的方法来估计隐马尔可夫模型的参数
# 估计转移概率矩阵
for tag_list in tag_lists:
seq_len = len(tag_list)
for i in range(seq_len - 1):
current_tagid = tag2id[tag_list[i]]
next_tagid = tag2id[tag_list[i+1]]
self.A[current_tagid][next_tagid] += 1
self.A[self.A == 0.] = 1e-10 # 将未出现元素设置一个小数
self.A = self.A / self.A.sum(dim=1, keepdim=True)
# 估计观测概率矩阵
for tag_list, word_list in zip(tag_lists, word_lists):
assert len(tag_list) == len(word_list)
for tag, word in zip(tag_list, word_list):
tag_id = tag2id[tag]
word_id = word2id[word]
self.B[tag_id][word_id] += 1
self.B[self.B == 0.] = 1e-10
self.B = self.B / self.B.sum(dim=1, keepdim=True)
# 估计初始状态概率
for tag_list in tag_lists:
init_tagid = tag2id[tag_list[0]]
self.Pi[init_tagid] += 1
self.Pi[self.Pi == 0.] = 1e-10
self.Pi = self.Pi / self.Pi.sum()
def test(self, word_lists, word2id, tag2id):
pred_tag_lists = []
for word_list in word_lists:
pred_tag_list = self.decoding(word_list, word2id, tag2id)
pred_tag_lists.append(pred_tag_list)
return pred_tag_lists
def decoding(self, word_list, word2id, tag2id):
"""
使用维特比算法,其本质是用动态规划解隐马尔可夫模型预测问题(求概率最大路径)
“”"
# 对数化防止下溢
A = torch.log(self.A)
B = torch.log(self.B)
Pi = torch.log(self.Pi)
# 初始化维比特矩阵viterbi
seq_len = len(word_list)
viterbi = torch.zeros(self.N, seq_len)
# backpointer[i,j]: 标注序列的第j个标注为i时,第j-1个标注的id
backpointer = torch.zeros(self.N, seq_len).long()
start_wordid = word2id.get(word_list[0], None)
Bt = B.t()
if start_wordid is None:
bt = torch.log(torch.ones(self.N) / self.N) # 如果字不再字典里,则假设状态的概率分布是均匀的
else:
bt = Bt[start_wordid] # 否则从观测概率矩阵中取bt
viterbi[:, 0] = Pi + bt
backpointer[:, 0] = -1
# 递推公式:viterbi[tag\_id, step] = max(viterbi[:, step-1]\* self.A.t()[tag\_id] \* Bt[word])
for step in range(1, seq_len):
wordid = word2id.get(word_list[step], None)
if wordid is None:
bt = torch.log(torch.ones(self.N) / self.N)
else:
bt = Bt[wordid]
for tag_id in range(len(tag2id)):
max_prob, max_id = torch.max(
viterbi[:, step-1] + A[:, tag_id],
dim=0
)
viterbi[tag_id, step] = max_prob + bt[tag_id]
backpointer[tag_id, step] = max_id
# 最优路径的概率
best_path_prob, best_path_pointer = torch.max(
viterbi[:, seq_len-1], dim=0
)
# 求最优路径
best_path_pointer = best_path_pointer.item()
best_path = [best_path_pointer]
for back_step in range(seq_len-1, 0, -1):
best_path_pointer = backpointer[best_path_pointer, back_step]
best_path_pointer = best_path_pointer.item()
best_path.append(best_path_pointer)
# 将序列tag\_id转化为tag
id2tag = dict((id_, tag) for tag, id_ in tag2id.items())
tag_list = [id2tag[id_] for id_ in reversed(best_path)]
return tag_list
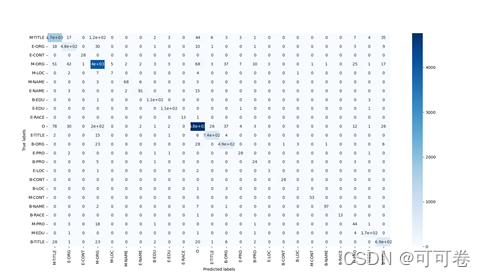
#### 2.1.3 运行结果
### 2.2 Conditional Random Field
#### 2.2.1 算法原理
>
> 条件随机场(CRF)是NER目前的主流模型,它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。CRF为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息,有效克服了HMM模型面临的问题。
>
>
>
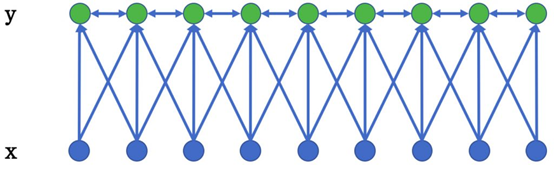
(图2.2 线性链条件随机场)
#### 2.2.2 程序代码
from sklearn_crfsuite import CRF
抽取单个字的特征
def word2features(sent, i):
word = sent[i]
prev_word = “” if i == 0 else sent[i-1]” if i == (len(sent)-1) else sent[i+1]
next_word = “
features = {
‘w’: word, # 当前词
‘w-1’: prev_word, # 前一个词
‘w+1’: next_word, # 后一个词
‘w-1:w’: prev_word+word, # 前一个词+当前词
‘w:w+1’: word+next_word, # 当前词+后一个词
‘bias’: 1
}
return features
抽取序列特征
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
class CRFModel(object):
def __init__(self,
algorithm=‘lbfgs’,
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False
):
self.model = CRF(algorithm=algorithm,
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=all_possible_transitions)
def train(self, sentences, tag_lists):
features = [sent2features(s) for s in sentences]
self.model.fit(features, tag_lists)
def test(self, sentences):
features = [sent2features(s) for s in sentences]
pred_tag_lists = self.model.predict(features)
return pred_tag_lists
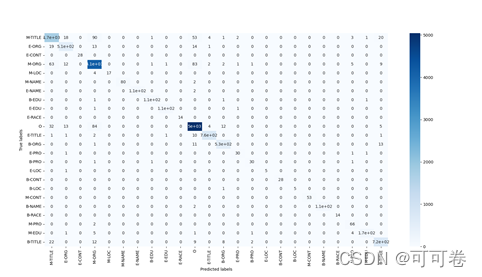
#### 2.2.3 运行结果
## 3 深度学习算法
### 3.1 Bi-LSTM
#### 3.1.1 算法原理
>
> 通过依靠神经网络超强的非线性拟合能力,LSTM在训练时将样本通过高维空间中的复杂非线性变换,学习到从样本到标注的函数,之后使用这个函数为指定的样本预测每个token的标注。
> 而双向长短期有着比普通LSTM更好的捕捉序列之间的依赖关系的能力,能更好地用于捕捉上下文关系。
>
>
>
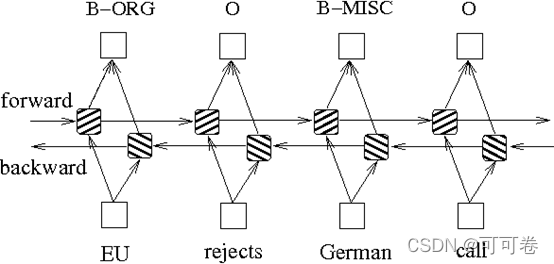
#### 3.1.2 程序代码
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
from torchinfo import summary
import pickle
class BiLSTM(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size):
super(BiLSTM, self).init()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.bilstm = nn.LSTM(emb_size, hidden_size,
batch_first=True,
bidirectional=True)
self.lin = nn.Linear(2\*hidden_size, out_size)
def forward(self, sents_tensor, lengths):
emb = self.embedding(sents_tensor)
packed = pack_padded_sequence(emb, lengths, batch_first=True)
rnn_out, _ = self.bilstm(packed)
rnn_out, _ = pad_packed_sequence(rnn_out, batch_first=True)
scores = self.lin(rnn_out)
return scores
#### 3.1.3 运行结果
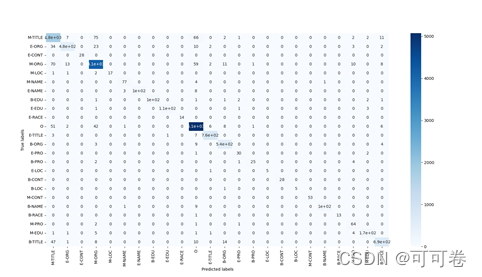
### 3.2 Bi-LSTM+CRF
#### 3.2.1 算法原理
>
> Bi-LSTM:
>
>
> * 优点是能够根据目标(比如识别实体)自动提取观测序列的特征
> * 缺点是无法学习到状态序列(输出的标注)之间的关系(比如B类标注后面不会再接一个B类标注,而通常接M类标注或E类标注)
>
>
> CRF:
>
>
> * 优点就是能对隐含状态建模,学习状态序列的特点
> * 缺点是需要手动提取序列特征
>
>
>
>
> Bi-LSTM+CRF:在Bi-LSTM后面再加一层CRF,以获得两者的优点
>
>
>
#### 3.2.2 程序代码
from itertools import zip_longest
from copy import deepcopy
import torch
import torch.nn as nn
import torch.optim as optim
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size):
super(BiLSTM_CRF, self).init()
self.bilstm = BiLSTM(vocab_size, emb_size, hidden_size, out_size)
# 转移矩阵,初始化为均匀分布
self.transition = nn.Parameter(torch.ones(out_size, out_size) \* 1/out_size)
def forward(self, sents_tensor, lengths):
emission = self.bilstm(sents_tensor, lengths)
# 计算CRF scores
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(
2).expand(-1, -1, out_size, -1) + self.transition.unsqueeze(0)
return crf_scores
def decode(self, test_sents_tensor, lengths, tag2id):
start_id = tag2id['<start>']
end_id = tag2id['<end>']
pad = tag2id['<pad>']
tagset_size = len(tag2id)
crf_scores = self.forward(test_sents_tensor, lengths)
device = crf_scores.device
B, L, T, _ = crf_scores.size()
# 使用维特比算法进行解码
tagids = viterbi(B, L, T, device)
return tagids
#### 3.2.3 运行结果
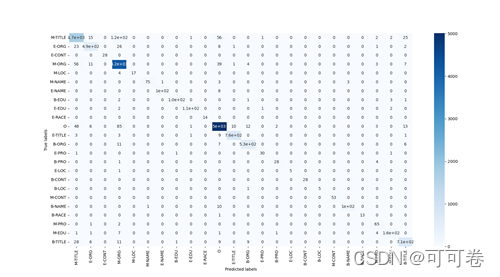
### 3.3 Bert+BiLSTM+CRF
#### 3.3.1 算法原理
>
> BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法。
> 因此,通常可以采用Bert+BiLSTM+CRF的模型结构,以期获取更高的预测精度。
>
>
>
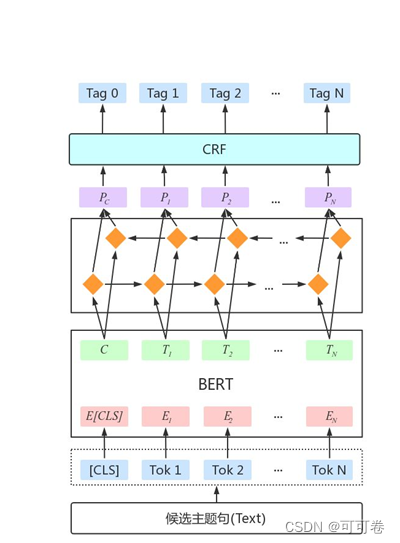
#### 3.3.2 训练模型
>
> 了解到kashgari是一个简单而强大的NLP框架,其内包括cnnmodel、blstm模型、cnnlstm模型、avcnnmodel、KMaxnn模型、RCNN模型等序列(文本)分类模型以及cnnlstm模型、blstm模型、BLSTMCRFModel等序列(文本)标签模型,同时提供GPU支持/多GPU支持,因此选择了kashgari库进行Bert模型的预训练以及微调
>
>
>
from kashgari.tasks.labeling import BiLSTM_CRF_Model
import kashgari
from kashgari.embeddings.bert_embedding import BertEmbedding
import warnings
warnings.filterwarnings(‘ignore’)
bert_embed = BertEmbedding(r’\chinese_L-12_H-768_A-12’,
sequence_length=100)
model = BiLSTM_CRF_Model(bert_embed)
model.fit(train_x,
train_y,
x_validate=valid_x,
y_validate=valid_y,
epochs=5,
batch_size=512)
model.save(‘ner.h5’)
model.evaluate(test_x, test_y)
#### 3.3.3 训练结果
由于模型训练时间过长(一个epoch需要400s),难以有效地进行fine tune,因此模型的效果并不十分理想。
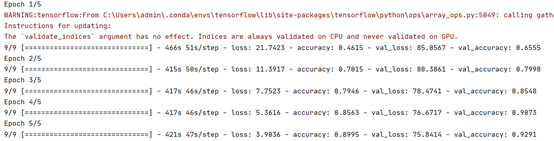
下面是模型训练5个epoch的结果,可以发现,模型的精度一直在提高,并没有达到收敛,这说明模型的潜力值得进一步挖掘。
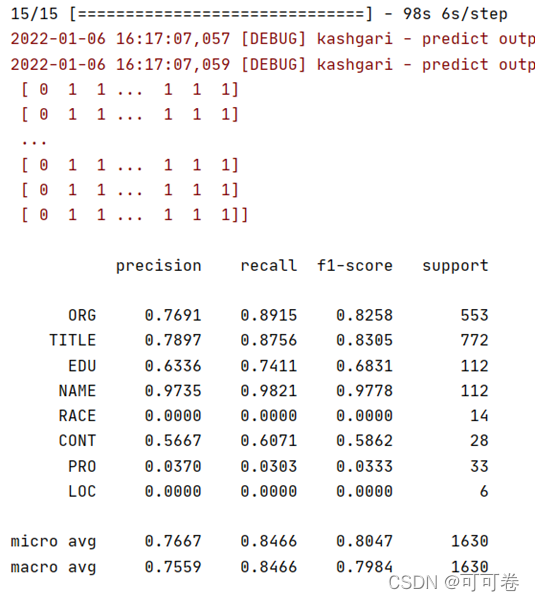
#### 3.3.4 模型结构

## 4 模型融合
### 4.1 融合策略
>
> 考虑到Bert+BiLSTM+CRF结构由于机器的原因,远未发挥应有的效果,因此只将前4个模型进行融合。
> 融合策略为:**voting**
>
>
>
### 4.2 程序代码
def flatten_lists(lists):
flatten_list = []
for l in lists:
if type(l) == list:
flatten_list += l
else:
flatten_list.append(l)
return flatten_list
模型融合
def ensemble_evaluate(results, targets):
for i in range(len(results)):
results[i] = flatten_lists(results[i])
# voting
pred_tags = []
for result in zip(\*results):
ensemble_tag = Counter(result).most_common(1)[0][0]
pred_tags.append(ensemble_tag)
targets = flatten_lists(targets)
return targets
##4.3 融合结果
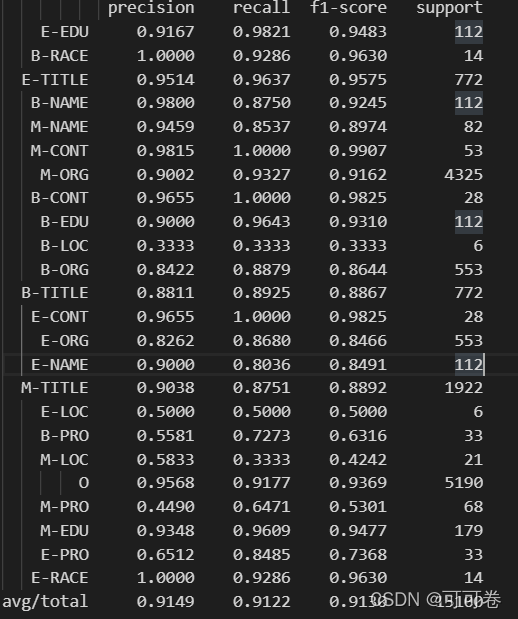
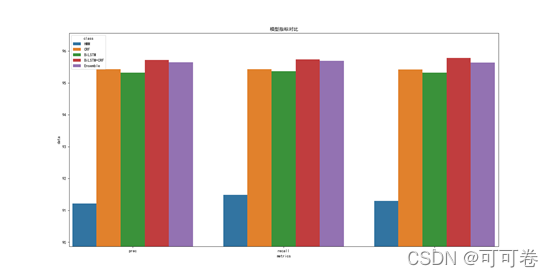
# 最后
整理的这些资料希望对Java开发的朋友们有所参考以及少走弯路,本文的重点是你有没有收获与成长,其余的都不重要,希望读者们能谨记这一点。


其实面试这一块早在第一个说的25大面试专题就全都有的。以上提及的这些全部的面试+学习的各种笔记资料,我这差不多来回搞了三个多月,收集整理真的很不容易,其中还有很多自己的一些知识总结。正是因为很麻烦,所以对以上这些学习复习资料感兴趣,
> **本文已被[CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**
**[需要这份系统化的资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
# 最后
整理的这些资料希望对Java开发的朋友们有所参考以及少走弯路,本文的重点是你有没有收获与成长,其余的都不重要,希望读者们能谨记这一点。
[外链图片转存中...(img-MF3fXwys-1715418694697)]
[外链图片转存中...(img-mCcFwawE-1715418694698)]
其实面试这一块早在第一个说的25大面试专题就全都有的。以上提及的这些全部的面试+学习的各种笔记资料,我这差不多来回搞了三个多月,收集整理真的很不容易,其中还有很多自己的一些知识总结。正是因为很麻烦,所以对以上这些学习复习资料感兴趣,
> **本文已被[CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**
**[需要这份系统化的资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**















 4524
4524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









