








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
之后输入ssh localhost 就可以直接登录了。
四,安装java环境
使用命令直接下载java
sudo apt-get install openjdk-8-jdk -y
查看是否安装成功
java -version

有这个界面就说明安装成功。
然后进行配置java环境变量,使用vim打开配置文件
vim ~/.bashrc
进去之后输入i,进入输入模式,在第一行添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

然后按esc,再输入shift+:进入到末行模式,输入wq保存退出。
继续执行如下命令让.bashrc文件生效
source ~/.bashrc
五,安装hadoop
打开Ubuntu的火狐浏览,输入hadoop下载链接,下载hadoopApache Hadoop https://hadoop.apache.org/release/3.3.6.html
https://hadoop.apache.org/release/3.3.6.html
点击这个链接直接下载
下载完成之后一般会在/home/hadoop/下载 目录下,直接解压出来到/usr/local目录下。
sudo tar -zxf /home/hadoop/下载/hadoop-3.3.6.tar.gz -C /usr/local
将目录名改为hadoop
sudo mv /usr/local/hadoop-3.3.6/ /usr/local/hadoop
修改目录权限
sudo chown -R hadoop /usr/local/hadoop
查看hadoop版本信息
cd /usr/local/hadoop
./bin/hadoop version
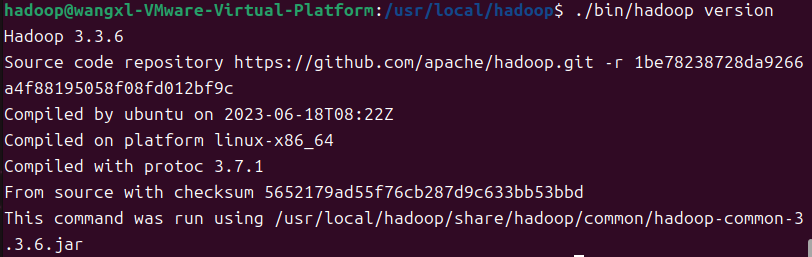
现在可以运行Grep实例来检测一下hadoop是否安装成功。
首先新建input目录
mkdir input
将配置文件复制到input目录下
cp ./etc/hadoop/*.xml ./input
接下来运行代码grep实例
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
最后执行以下命令查看输出数据
cat ./output/*

六,hadoop伪分布式安装
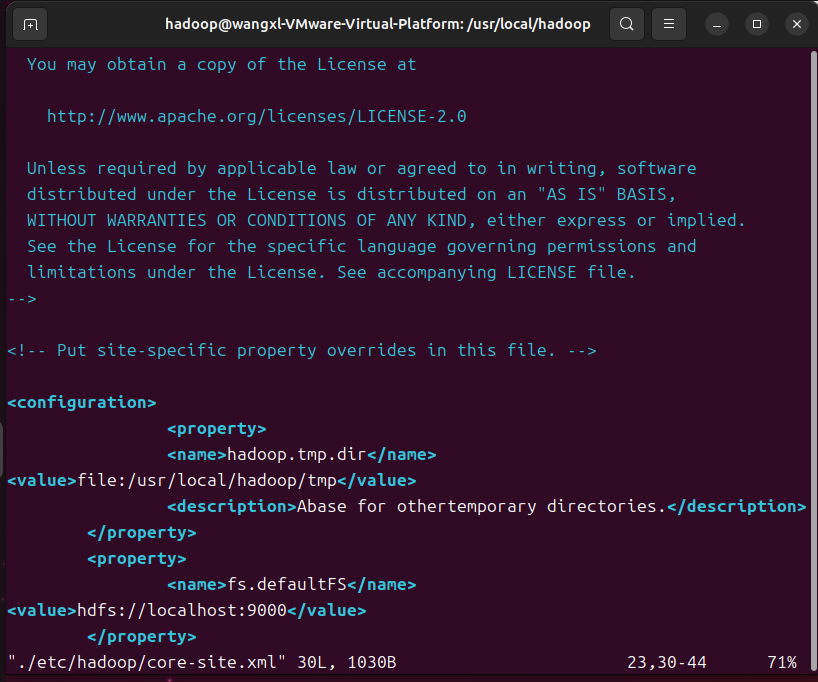
这里需要修改两个文件,先修改core-site.xml 文件
vim ./etc/hadoop/core-site.xml
将下面这些代码添加到中间,然后保存退出
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for othertemporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
修改配置hdfs-site.xml文件
vim ./etc/hadoop/hdfs-site.xml
同样将下面这些代码添加到中间,然后保存退出
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
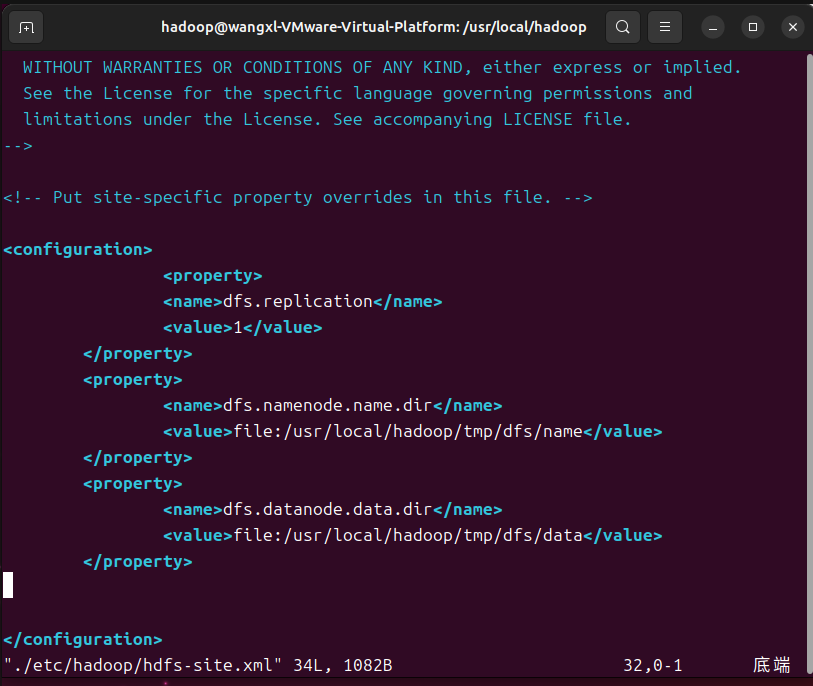
完成之后执行初始化命令
./bin/hdfs namenode -format
文件系统初始化成功后,启动HDFS
./sbin/start-dfs.sh
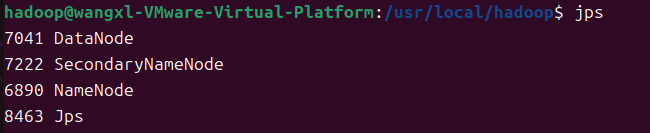
启动之后,可以输入jps查看所有的java进程
jps
此时可以访问web页面,输入http://localhost:9870 查看hadoop信息

接下来在HDFS中创建hadoop用户

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
3jnd-1715813372748)]
[外链图片转存中...(img-p6Hr6WSd-1715813372748)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2835
2835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









