







TL;DR
-
• SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐;
-
• SFT 只通过 LLMs 生成的下一个单词进行估计,而 RLHF 和 DPO 通过 LLMs 生成的完整句子进行估计,显然后者的估计会更准确;
-
• 虽然 RLHF 和 DPO 取得比 SFT 好的结果,但代价是高昂的数据构造和计算资源开销;
-
• IFT 通过引入时序残差连接,仅使用多推理一步的开销,就可以融合 SFT、RLHF 和 DPO 的训练目标,摆脱对偏好数据和参考模型的依赖,保证训练目标与真实生成目标更加相近;
-
• IFT 建模并优化了当前生成单词对所有未来生成结果的影响,增强了模型的因果性和事实性;
引言
随着 ChatGPT 等强大模型的发布,大语言模型(Large Language Models,LLMs)的浪潮席卷而来,并逐渐走进千家万户。LLMs 可以协助文字工作者寻找创作灵感,可以为各年龄段的学生详解知识点,甚至可以帮助心情不好的人做心理疏导。可以说,LLMs 正在成为许多人日常工作与生活的必需品。
然而,现阶段的 LLMs 仍然在一些方面饱受诟病。首当其冲的就是 “幻觉”问题,LLMs 会自信满满地生成不符合事实或常理的回答,可能对使用者造成误导。另外,LLMs 对于复杂指令的理解与遵循能力欠佳,他们可能会自动忽略指令中的某些信息,只完成用户的一部分要求。上面这些问题是 LLMs 落地应用时的硬伤,极大地限制着 LLMs 产生更大的实际价值。
那么,产生上述现象的可能原因有哪些?我们又应该如何改善这些问题?下面我们将从 LLMs 训练方法的角度出发,与大家一同寻找答案。
从 监督微调 到 偏好优化
当下最流行的 LLMs 训练流程大概可以分为以下三步:预训练(Pre-Training,PT)、监督微调(Supervised Fine-Tuning,SFT)和 偏好优化(Preference Optimization,PO)。预训练时,语言模型在超大规模的语料中进行学习,并初步掌握基本的语法规则、逻辑能力、常识知识等等。但是,用于训练的语料中难免存在偏离人类价值观的数据,使 LLMs 不足够符合人类的偏好。同时,预训练的目标仅仅是根据上文补全单词,无法使 LLMs 具备对话和问答能力。因此,为了实现更好的与人交互,进一步的训练成为必须。
监督微调
一种最简单的思路就是,照搬预训练的目标函数和损失函数进一步微调,但是改变数据的质量和格式。为了使 LLMs 对齐人类价值观,我们可以专门筛选一些符合人类价值观的数据;为了让 LLMs 适应对话和问答场景,我们可以构造一问一答或者多轮问答的数据。经过上述数据的训练,模型将拟合这部分数据的特性,从而达到我们的目的,这一过程也被称为监督微调。
LSFT=Eρ0∼DEsi∗∼Sρ0∗[−i=0∑NlogTθ(π∗(si∗),si∗)]
然而,PT 和 SFT 的训练目标与真实的生成任务目标之间存在一定的差距,这会使训练后的 LLMs 难以达到我们的预期。具体来讲,在真实的生成任务中,LLMs 将依据一个指令循环进行下述流程:
-
• ① 依据上文,预测下一个单词;
-
• ② 将自己预测的单词拼接到上文中;
-
• ③ 重复进行上述步骤,直至生成终止符。
然而,在进行 PT 和 SFT 时,步骤②中拼接到上文的将是 Ground Truth 单词,而不是 LLMs 自己预测的单词,使得损失函数高估 LLMs 当前的能力,得到差强人意的训练结果。同时,这种目标函数只考虑了上文对当前预测的影响,没有考虑 LLMs 当前预测对自身未来预测的影响,限制了 LLMs 的因果性和泛化性。
基于人类反馈的强化学习
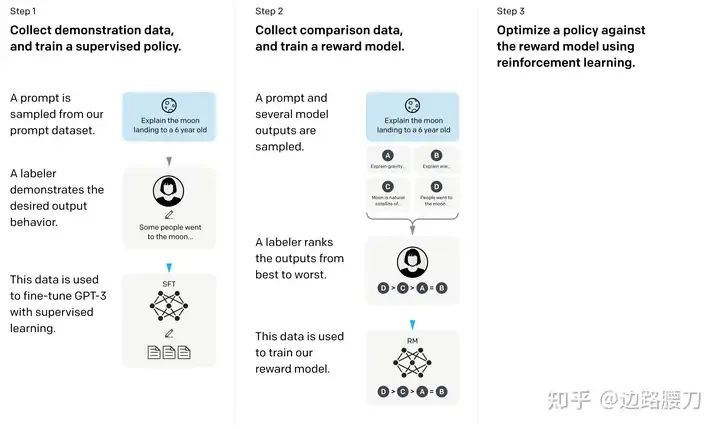
为了缓解上述问题,进一步地提升 LLMs 的对话能力、以及对于人类价值观的对齐程度,偏好优化(Preference Optimization,PO)被引入到了模型微调过程中,基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)便是这类算法最早期的代表。
RLHF 的第一步是根据人类的偏好训练一个打分模型(Reward Model,RM),使其可以评估一条问答数据的质量。随后,LLMs 依据训练集中的指令生成自己偏好的回复(仅依据输入指令自主生成回复,而不是不断地依靠 Ground Truth 预测下一个Token),并使用 RM 的打分作为监督信号,不断让自己的生成结果更接近人类偏好。其中,实现上述优化过程的最常用算法被称为近端策略优化(Proximal Policy Optimization,PPO)。
LPPO=Eρ0∼DEsi∗∼Sρ0∗[−i=0∑NR(πθ(siθ),siθ)] R=πR←πminLR LR=Eρ0∼DEsi+∼Sρ0+,si−∼Sρ0−[−logσ(i=0∑NlogTR(π+(si+)∣si+)−i=0∑NlogTR(π−(si−)∣si−))]
RLHF 使用了更加贴合真实生成任务的目标函数,成为了获得强大 LLMs 的关键步骤。然而,RLHF 存在两方面的巨大开销:
-
• ① 数据构造:为了得到 RM,我们要针对每条指令采集多条(≥2)回复数据,再让人类依据自己的偏好对这些数据进行质量排序,这将耗费大量的人力成本;
-
• ② 计算资源:为了模拟真实的生成场景,在 RLHF 的训练过程中需要实时地让 LLMs 生成回复,并用 RM 进行打分。
同时,由于 RLHF 和 PT 、SFT 之间存在较大的目标函数差异,拟合 RLHF 的目标将带来不稳定的训练过程,并会产生对过往知识的灾难性遗忘。所以,RLHF 还需要一个冻结的参考模型与策略模型(也就是被训练的模型)计算 KL 散度作为约束,抑制模型的参数偏移。于是,在 RLHF 时需要 3-4 个LLMs 同时被存储在 GPU 中并参与运算,计算资源的开销可想而知。
直接偏好优化
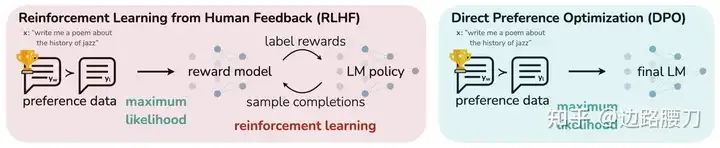
如果不能降低 RLHF 的开销,LLMs 在更广泛场景中的应用将受到限制。于是,直接偏好优化(Direct Preference Optimization,DPO)应运而生。DPO 融合了打分模型和策略模型的训练过程,因此只需要标注过偏好的数据、参考模型和策略模型,就可以使 LLMs 直接对齐人类的偏好,极大地减轻了训练时对计算资源的消耗。但是,理想的 DPO 形态应是 在线DPO(Online DPO),也就是需要实时地采样 LLMs 对指令的回复,并实时地由人类标注偏好。所以,数据构造带来的开销非但没有降低(这种开销经常被忽略),反而要比 RLHF 更高。
LDPO-online=Eρ0∼DEsi∗∼Sρ0∗,siθ∼Sρ0θ[−logσ(i=0∑NlogTθ(π∗(si∗),si∗)−i=0∑NlogTθ(πθ(siθ),siθ))] LDPO-offline=Eρ0∼DEsi+∼Sρ0+,si−∼Sρ0−[−logσ(i=0∑NlogTθ(π+(si+),si+)−i=0∑NlogTθ(π−(si−),si−))]
为此,开源社区通常使用 离线DPO(Offline DPO)微调模型。这种方法会在训练前采集模型对指令的回复,并由人类标注好不同回复之间的排序,随后用这部分数据训练模型。Offline DPO 可以看作是使用事先采集的数据估计了人类和 LLMs 的偏好,随后再通过训练对齐二者的偏好。可是,随着训练的进行,LLMs 会逐渐偏离它自己最开始的偏好,损失函数又会错误地估计 LLMs 当前的能力(和上文中的 PT 和 SFT 类似),进而导致不理想的训练结果。
直觉微调
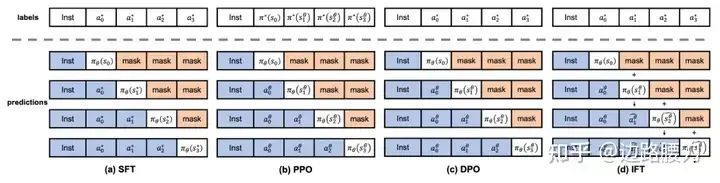
SFT 成本低,但效果欠佳;RLHF 和 DPO 效果好,但是成本过高。那么是否存在某种方法可以兼顾两类算法的优势,在降低开销的同时保证微调效果呢?如果我们使用一个统一的视角,会发现 SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐。不过,SFT 只通过 LLMs 生成的一个单词进行估计,而 RLHF 和 DPO 通过 LLMs 生成的完整句子进行估计,显然后者的估计会更准确。
或者我们可以用复习考试时的刷题进行比喻。如果我们看到一个题目后,先依照自己的理解写完整道题,然后再对答案,通常可以通过试错的方式正确地了解自己的思维漏洞,查漏补缺;相反,如果我们在完成题目时,每写一步结果就立即对答案,随后再在正确答案的基础上写下一步结果,那我们通过这道题目获得的收获显然是更少的。
那么如何才能在不依赖参考模型和偏好数据的前提下,更好地使训练目标对齐真实生成目标呢?更大程度地暴露语言模型的“思维漏洞”是一种可能的解法,也是 直觉微调(Intuitive Fine-Tuning,IFT)的核心思想。IFT 通过引入 时间维度的残差连接(Temproral Residual Connection,TRC),使模型依照自己上一步的预测结果再多预测一步,近似地构建了 LLMs 对于指令的完整回复,更准确地估计了 LLMs 的偏好,从而获得更好的训练结果。这种方式也可以使 LLMs 获得类似于人类直觉的能力,每当它看到某个指令时,就对于完整的回复产生了一个模糊的预测。同时,TRC 还间接地引入了 动态关系传播(Dynamic Relation Propagation,DRP),DRP 可以建模 LLMs 当前预测单词对所有未来生成结果的影响,增强了 LLMs 生成过程中的因果性和事实性。
LIFT=Eρ0∼DEsi∗∼Sρ0∗[−n=0∑Ni=n∑NlogTθ(ai∗,δθ(si∗))]
δθ(si∗)=(1−λ)si∗+λπθ(si−1∗)
若希望了解更详细的问题建模和算法介绍,请参考原论文:Intuitive Fine-Tuning: Towards Simplify Alignment into a Single Process[1]
其他相关方法
Scheduled Sampling
相较于 PE 和 SFT 完全依赖 Ground Truth 作为上文,这个方法在训练过程中逐渐地引入更多 LLMs 自己预测的单词作为上文,旨在让 LLMs 的训练目标更加贴合真实的生成任务。如果把 Scheduled Sampling 看作是对于 LLMs 偏好单词的硬采样,那么 IFT 则可以看作是一种软采样的进化版。IFT 的软采样可以获得模型更完整的偏好估计,并且更加利于进行梯度优化。
∃ Sρ0′⊆Sρ0∗,∀si∗∈Sρ0′,δθ(si∗)=πθ(si−1∗)
Noisy Embedding Fine-Tuning
在 LLMs 的训练和推理过程中,都会首先对输入的上文进行向量化得到 Embedding,随后再将 Embedding 传输到后续的模型中进行运算。这种方法通过在 Embedding 中加入随机噪声来增强训练的泛化性和鲁棒性。IFT 也可以看作是在对 Embedding “加噪”,不过这个噪声是具有上下文因果性的“噪声”,所以相较随机噪声可以帮助模型获得更强的因果性和事实遵从性。
δθ(si∗)∼N(si∗,σδ2)
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











