







目录
引言
- 线性回归模型是统计学和机器学习中一种基本且重要的模型。它用于描述因变量和一个或多个自变量之间的线性关系。线性回归模型广泛应用于各种领域,如经济学、金融学、医学和工程学等。
- 本文将详细介绍线性回归模型,包括其基本概念、数学原理、模型拟合方法、代码实现、模型评估及图形解析。通过具体案例和代码示例,使读者能够深入理解线性回归模型并在实际问题中应用。
线性回归模型概念
线性回归模型是指因变量 $Y$ 与一个或多个自变量 $X$ 之间呈线性关系的统计模型。简单线性回归模型可以表示为:
Y=β0+β1X+ϵ
其中,$Y$ 是因变量,$X$ 是自变量,$\beta_0$ 是截距,$\beta_1$ 是回归系数,$\epsilon$ 是误差项。
对于多元线性回归模型,公式可以扩展为:
Y=β0+β1X1+β2X2+⋯+βpXp+ϵ
其中,$X_1, X_2, \ldots, X_p$ 是多个自变量,$\beta_1, \beta_2, \ldots, \beta_p$ 是对应的回归系数。
数学原理
最小二乘法
- 最常用的线性回归模型参数估计方法是最小二乘法(Ordinary Least Squares,OLS)。最小二乘法的基本思想是选择回归系数,使得模型预测值与真实值之间的误差的平方和最小。具体来说,对于简单线性回归模型,我们希望最小化以下目标函数:
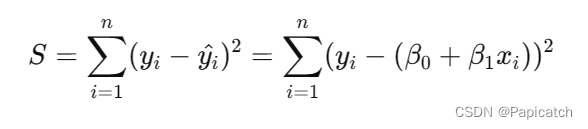
通过求导和解方程组,可以得到回归系数的最优估计值:
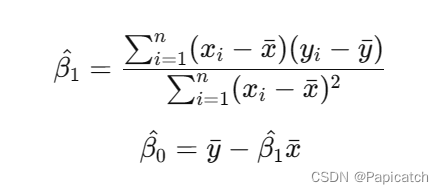
其中,$\bar{x}$ 和 $\bar{y}$ 分别是 $x$ 和 $y$ 的均值。
矩阵形式
- 对于多元线性回归模型,可以使用矩阵形式来表示。设 $X$ 为包含自变量的矩阵,$Y$ 为因变量的向量,$\beta$ 为回归系数向量,则模型可以表示为:
Y=Xβ+ϵ
- 最小二乘法的目标是最小化以下目标函数:
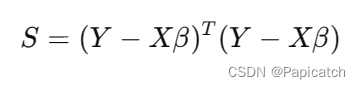
- 通过求导,可以得到回归系数的最优估计值:
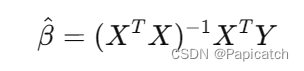
代码实现
简单线性回归
- 下面我们使用 Python 语言实现简单线性回归模型。首先,导入必要的库并生成模拟数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 生成模拟数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 绘制数据散点图
plt.scatter(X, y)
plt.xlabel("X")
plt.ylabel("y")
plt.title("Scatter plot of the data")
plt.show()
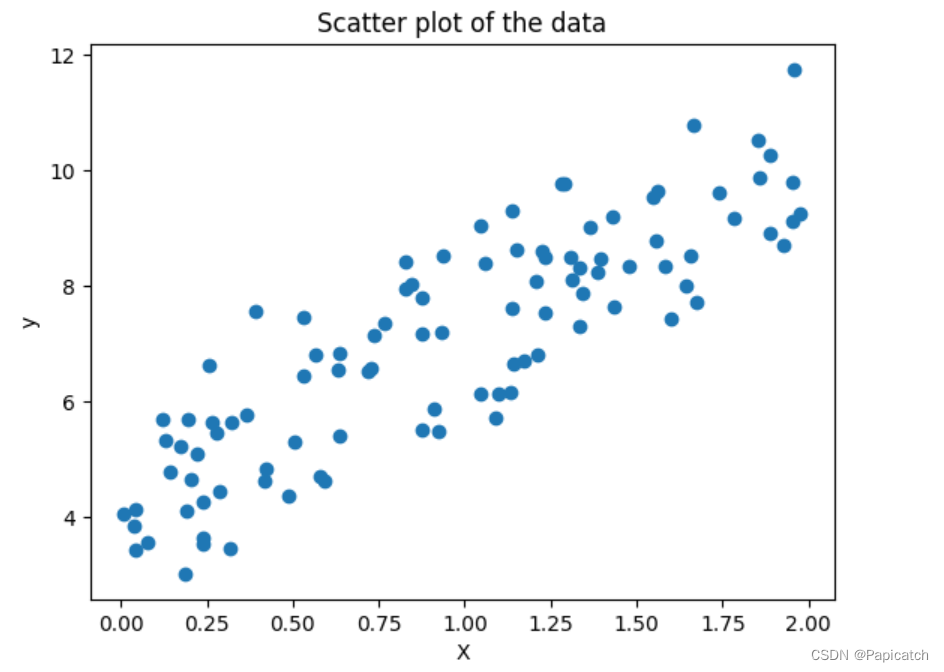
- 接下来,我们使用
sklearn库中的LinearRegression类来拟合简单线性回归模型:
# 拟合线性回归模型
lin_reg = LinearRegression()
lin_reg.fit(X, y)
# 获取回归系数
beta_0 = lin_reg.intercept_
beta_1 = lin_reg.coef_
print(f"Intercept: {beta_0[0]}, Coefficient: {beta_1[0][0]}")

- 模型拟合完成后,我们可以进行预测并计算模型的性能指标:
# 预测
y_pred = lin_reg.predict(X)
# 计算性能指标
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Squared Error: {mse}, R^2 Score: {r2}")
# 绘制回归线
plt.scatter(X, y)
plt.plot(X, y_pred, color='red')
plt.xlabel("X")
plt.ylabel("y")
plt.title("Linear Regression Fit")
plt.show()
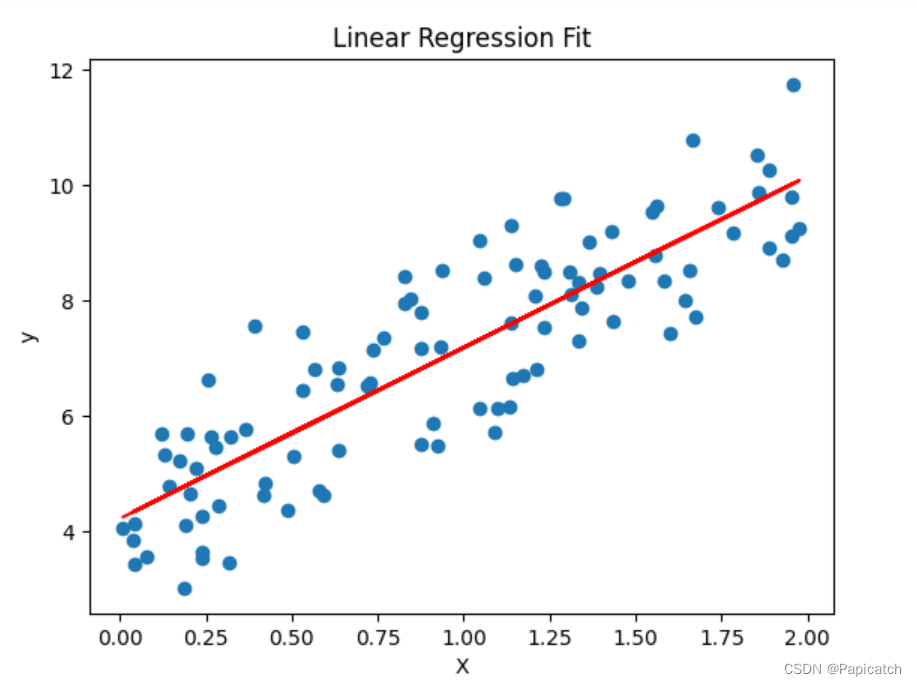
多元线性回归
- 下面我们实现多元线性回归模型。首先,生成模拟数据:
# 生成模拟数据
np.random.seed(0)
X = 2 * np.random.rand(100, 2)
y = 4 + 3 * X[:, 0] + 5 * X[:, 1] + np.random.randn(100)
# 绘制数据散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], y)
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_zlabel("y")
plt.title("Scatter plot of the data")
plt.show()
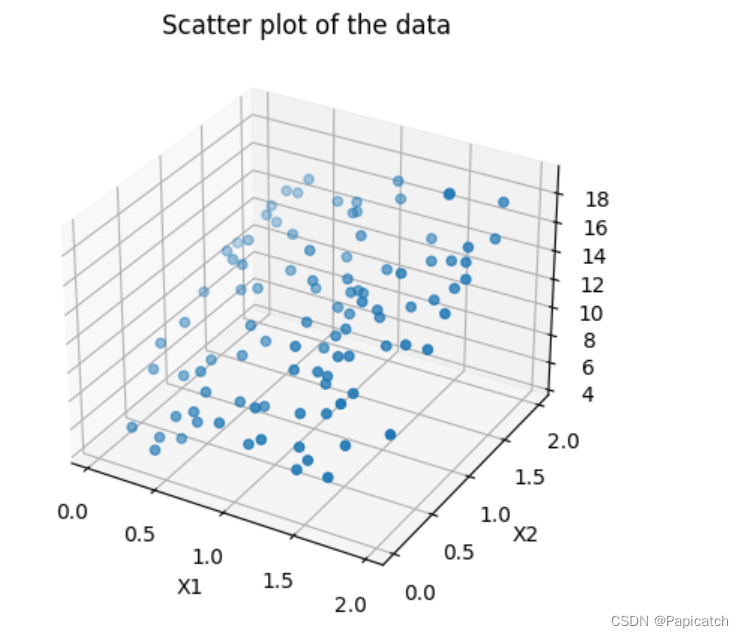
- 然后,使用
LinearRegression类来拟合多元线性回归模型:
# 拟合线性回归模型
lin_reg = LinearRegression()
lin_reg.fit(X, y)
# 获取回归系数
beta_0 = lin_reg.intercept_
beta_1 = lin_reg.coef_
print(f"Intercept: {beta_0}, Coefficients: {beta_1}")
![]()
- 同样地,进行预测并计算性能指标:
# 预测
y_pred = lin_reg.predict(X)
# 计算性能指标
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Squared Error: {mse}, R^2 Score: {r2}")
![]()
模型评估
残差分析
- 残差是指实际值与预测值之间的差异。通过分析残差,可以判断模型的拟合效果。残差图可以帮助我们识别模型是否存在系统性误差。
# 计算残差
residuals = y - y_pred
# 绘制残差图
plt.scatter(y_pred, residuals)
plt.axhline(y=0, color='red', linestyle='--')
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.title("Residual Plot")
plt.show()
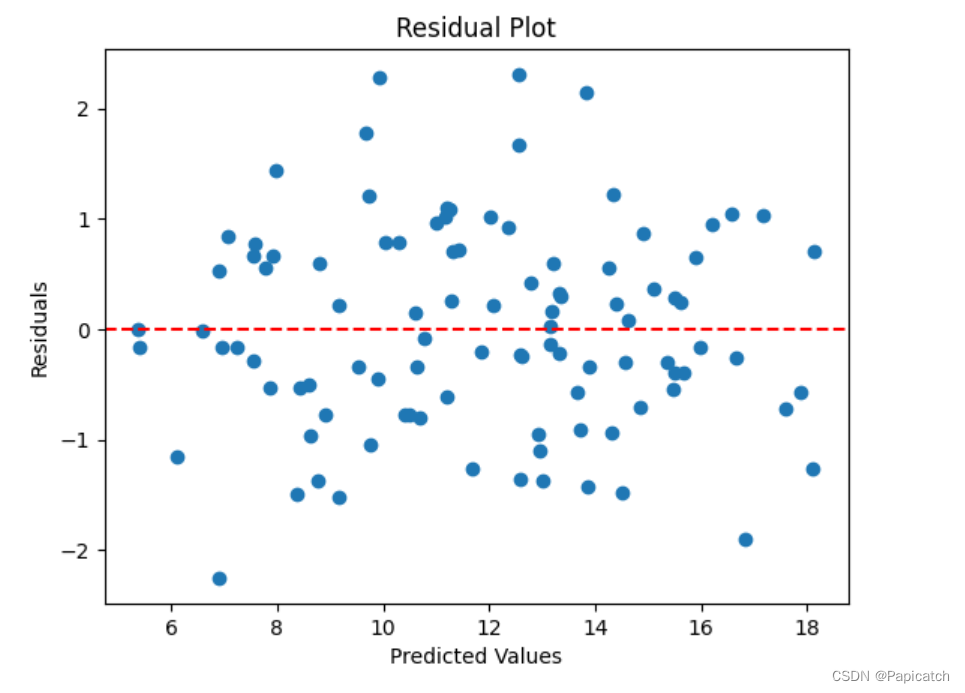
性能指标
- 除了均方误差(MSE)和 $R^2$ 值,我们还可以使用其他性能指标来评估模型,如平均绝对误差(MAE)和均方根误差(RMSE):
from sklearn.metrics import mean_absolute_error
# 计算MAE和RMSE
mae = mean_absolute_error(y, y_pred)
rmse = np.sqrt(mse)
print(f"Mean Absolute Error: {mae}, Root Mean Squared Error: {rmse}")
![]()
希望这些能对刚学习算法的同学们提供些帮助哦!!!


















 3924
3924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









