






第九周调研技能学习
文章目录
Part1:Python安装与环境配置
一、通过Anaconda安装Python以及matplotlib和plotly。
Anaconda介绍
Anaconda是一个用于科学计算的Python发行版,Anaconda支持Linux,Max,Windows系统,提供了包管理和环境管理的功能,可以很方便的解决多版本python并存、切换以及各种第三方包安装问题。简而言之,Anaconda实际上可以便捷获取包和对包能够进行管理。
安装Anaconda软件
Anaconda官网:https://www.anaconda.com/distribution/
link
Anaconda的安装
通过官网可以轻松找到其下载链接,根据不同的操作系统选择安装不同的版本。建议安装在其推荐的位置上。
下载好后,打开安装一直点击Next就好。
- 打开Anaconda Navigator

- 点击左侧第二个栏目Environment
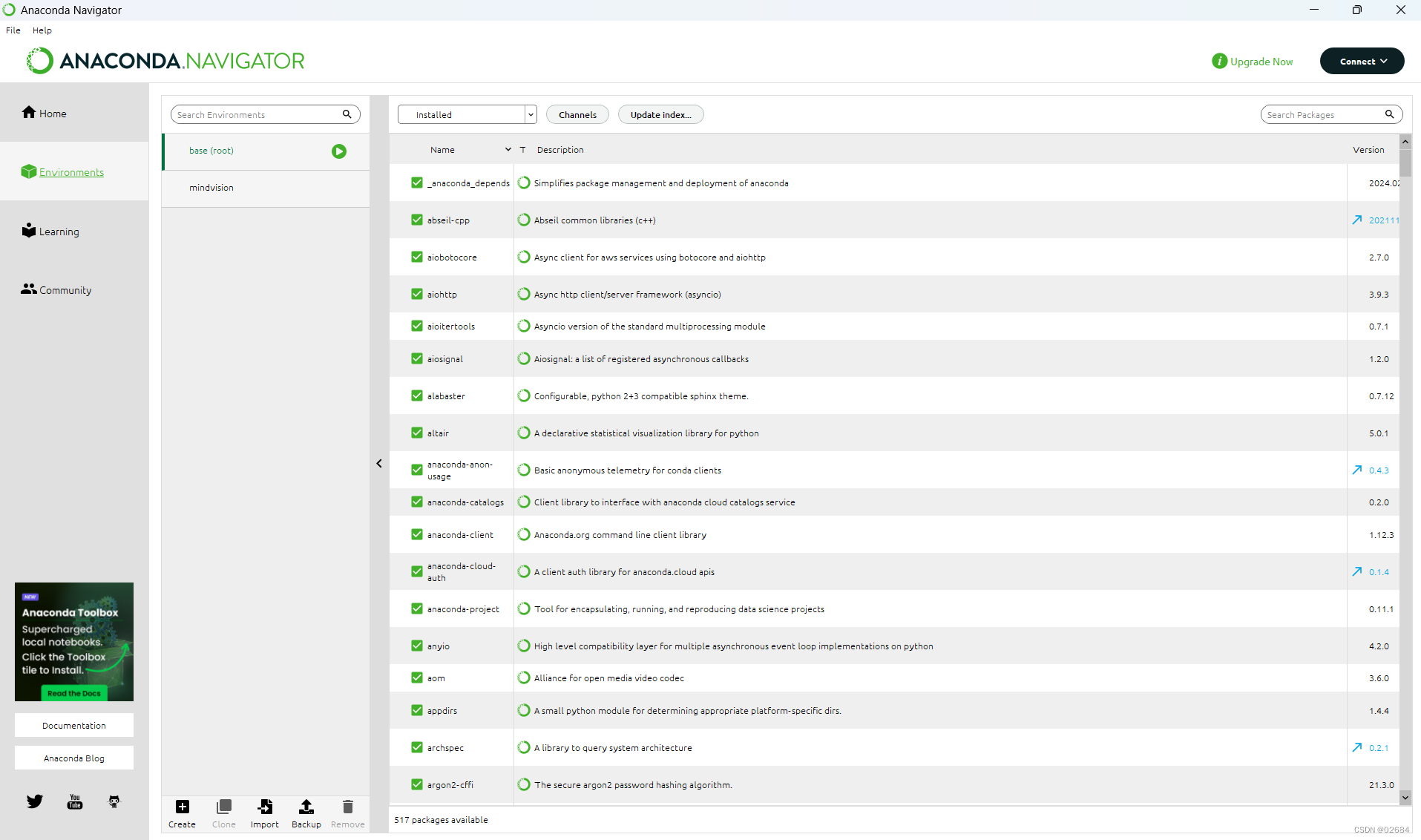
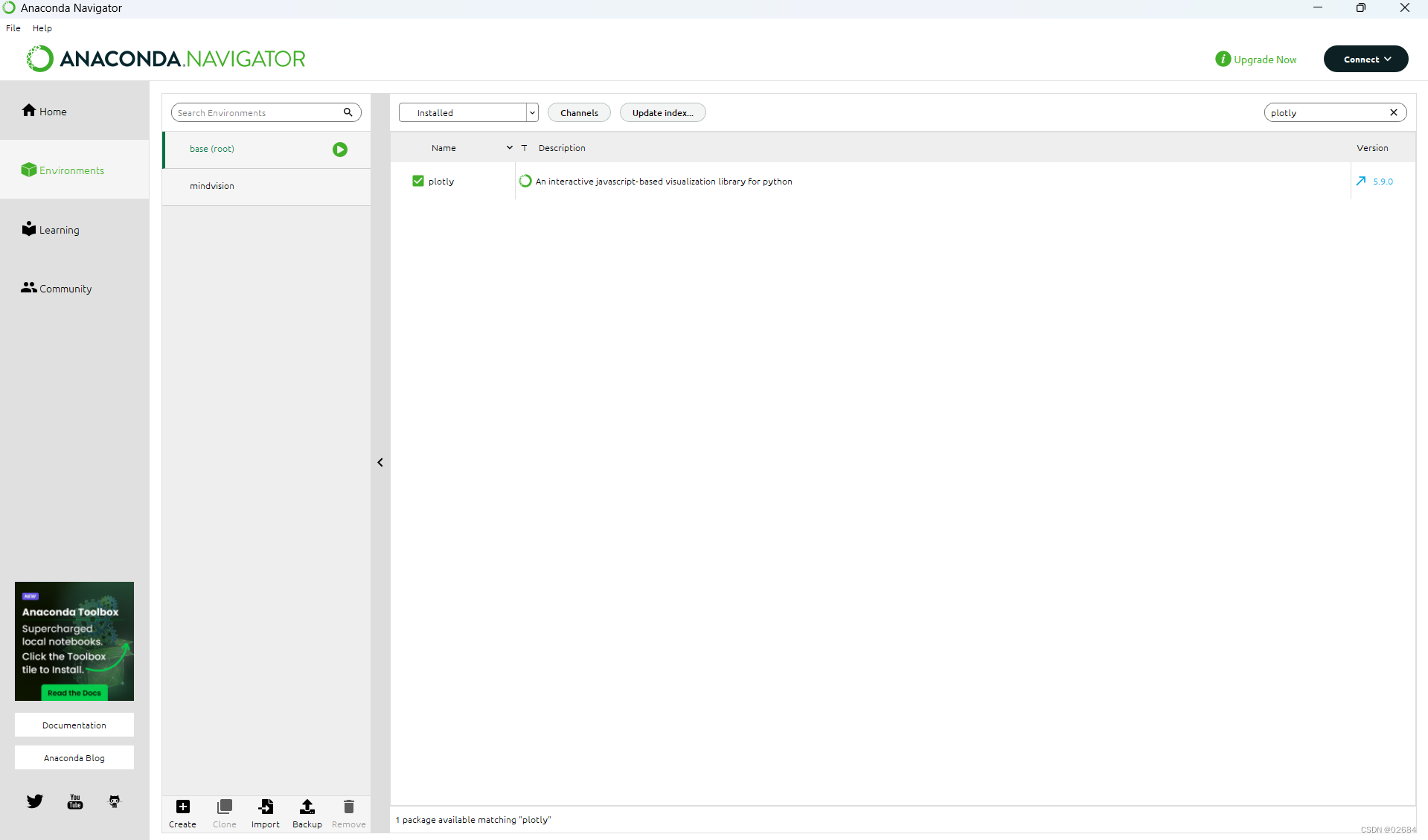
其中,我们可以看到base这个环境,它里面包含了所有安装好的python的包,我们可以在右上角搜索它安装的包。
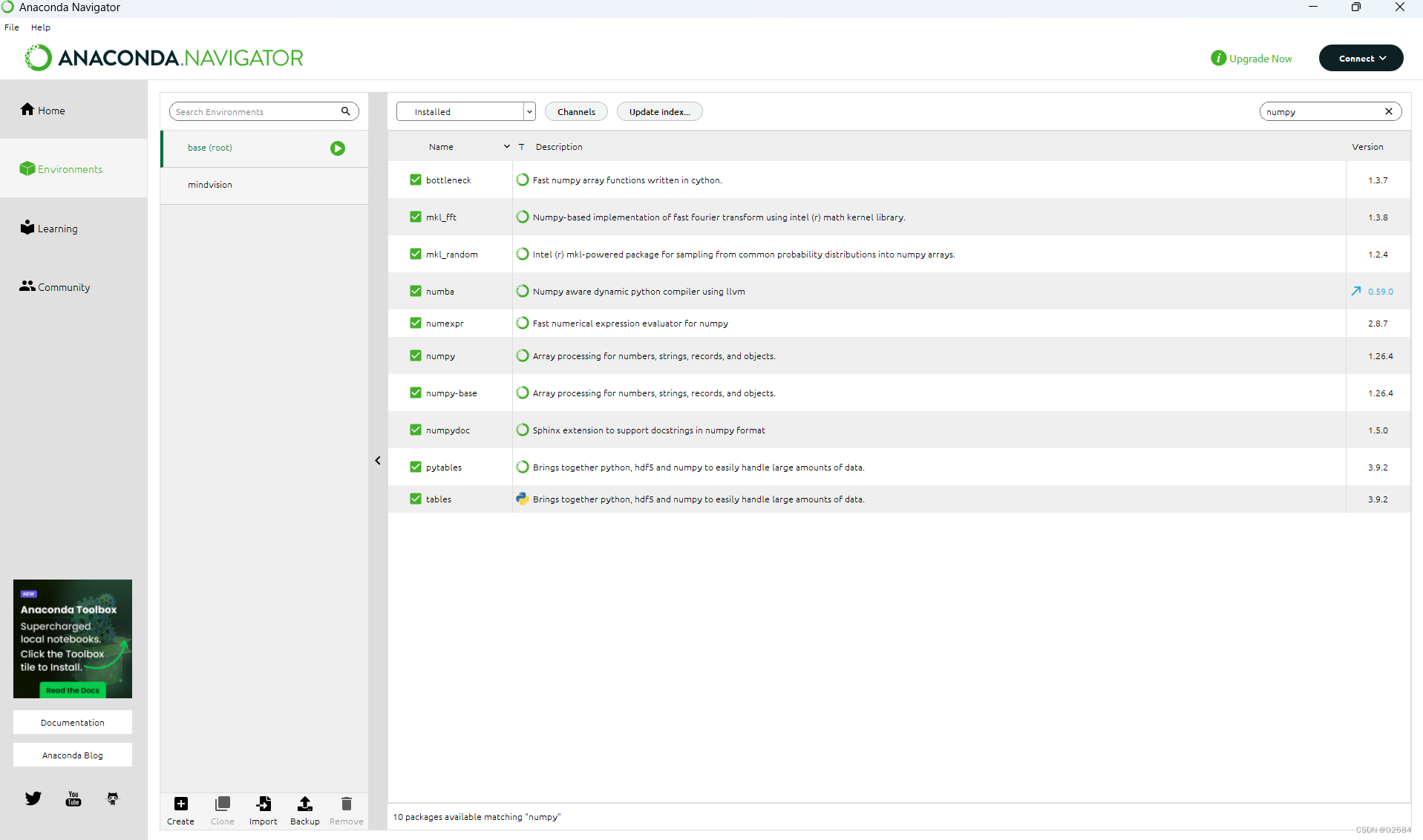
比如说我们输入numpy,我们可以看到它已经成功的安装。
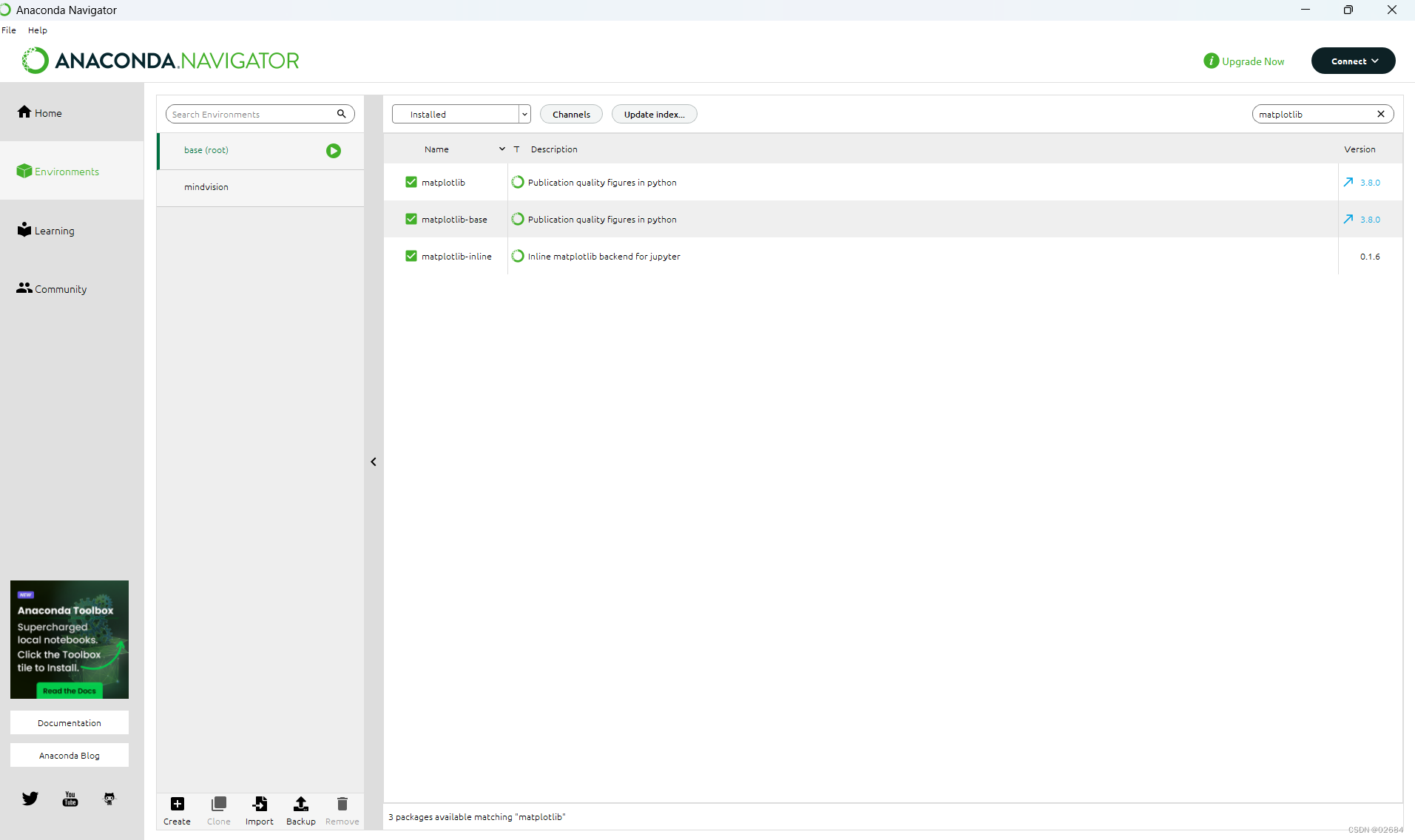
类似的在搜索栏中输入matplotlib和plotly,在最新版本的Anaconda中这两个python包也应该已经被安装好。如下图:
我们创建一个虚拟环境,然后在这个虚拟环境中配置各种各样的包,就可以在这个环境中运行目标程序。例如刚才在base环境中已经安装好了各种各样的包,为了不混淆,我们可以创建一个新的环境,将与科学绘图有关的python包安装在这个环境中。当然继续使用base环境也是可以的。
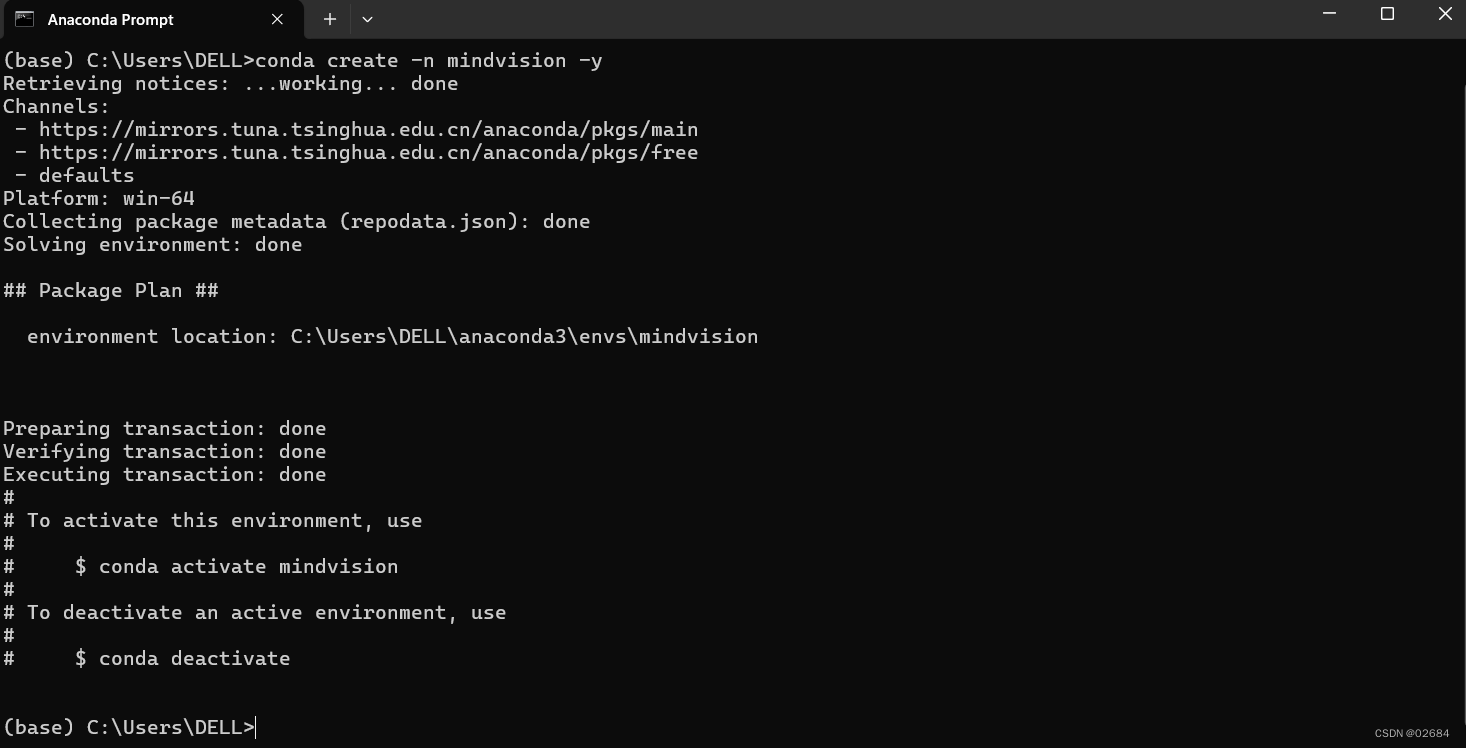
Step1:创建虚拟环境
可以使用如下命令创建环境:
conda create -n 环境名 -y
首先打开Anaconda Prompt,如下图:
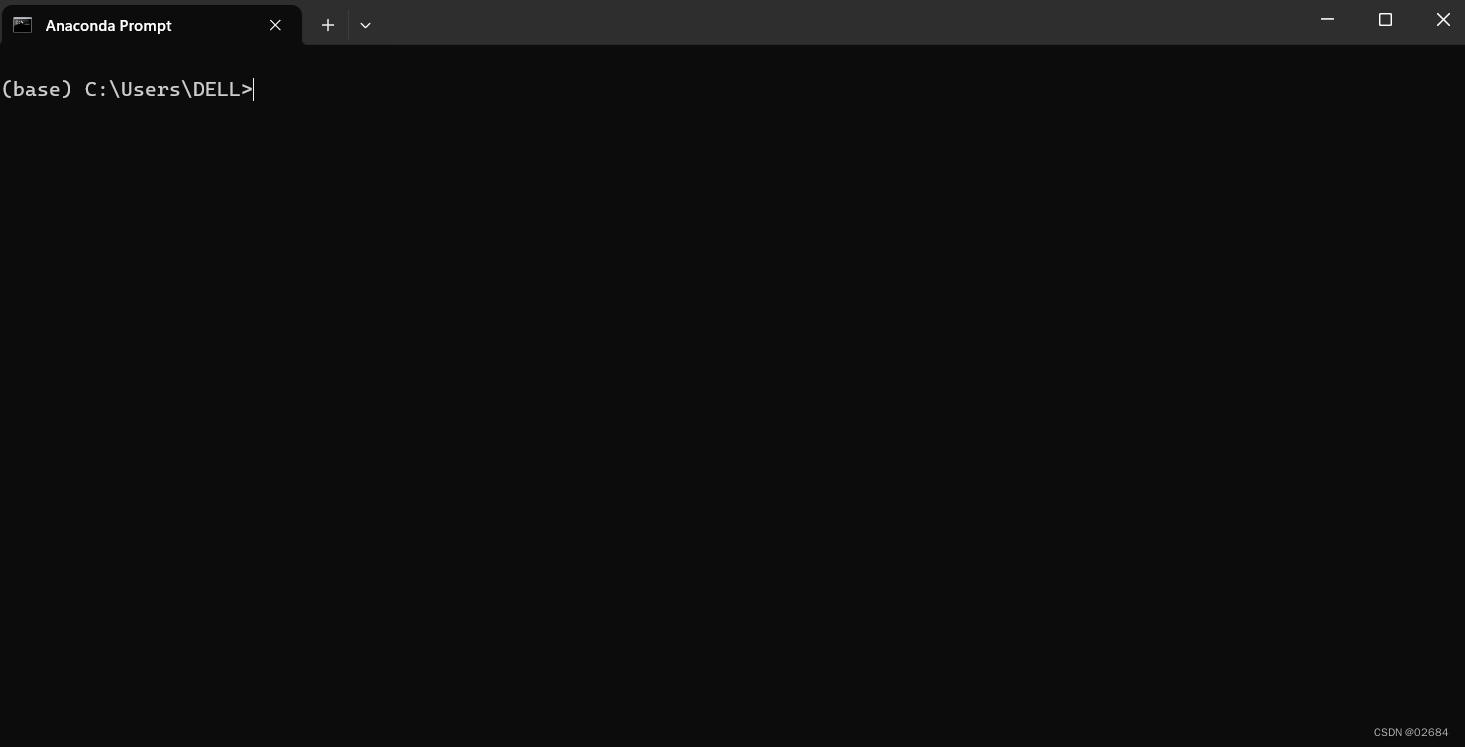
输入conda create -n mindvision -y 创建名为mindvision的环境。
Step2:激活环境
可以使用如下命令激活环境:
conda activate 环境名
输入conda activate mindvision激活mindvision环境。

由此,我们的环境就从base变成了mindvision。
Step3:安装numpy、matplotlib和plotly工具包
拿plotly为例,进入plotly python的官网
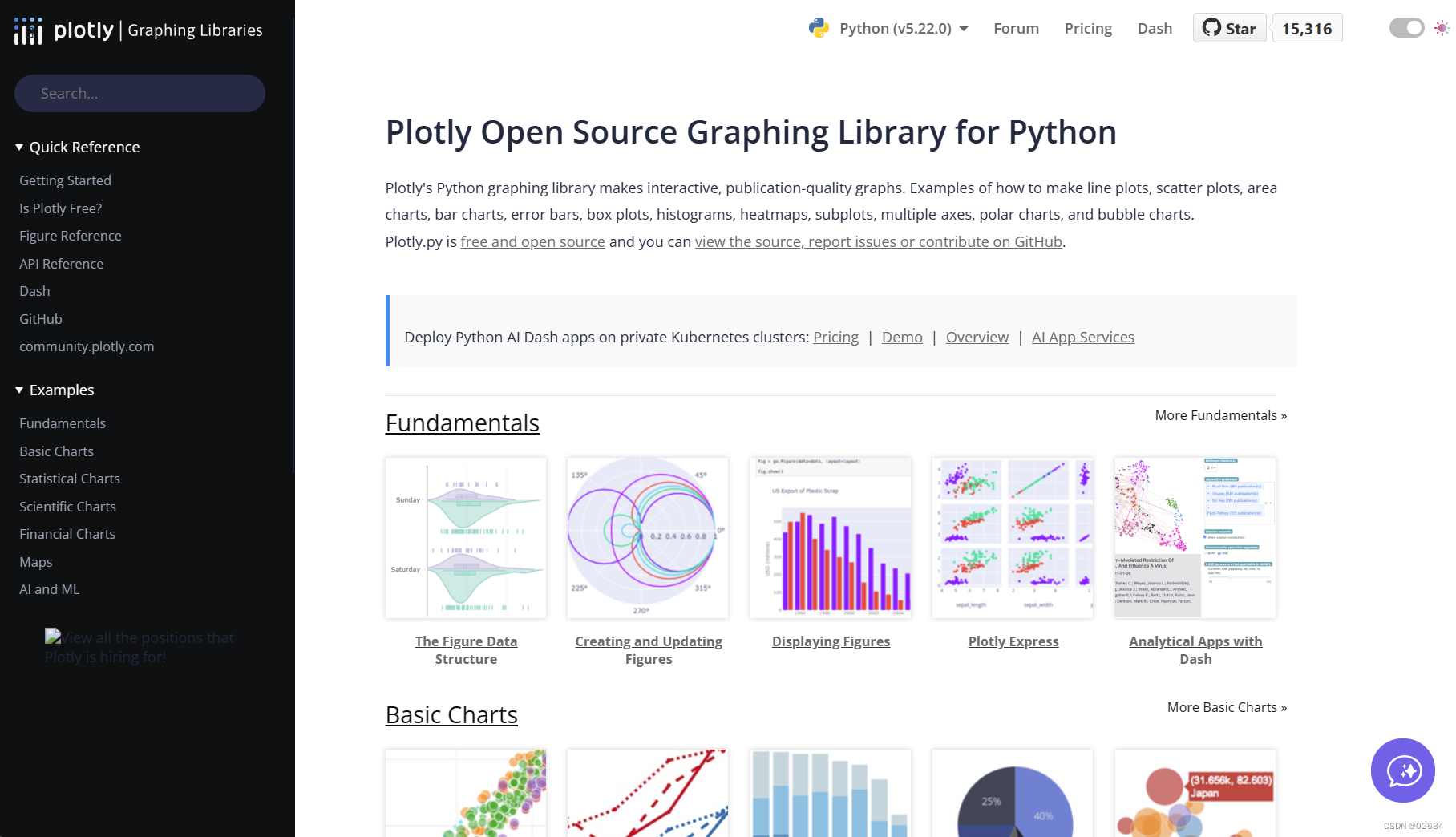
点击左侧Getting started,里面它会告诉你如何安装它。因为我们已经安装了Anaconda,因此我们可以直接使用conda install来安装它。所以直接复制这句话在我们命令行里运行就可以。
显示如下:
输入y,开始安装该工具包,等待一段时间后,安装完成,会显示done的指令。
另外还要安装一些辅助的包,输入conda install -c plotly plotly-orca==1.3.1 psutil命令,安装此包,可以将plotly画出来的图保存在本地文件中。
同理可以进行numpy和matplotlib这两个包的安装。
numpy:https://numpy.org/ link
matplotlib: https://matplotlib.org/ link
plotly:https://plotly.com/python/ link
Step4:检验包是否安装成功
在命令行里输入python进入python运行环境,输入import plotly,发现没有报错说明安装成功,同理输入import numpy和import matplotlib检验numpy和matplotlib包是否安装成功。

二、Visual Studio Code的安装
Visual Studio Code 介绍
Visual Studio Code(简称VS Code)是一个由微软开发的免费、开源的代码编辑器,它支持多种编程语言的语法高亮、智能代码完成、括号匹配、代码缩进、代码片段、代码对比差异、Git 控制等功能。它还可以通过安装扩展来支持更多语言和工具,非常适合用于Python开发和其他编程活动。
进入官网安装
Visual Studio Code 官网
https://code.visualstudio.com link
打开 Visual Studio Code,进入extension(扩展)界面

安装Chinese插件并应用,再找到python的插件然后install就可以了。
这样Python安装与环境配置就成功了
TIPS:多看官网的demo,也就是实例。
Part2:numpy数组与Pandas DataFrame
Python中有两种常用数据类型——numpy数组与Pandas DataFrame。它们既是Python中数据分析的基础工具,也是Python中储存数据的主要手段。
一、Numpy 数组
1、导入库
打开一个空的Python文件,并使用import命令导入numpy

其中,as np是numpy的缩写,可以使用其他缩写或者不缩写。
2、利用zeros创建数组
第一种创建numpy数组的命令是zeros。
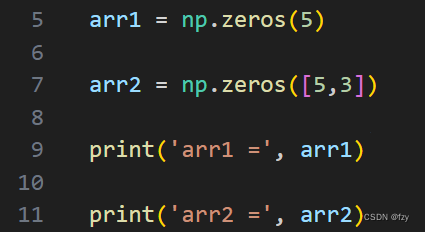
np.zeros表示创建元素都为0的数组。数组可以是一维的,也可以是多维的。如图所示,第一行表示创建一个长度为5,元素全为0的一维数组,而第二行表示创建一个5行3列,且元素均为0的二维数组。使用print命令输出两个数组,得到如下图结果:
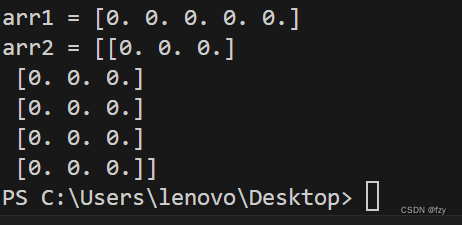
可以看到,arr1与arr2的所有元素均为0。
3、定义数组的数据类型
在此基础上,我们给数组传入一个额外的参数,即dtype=数据类型,来定义数组的数据类型

在这里我们定义数组arr2的数据类型为整型。
再次打印数组,得到结果如下:
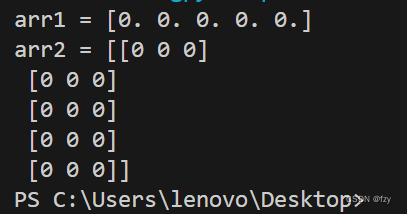
我们看到,第二个数组的元素由原先的0.变为0,说明数组的数据类型变成了整型。
4、使用array创建数组
第二种创建数组的方法是使用array函数。
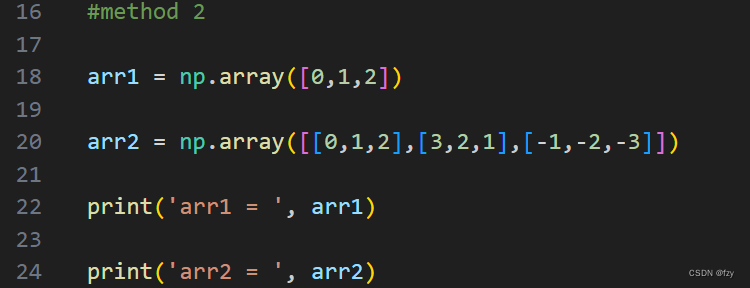
使用np.array命令可直接创建数组,并且可以对数组进行初始化操作。如上图所示,第一个数组长度为3,元素数值为0,1,2,而第二个数组为3行3列二维数组。上述数组的初始化方式与C++类似,只是符号形式不同。
打印上述数组,得到如下结果:
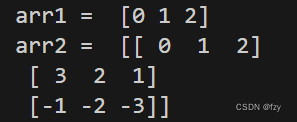
5、数组的shape
Numpy数组有个重要属性shape,arr.shape命令表示返回数组的形状。

在这里,我们输出数组arr2的形状,得到结果如下:

我们看到,arr2.shape表示返回整个数组的形状,其中第一个元素表示数组的行数,第二个元素表示数组列数。arr2.shape[0]表示返回数组的行数,arr2.shape[1]表示返回数组列数,通过手动添加数组arr2的行数并进行相同的输出操作可证明这一点。
6、arange函数创建数组
第三种创建numpy数组的方法是调用arange函数,np.arange命令表示生成一维递增数组。

其中,第一个参数表示数组的开始值,第二个参数表示数组的结束值。
那么,如何调整数组递增的快慢呢?这就需要第三个参数—步长,来实现这一点。步长是指数组单次递增的数值。默认情况下数组默认步长为1。
输出这个数组,得到如下结果:

通过输出结果可以验证,默认情况下数组的步长为1.
将步长设置为0.5

并打印数组得到如下结果:

从中看到,数组步长被修改为0.5.
值得注意的一点是,如果结束值与开始值之差为步长的整数倍时,结束值不会被包括在生成数组之中。这时,只需微调数组的结束值,如将结束值从10改为10.001,就可以包括原先的结束值10.
7.调用linspace函数创建数组
np.linspace()命令表示给定上下限和元素个数的一维数组。下面我们用一个示例来说明这一点。
调用linspace函数创建数组如下:

其中,前两个参数与arange相同,各自代表数组的开始值与结束值。与arange函数不同的是,第三个参数表示数组的长度。根据这三个参数,计算机会计算出步长,自动生成线性递增的数组。
此外,利用linspace函数创建的数组中还有第四个参数,即endpoint。Endpoint表达的含义是是否包括数组的结束值。Endpoint类似C++中的布尔数据类型,有true与false两种取值,其中true指生成的数组包含结束值,false则相反。
下面是示例代码:

打印数组,得到如下结果:

将endpoint的取值改为False,得到如下结果:

可以看到,第一个数组包含了结束值10,而第二个数组未包含。
注:numpy数组的数据类型可以是混合类型,此时dtype设置成对象,即object类型即可。
二、Pandas DataFrame的数据结构
Pandas是一个基于numpy的python包,适合于进行统计工作。Dataframe是Pandas的基本数据类型,可通俗理解为二维numpy数组的加强版。它的特点是会对二维数组的每一行加上一个index,即索引号。同样,它也会对二维数组每一列加上一个label,即标签。
使用import命令导入numpy和Pandas,其中“as np”和”as pd”为numpy和Pandas的缩写,可以使用别的缩写或者不写。
1、利用二维numpy数组创建DataFrame。
下面以一个学生的数学、英语成绩统计为例讲解这个方法。
我们手动输入一个二维numpy数组如下:

我们创建了一个3*3二维数组。其中,每行的第一个元素是字符串,表示姓名;每行的后两个元素是数字,表示学生的数学与英语成绩。
然后调用DataFrame函数并传入数组,代码格式如下:

注:index为行的编号,默认值为0,1,2…… Columns为每一列的名称
打印数组及其标签

得到输出如下所示:
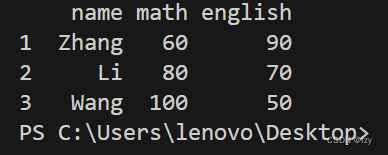
可以看到,输出结果类似于表格。其中,左侧“1,2,3”数字为每一行的编号,name,math,english为每一列的标签。
2.使用dict()对象创建DataFrame
dict()是字典数据类型,是Python中自带的数据类型。dict数据类型包含了一个个独立的标签,对应于二维numpy数组中的列。其基本语法结构如下:

我们用dict()对象创建前述相同数组

使用print(arr)输出,得到了相同的输出结果。
Part3:绘制简单曲线
一、 图片对象的基本操作
-
导入所需模块
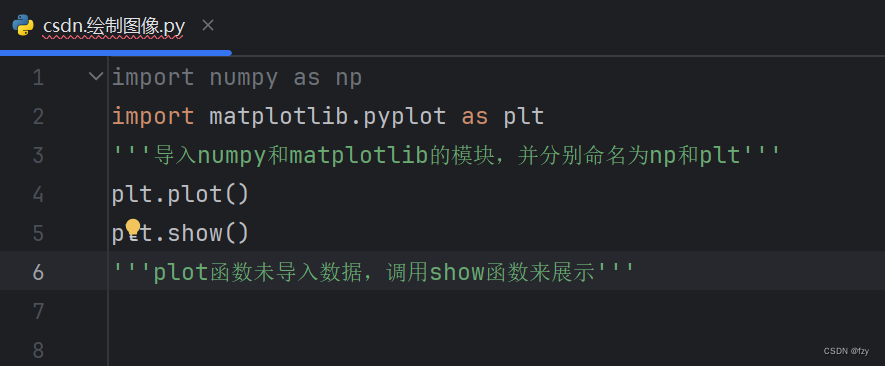
-
直接调用plot和show
可得到如下图片,快速但不方便管理
- 绘制并保存图片到相应路径
也可在创建图片对象是改变其大小,如图
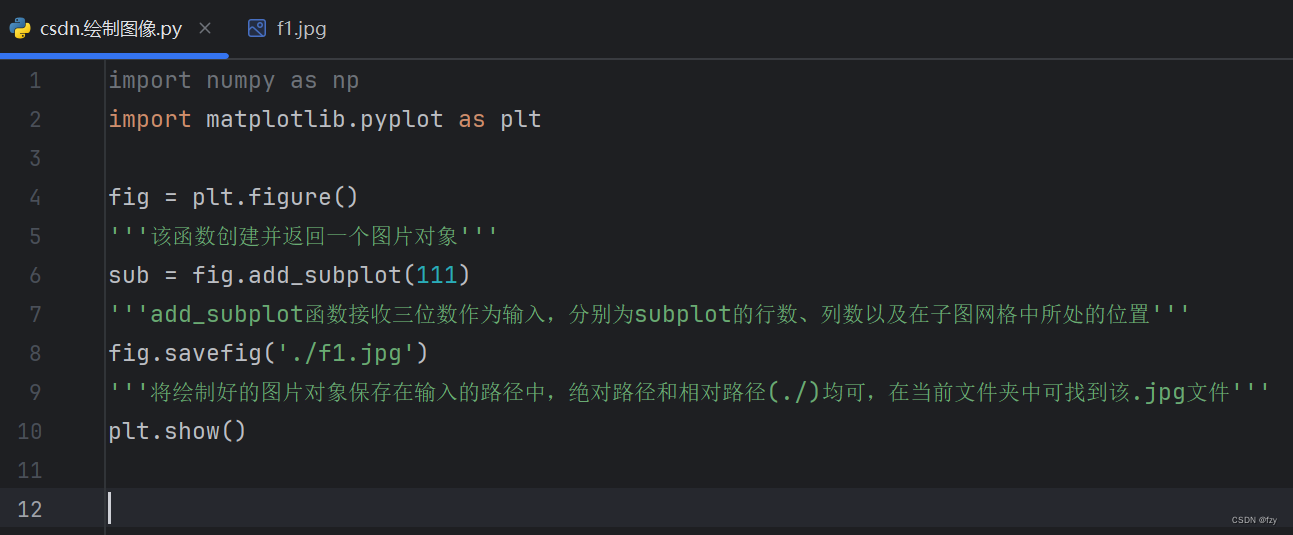
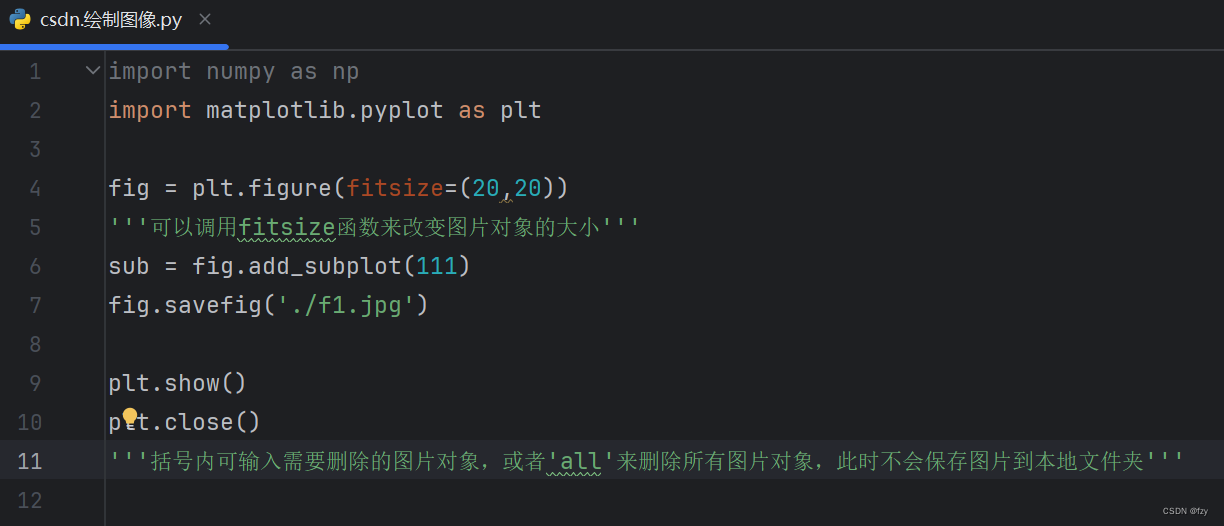
运行一下程序得到一张图片
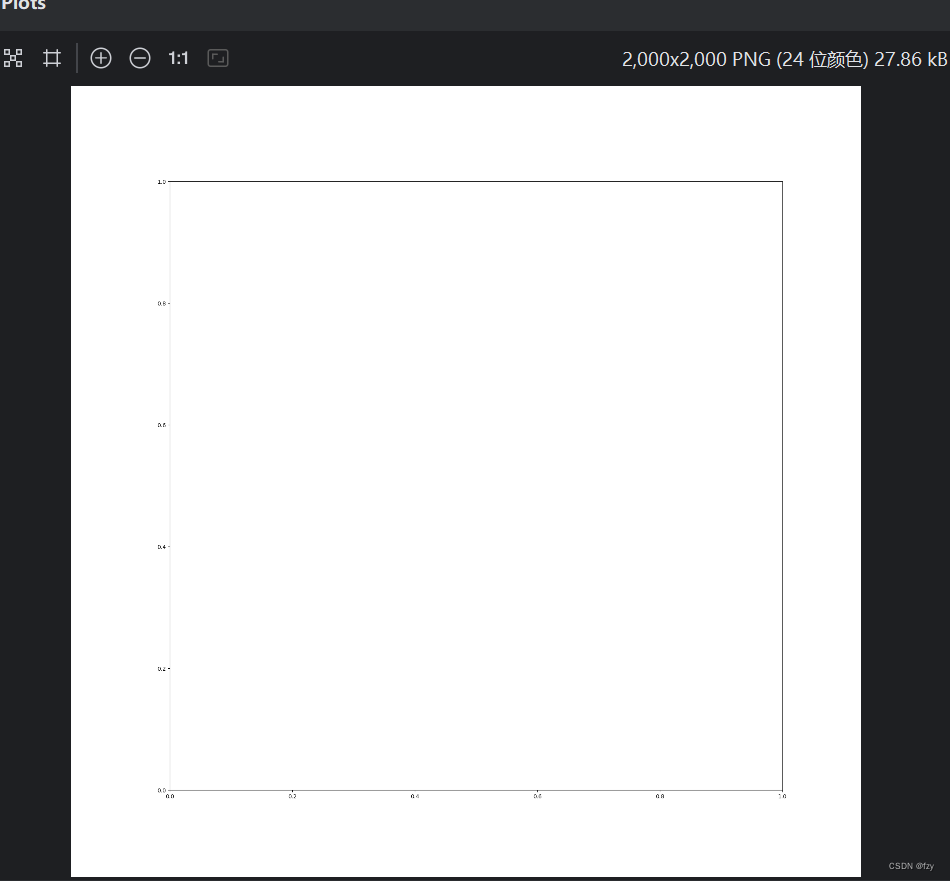
并保存到了输入的图片路径中
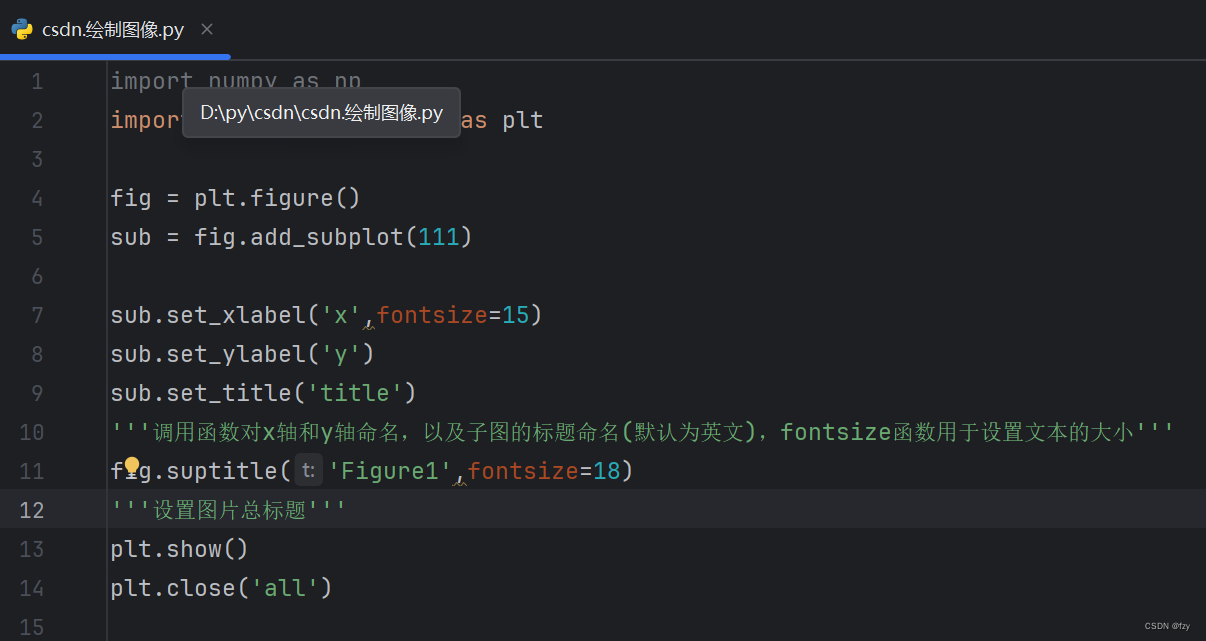
二、设置坐标轴标签及图片标题
x轴和y轴名称及大小,以及子图名称图片总标题(均默认为英文)
三、绘制基本函数
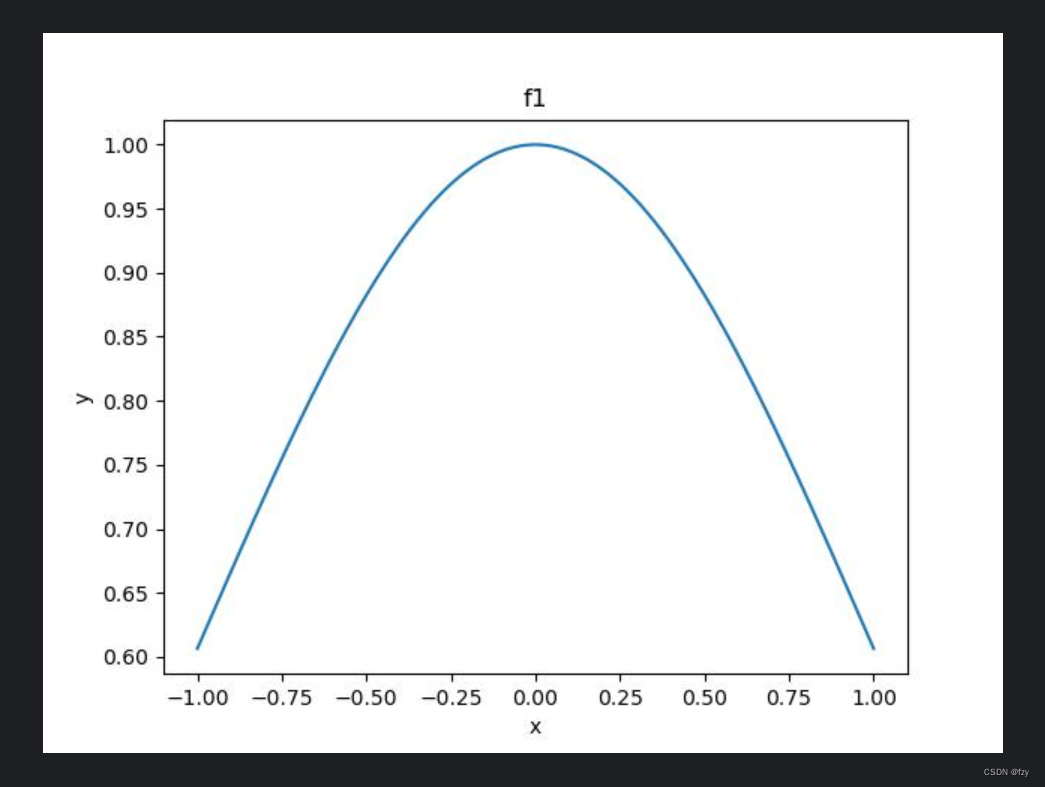
- 绘制高斯函数的图像
运行一下代码,即可得到范围为[-1,1]的高斯分布曲线
四、 读取文本文件
接下来我们实践如何从一个文本文件中接收一个二维数组,并将其绘制在坐标图上
-
创建txt文本
将已经创建好的Excel表格另存为.txt文本文件,并保存在.py的当前文件夹中

-
在当前文件夹的.py文件中编写代码
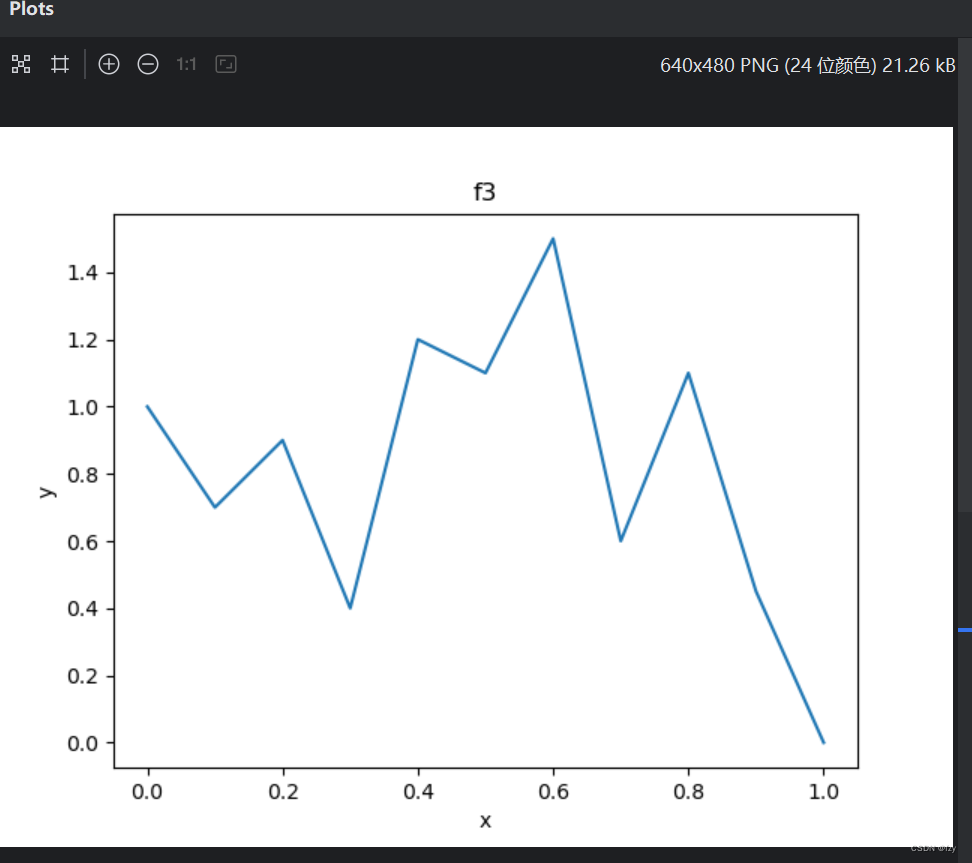
-
运行程序















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









