






文章目录
最近写英语作业,写完了发现很多标记的单词,查词的过程中一个一个的翻词典,打字手机查,特别麻烦,于是就有了下列代码…
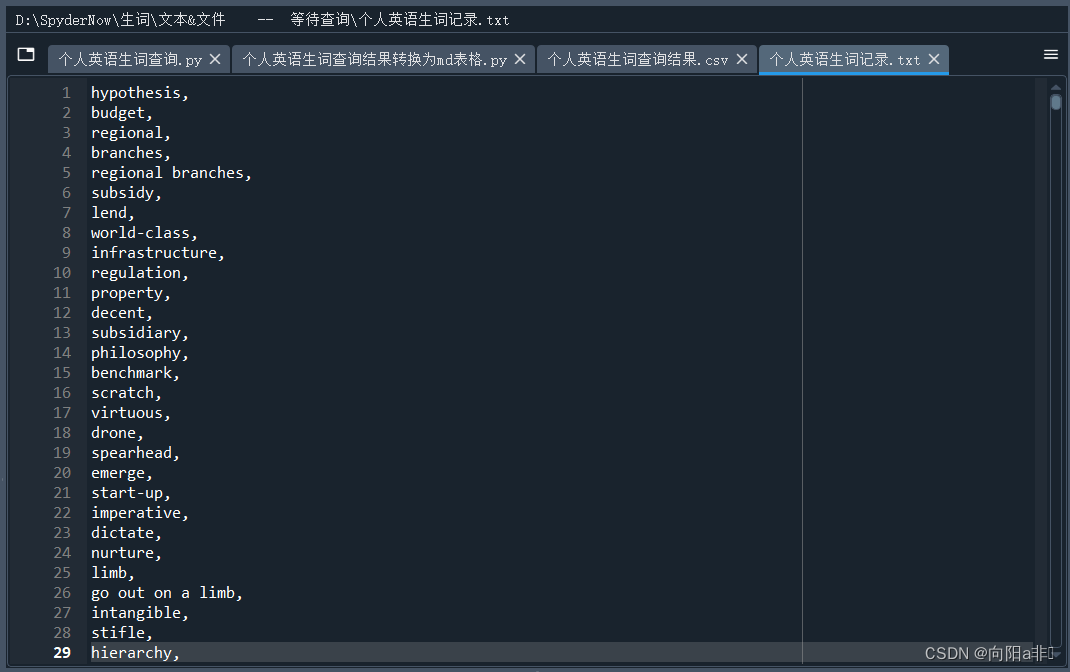
生词查询 :个人生词记录
| 生词列表 |
|---|
| hypothesis |
| budget |
| regional |
| branches |
| regional branches |
| subsidy |
| lend |
| world-class |
| infrastructure |
| regulation |
| property |
| decent |
| subsidiary |
| philosophy |
| benchmark |
| scratch |
| virtuous |
| drone |
| spearhead |
| emerge |
txt文件中内容、格式如下,
生词查询 :20000词频Excel资料
Excel文件中内容、格式如下(后用md列表表示,因其具有良好的嵌入性,下同),
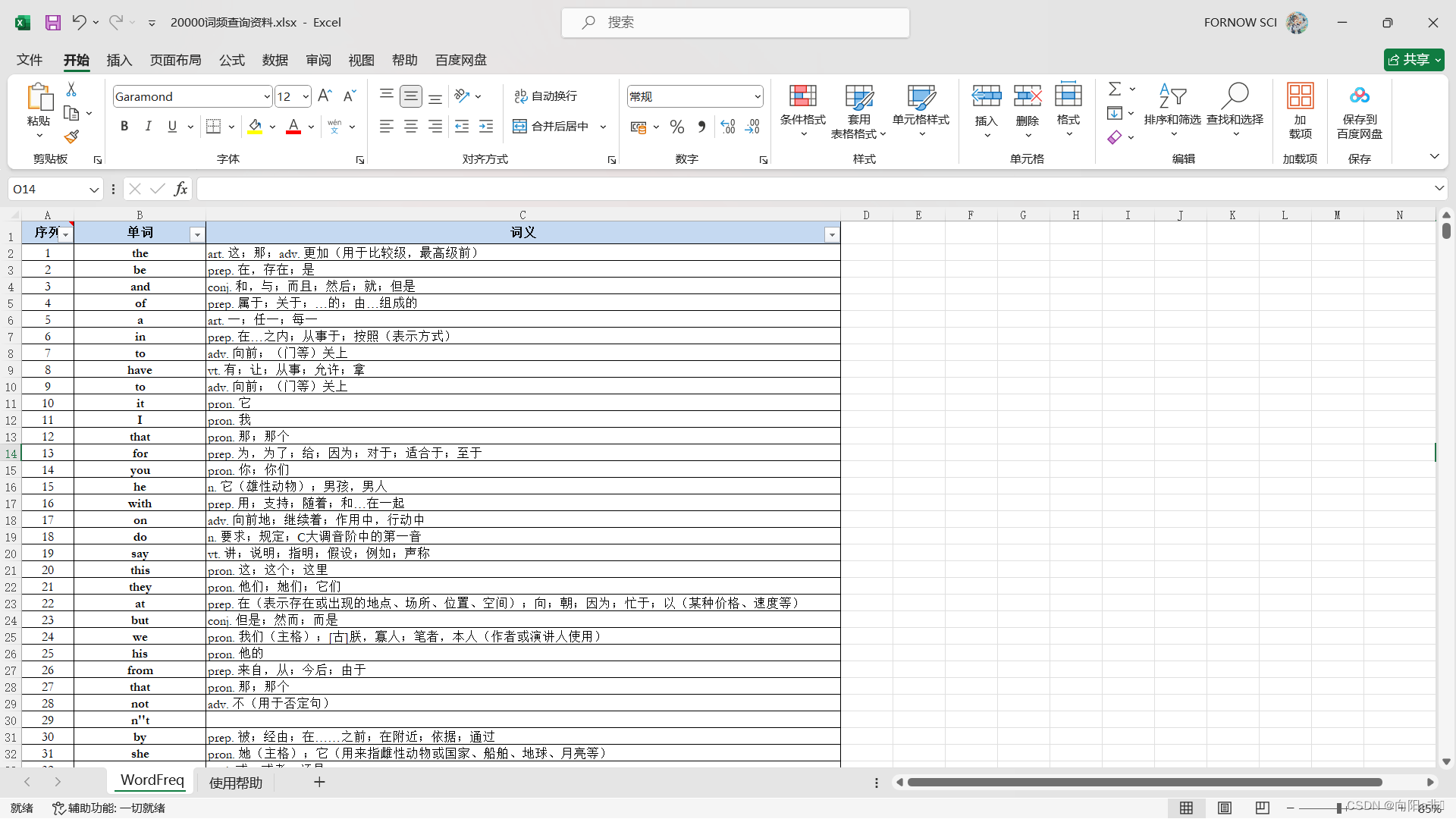
| 序列 | 单词 | 词义 |
|---|---|---|
| 1 | the | art. 这;那;adv. 更加(用于比较级,最高级前) |
| 2 | be | prep. 在,存在;是 |
| 3 | and | conj. 和,与;而且;然后;就;但是 |
| 4 | of | prep. 属于;关于;…的;由…组成的 |
| 5 | a | art. 一;任一;每一 |
| 6 | in | prep. 在…之内;从事于;按照(表示方式) |
| 7 | to | adv. 向前;(门等)关上 |
| 8 | have | vt. 有;让;从事;允许;拿 |
| 9 | to | adv. 向前;(门等)关上 |
| 10 | it | pron. 它 |
| 11 | I | pron. 我 |
| 12 | that | pron. 那;那个 |
| 13 | for | prep. 为,为了;给;因为;对于;适合于;至于 |
| 14 | you | pron. 你;你们 |
| 15 | he | n. 它(雄性动物);男孩,男人 |
| 16 | with | prep. 用;支持;随着;和…在一起 |
| 17 | on | adv. 向前地;继续着;作用中,行动中 |
| 18 | do | n. 要求;规定;C大调音阶中的第一音 |
| 19 | say | vt. 讲;说明;指明;假设;例如;声称 |
| 20 | this | pron. 这;这个;这里 |
生词查询 :python代码
import pandas as pd
def read_and_query_unknown_words(excel_file_path, txt_file_path, output_file_path):
"""
读取Excel文件和文本文件,查询生词信息,并保存到CSV文件中。
Parameters:
excel_file_path (str): Excel文件路径。
txt_file_path (str): 文本文件路径。
output_file_path (str): 输出CSV文件路径。
"""
# 读取xlsx文件
df = pd.read_excel(excel_file_path)
# 读取txt文件内容
with open(txt_file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 获取生词列表,去除空格,统一小写,进行去重
unknown_words = list(set([word.strip().lower() for word in content.split(',')]))
# 统一Excel中的单词格式
df['单词'] = df['单词'].str.strip().str.lower()
# 在20000词频资料文件中查找个人生词信息
unknown_words_info = df[df['单词'].isin(unknown_words)]
# 输出查询结果
save_query_results(unknown_words_info, output_file_path)
def save_query_results(dataframe, output_file_path):
"""
保存查询结果到CSV文件。
Parameters:
dataframe (pandas.DataFrame): 要保存的数据。
output_file_path (str): 输出文件路径。
"""
dataframe.to_csv(output_file_path, index=False, encoding='utf-8-sig')
print(f"查询结果已保存到 {output_file_path}")
# 获取文件路径&&定义输出路径
excel_file_path = r'../生词/文本&文件 -- 等待查询/20000词频查询资料.xlsx'
txt_file_path = r'../生词/文本&文件 -- 等待查询/个人英语生词记录.txt'
output_file_path = r'../生词/词义&音标 -- 查询结果/个人英语生词查询结果.csv'
# 调用函数
read_and_query_unknown_words(excel_file_path, txt_file_path, output_file_path)
生词查询 :输出结果,csv文件
| 序列 | 单词 | 词义 |
|---|---|---|
| 304 | president | n. 总统;校长;董事长 |
| 443 | former | adj. 从前的,前者的;前任的 |
| 445 | major | adj. 主要的;主修的;重要的;较多的 |
| 454 | economic | adj. 经济的,经济上的;经济学的 |
| 567 | land | n. 陆地;地面;国土 |
| 584 | simply | adv. 简单地;朴素地;简直;仅仅;坦白地 |
| 606 | century | n. 世纪,百年;(板球)一百分 |
| 625 | likely | adj. 很可能的;合适的;有希望的 |
| 641 | campaign | vi. 作战;参加活动;参加竞选 |
| 658 | defense | n. 防卫,防护;防御措施;防守 |
| 670 | subject | n. 主题;科目;国民;主语 |
| 739 | scene | n. 情景;景象;场面;事件 |
| 778 | success | n. 成功,成就;胜利;大获成功的人或事物 |
| 781 | particularly | adv. 特别地,独特地;详细地,具体地;明确地,细致地 |
| 784 | staff | n. 职员;支撑;参谋;棒 |
| 799 | pretty | adj. 漂亮的;可爱的;优美的 |
| 814 | analysis | n. 分析;分解;验定 |
| 830 | financial | adj. 财政的,财务的;金融的 |
| 835 | authority | n. 权威;权力;当局 |
| 847 | strategy | n. 战略,策略 |
生词查询 :输出结果,转换为md文件python代码
import pandas as pd
def convert_csv_to_markdown_list(input_file_path, output_file_path):
"""
从CSV文件中读取数据并将其转换为Markdown格式的列表,然后写入MD文件。
Parameters:
input_file_path (str): 输入CSV文件路径。
output_file_path (str): 输出MD文件路径。
"""
# 读取CSV文件
df = pd.read_csv(input_file_path)
# 将Markdown列表写入MD文件
with open(output_file_path, 'w', encoding='utf-8') as md_file:
md_file.write("序列 | 单词 | 词义\n")
md_file.write("----- | ----- | -----\n")
for index, row in df.iterrows():
md_file.write(f"{row['序列']} | {row['单词']} | {row['词义']}\n")
print(f"Markdown表格已写入 {output_file_path}")
# 获取文件路径&&定义输出路径
input_file_path = r'../生词/词义&音标 -- 查询结果/个人英语生词查询结果.csv'
output_file_path = r'../生词/MarkDown -- 文本转换/个人英语生词查询结果.md'
# 调用函数
convert_csv_to_markdown_list(input_file_path, output_file_path)
生词查询 :同时执行两个py文件
import subprocess
def run_script(script_path):
try:
result = subprocess.run(['python', script_path], check=True, capture_output=True, text=True)
print(f"Script {script_path} executed successfully.")
print("Output:\n", result.stdout)
except subprocess.CalledProcessError as e:
print(f"Error executing script {script_path}.")
print("Error message:\n", e.stderr)
if __name__ == "__main__":
scripts = [
r"../生词/个人英语生词查询.py",
r"../生词/个人英语生词音标查询结果转换为md表格.py"
]
for script in scripts:
run_script(script)
















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











