







 本文介绍了分治法的基本概念、特征及其实现过程,通过汉诺塔、快速幂和快速排序三个例子详细展示了分治法的分解、解决和合并步骤,探讨了分治法在优化算法复杂度中的作用。
本文介绍了分治法的基本概念、特征及其实现过程,通过汉诺塔、快速幂和快速排序三个例子详细展示了分治法的分解、解决和合并步骤,探讨了分治法在优化算法复杂度中的作用。
分治法的介绍
当我们遇到一个难以直接解决的大问题时,自然会想到把它划分成一些规模较小的子问题,各个击破,“分而治之(DivideandConquer)”。分治算法的具体操作是把原问题分成k个较小规模的子问题,对这k个子问题分别求解。如果子问题不够小,那么把每个子问题再划分为规模更小的子问题。这样一直分解下去,直到问题足够小,很容易求出这些小问题的解为止。
能用分治法的题目,需要符合以下两个特征。
(1)平衡子问题:子问题的规模大致相同。能把问题划分成大小差不多相等的k个子问题,一般k=2,即分成两个规模相等的子问题。子问题规模相等的处理效率,比子问题规不等的处理效率要高。
(2)独立子问题:子问题之间相互独立。这是区别于动态规划算法的根本特征,在动见划算法中,子问题是相互联系的,而不是相互独立的。
需要注意的是,分治不仅可以能够让问题更理解和解决,而且常常能大大优化算法的复杂度,如果把O(n)的复杂度优化到O(log2n)。这是因为局部优化有利于全局;一个子问题的解决,其影响力扩大了k倍,即扩大到了全局。
举一个简单的例子,在一个有序的数列中查找一个数。简单的方法是从头找到尾,复杂度为O(n)。如果用分治法,即“折半查找”,最多只需要O(log2n)次就能找到。这个方法是二分法,二分法也就是分治法,只是二分法的应用场合非常简单。
分治法的思想,几乎就是递归的过程,用递归程序实现分治法是很自然的。
用分治法建立模式时,解题步骤分为一下3步。
(1)分解(Divide):把问题分解成独立的子问题。
(2)解决(Conquer):递归解决子问题。
(3)合并(Combine):把子问题的结果合并成原问题的解分治法的经典应用有汉诺塔、归并排序、快速排序等。
汉诺塔和快速幂
下面用汉诺塔和快速幂这两个简单例子说明分治法的思路。
汉诺塔
问题描述:
汉诺塔是一个古老的数学问题:有3根杆子A,B,C。A杆上有N个(N>1)穿孔圆盘,盘的尺寸由下到上依次变
小。要求按下列规则将所有圆盘移至C杆:每次只能移动一个圆盘;大盘不能叠在小盘上面(提示:可将圆盘临时
置于B杆,也可将从A杆移出的圆盘重新移回A杆,但都必须遵循上述两条规则)。问:如何移动?最少要移动多
少次?
输入:
输入两个正整数,一个是N(N≤15),表示要移动的盘子数;一个是M,表示在最少移动步骤的第M步。
输出:
共输出两行。第1行输出格式为:#No:a->b,表示第M步骤具体移动方法,其中No表示第M步移动的盘子的编号
(N个盘子从上到下依次编号为1~N),表示第M步是将No号盘子从a杆移动到b杆(a和b的取值均为(A、B、C))。
第2行输出一个整数,表示最少移动步数。
输入样例:
3 2
输出样例:
#2:A->B
7
汉诺塔的经典解法是分治法。汉诺塔的逻辑很简单:把n个盘子的问题分治成两个子问题。
设有x、y、z3根杆子,初始的n个盘子在x杆上。
(1)把x杆的n一1个小盘移动到y杆(把这n-1个小盘看作一个整体),然后把第n个大盘移动到z杆;
(2)把y杆上的n-1个小盘移动到z杆。
在下面代码中,第10行和第13行hanoi()函数完成了分治任务。
分析代码的复杂度。每次分治,分成两部分,以两倍递增:一分为二,二分为四,四分为八,…,复杂度为O(2n)。在汉诺塔中,分治法不能降低复杂度。
代码
#include<bits/stdc++.h>
using namespace std;
int sum=0,m;
void hanoi(char x,char y,char z,int n)
{
if(n==1) {
sum++;
if(sum==m) cout<<"#"<<n<<":"<<x<<"->"<<y<<endl;
}
else{
hanoi(x,z,y,n-1);
sum++;
if(sum==m) cout<<"#"<<n<<":"<<x<<"->"<<z<<endl;
hanoi(y,x,z,n-1);
}
}
int main()
{
int n;
cin>>n>>m;
hanoi('A','B','C',n);
cout<<sum<<endl;
return 0;
}
快速幂
幂运算an,即n个a相乘。快速幂就是高效地计算出an。当n很大时,如n=109,如果用暴力的方法计算an,即逐个做乘法,复杂度为O(n),即使能算出来,也会超时。
代码
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
LL fastpow(LL a,LL n,LL m)
{
if(n==0) return 1;
if(n==1) return a;
LL temp=fastpow(a,n/2,m);
if(n%2==1) return temp*temp*a%m;
else return temp*temp%m;
}
int main()
{
LL a,n,m;
cin>>a>>n>>m;
cout<<fastpow(a,n,m)<<endl;
return 0;
}
一般不会使用这个方法求快速幂,而是使用基于二进制的倍增。
快速排序
问题描述
问题描述
给定你一个长度为 n 的整数数列。
请你使用快速排序对这个数列按照从小到大进行排序。并将排好序的数列按顺序输出。
输入格式
输入共两行,第一行包含整数 n。
第二行包含 n个整数(所有整数均在 1∼109范围内),表示整个数列。
输出格式
输出共一行,包含 n个整数,表示排好序的数列。
数据范围
1≤n≤100000
输入样例:
5
3 1 2 4 5
输出样例:
1 2 3 4 5
思路
- 首先设定一个分界值(基准值),通过该分界值将数组分成左右两部分。
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
- 左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
建议这个初学者可以自己手动模拟下代码,加深印象。
代码
#include<bits/stdc++.h>
using namespace std;
const int N=100010;
int a[N];
// 快速排序函数
void quick_sort(int a[],int l,int r)
{
// 如果左边界大于等于右边界,直接返回
if(l>=r) return;
// 初始化指针i和j,以及基准值x
int i=l-1,j=r+1,x=a[l+r>>1];
// 当i<j时,进行循环
while(i<j)
{
// 从左向右找到第一个大于等于基准值的元素
do i++;while(a[i]<x);
// 从右向左找到第一个小于等于基准值的元素
do j--;while(a[j]>x);
// 如果i<j,交换a[i]和a[j]的值
if(i<j) swap(a[i],a[j]);
}
// 对左半部分进行快速排序
quick_sort(a,l,j);
// 对右半部分进行快速排序
quick_sort(a,j+1,r);
}
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
quick_sort(a,0,n-1);
for(int i=0;i<n;i++) cout<<a[i]<<" ";
return 0;
}
归并排序
先思考一个问题:如何用分治思想设计排序算法?
根据分治法的分解、解决、合并三步骤,具体思路如下。
(1)分解。把原来无序的数列分成两部分;对每部分,再继续分解成更小的两部分···在归并排序中,只是简单地把数列分成两半。在快速排序中,是把序列分成左右两部分,左部分的元素都小于右部分的元素;分解操作是快速排序的核心操作。
(2)解决。分解到最后不能再分解,排序
(3)合并。把每次分开的两部分合并到一起。归并排序的核心操作是合并,其过程类似于交换排序。快速排序并不需要合并操作,因为在分解过程中,左右部分已经是有序的。
图中给出了归并排序的操作步骤。初始数列经过3次归并之后,得到一个从小到大的有序数列。
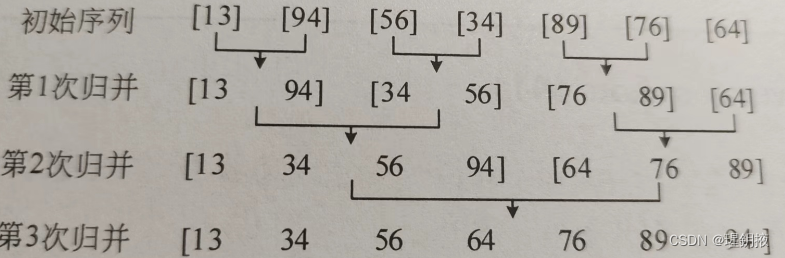
分析图2中归并排序的主要操作如下。
(1)分解。把初始序列分成长度相同的左右两个子序列,然后把每个子序列再分成更小的两个子序列,直到子序列只包含一个数。这个过程用递归实现,图2.16中的第1行是初始序列,每个数是一个子序列,可以看成递归到达的最底层。
(2)求解子问题,对子序列排序。最底层的子序列只包含一个数,其实不用排序。
(3)合并。归并两个有序的子序列,这是归并排序的主要操作,过程如下图所示。例如,图(a)中,i和j分别指向子序列{13,94,99}和{34,56}的第1个数,进行第1次比较,发现a[i]<a[j],把a[i[放到临时空间b[]中。总共经过4次比较,得到b[]=13,34,56,94,99)。
下面分析归并排序的计算复杂度。对n个数进行归并排序:①需要log2n次归并;②在每次归并中,有很多次合并操作,一共需要O(n)次比较。所以计算复杂度为O(nlog2n)。
由于需要一个临时的b存储结果,所以空间复杂度为O(n)。

代码
#include<bits/stdc++.h>
using namespace std;
const int N=100010;
int a[N],tmp[N];
//归并排序函数
void merge_sort(int a[],int l,int r)
{
// 如果左边界大于等于右边界,说明已经排序完成,直接返回
if(l>=r) return;
// 计算中间位置
int mid=l+r>>1;
// 递归对左右两部分进行归并排序
merge_sort(a,l,mid),merge_sort(a,mid+1,r);
int k=0,i=l,j=mid+1;
// 将左右两部分合并到临时数组中
while(i<=mid && j<=r)
if(a[i]<=a[j]) tmp[k++]=a[i++];
else tmp[k++]=a[j++];
// 将左边剩余的元素复制到临时数组中
while(i<=mid) tmp[k++]=a[i++];
// 将右边剩余的元素复制到临时数组中
while(j<=r) tmp[k++]=a[j++];
for(i=l,j=0;i<=r;i++,j++) a[i]=tmp[j];
}
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
merge_sort(a,0,n-1);
for(int i=0;i<n;i++) cout<<a[i]<<" ";
return 0;
}
也可以利用归并排序去求解逆序对的数量。
归并排序步骤:将数组递归地分割为两半,直到每个子数组只有一个元素。然后,将子数组按照排序顺序合并回来,同时在合并过程中计算逆序对。
合并过程中计算逆序对:在合并两个已排序的子数组时,如果发现逆序对(即 arr[i] > arr[j]),则将逆序对的数量递增为第一个子数组中剩余的元素数量(即 (mid - i + 1),其中 mid 是合并的子数组的中间索引)。
这是因为在合并过程中,如果左边的子数组元素 arr[i] 大于右边的子数组元素 arr[j],则 arr[i] 大于右边子数组中的所有元素,形成逆序对。

#include<bits/stdc++.h>
using namespace std;
const int N=100010;
typedef long long LL;
int a[N],tmp[N];
LL merge_sort(int a[],int l,int r)
{
if(l>=r) return 0;
int mid=l+r>>1;
LL res=merge_sort(a,l,mid)+merge_sort(a,mid+1,r); // 递归对左右两部分进行归并排序,并将结果相加
int k=0,i=l,j=mid+1;
while(i<=mid && j<=r)
if(a[i]<=a[j]) tmp[k++]=a[i++];
else
{
res+=mid-i+1;
tmp[k++]=a[j++];
}
while(i<=mid) tmp[k++]=a[i++];
while(j<=r) tmp[k++]=a[j++];
for(i=l,j=0;i<=r;i++,j++) a[i]=tmp[j];
return res;
}
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
cout<<merge_sort(a,0,n-1)<<endl;
return 0;
}















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









