






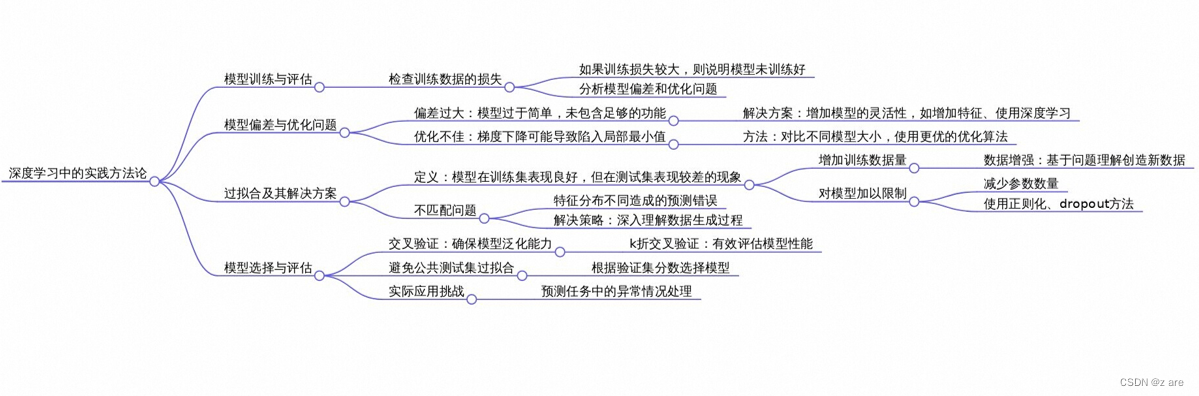
在深度学习中,模型偏差、优化问题和过拟合是我们经常会遇到的挑战。理解这些问题并找到合适的解决方法对于提高模型的性能至关重要。
第一章:模型偏差
1.1 模型过于简单可能导致模型偏差
在应用机器学习算法时,如果模型过于简单,就可能无法包含能够让损失变低的函数。例如,一个有未知参数的函数集合可能太小,无法涵盖最优的函数,导致即使找到了最优的参数,损失仍然不够低。
1.2 增加模型的灵活性可以解决模型偏差问题
为了解决模型偏差问题,可以增加模型的灵活性。具体来说,可以通过增加输入的特征,如使用更多天前的信息来预测未来观看人数;也可以通过使用深度学习来增加模型的灵活性;还可以设置更大的模型。以残差网络为例,比较20层和56层的网络,如果56层的网络灵活性更大,但在训练集上的损失却比20层的网络高,那么可能是优化问题,而不是模型偏差。
第二章:优化问题
2.1 梯度下降可能存在优化问题
一般情况下,我们使用梯度下降进行优化,但这种方法可能会遇到一些问题,比如卡在局部最小值的地方,无法找到一个真正可以让损失很低的参数。即使模型可以表示的函数集合中包含损失低的函数,梯度下降也可能无法找出这些函数。
2.2 可以通过比较不同模型来判断模型是否足够大
为了判断模型是否足够大,可以比较不同的模型。例如,先训练一些比较浅的模型或简单的模型,如线性模型、支持向量机等,了解它们在训练集上的损失。然后再训练深的模型,如果深的模型灵活性更大,但损失却没有比浅的模型压得更低,那么可能是优化有问题,需要寻找更好的优化方法。
第三章:过拟合
3.1 过拟合的原因可能是模型过于复杂
过拟合可能是因为模型的灵活性太大,导致在训练集上表现很好,但在测试集上损失很大。例如,当模型根据有限的训练集数据进行学习时,可能会产生各种各样奇怪的曲线,无法很好地泛化到测试集上。
3.2 可以通过记录训练数据损失并观察测试数据损失来判断是否存在过拟合问题
判断是否存在过拟合问题,可以先记录训练数据的损失。如果训练数据损失小,而测试数据损失大,那么可能是过拟合。解决过拟合的问题,可以增加训练集,通过数据增强的方式创造新的数据;也可以给模型一些限制,如减少参数、使用较少的特征、采用早停、正则化和丢弃法等。同时,要注意选择合适的模型复杂度,避免模型过于简单或过于复杂。
总之,在深度学习中,我们需要关注模型偏差、优化问题和过拟合等问题,并采取相应的措施来提高模型的性能。通过合理地调整模型的灵活性、优化算法和避免过拟合,我们可以更好地训练出有效的深度学习模型。

















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









