







一、随机变量与分布函数
1.随机变量:设是定义在概率空间
上的单值实函数,即对每个
,都有
,并且对任意
,
都是随机事件,即有
则称为概率空间
上的随机变量。通常随机变量
简记为
,而事件
简记为
。
2.设是概率空间
上的随机变量,称函数
为随机变量的概率分布函数,简称为分布函数。通常记为
。
3.概率分布函数的性质:1)单调不减性:若,则
2),且
3)右连续性:在任何点x处右连续。
4.分类:1)离散型随机变量:取值是有限个或像自然数那样无穷可列多个;
2)非离散型随机变量:又可分为连续型随机变量和其它类型随机变量。
二、离散型随机变量及其分布
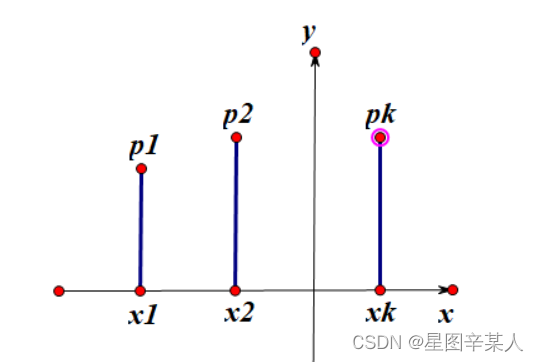
1.设离散型随机变量X的所有可能取值为,而X取值
的概率为
,即
称为离散型随机变量X的概率分布或分布律。把X可能取的值及相应的概率列成表,称为X的概率分布表,或分布列。

随机变量的概率分布是指随机变量所有可能取的值与那些值的概率之间的一种对应关系,这种对应关系可以用解析式、分布列和图示法表示。
2.对于离散型随机变量,概率分布中必须满足下列性质:
1)
2)
反过来,如果满足这两个性质的也一定可以作为某个离散型随机变量的概率分布。
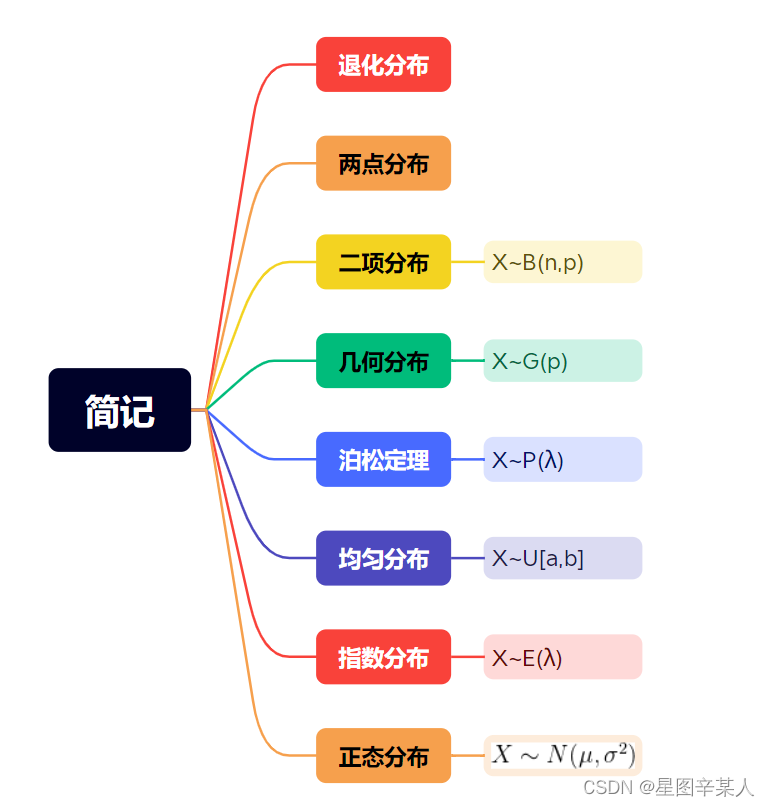
3.几种常见的离散型随机变量:
1)退化分布:
若随机变量X取常数值C的概率为1,即,则称X服从退化分布。
2)两点分布:
设在一次伯努利试验中,,若用X记事件A出现的次数,则X的分布列为

或,
称X服从两点分布或(0-1)分布。
3)二项分布:
在n重伯努利试验中,若事件A出现的次数记为X,随机变量X可能的值是0,1,2,...,n,相应概率分布为
式中,且
,则称X服从参数为n,p的二项分布,记作
.
二项分布的最可能出现次数为。
4)几何分布:
在伯努利试验中,考虑事件A首次出现时的试验次数X的分布。X的所有可能取值是集合,事件
表示A首次出现是在第k次试验,即前k-1次试验都出现
,而第k次试验出现A,这一事件的概率为
上式是几何级数的一般项,因此称为几何分布。记作。显然有
几何分布给出了等待事件A出现共试验了k次的概率。
5)超几何分布:
现有N件产品,其中有M件次品,今从中任取n件(不放回抽取),则这n件中所含的次品数X是一离散型随机变量,其概率分布为
其中。通常称这个概率分布为超几何分布。记作
。
4.泊松定理:
设随机变量服从参数
的二项分布,若
,则有
在实际应用中当就可以使用泊松定理近似地计算二项分布的概率。
5.泊松分布:
如果随机变量X的概率分布为
式中是常数,则称X服从以
为参数的泊松分布,记作
。
自然界中的很多稀疏现象都服从或近似服从泊松分布,所以泊松分布又称为稀疏现象律。
泊松分布的最可能值为,若
为整数,则最可能值为
或
.
三、连续型随机变量及其分布
1.连续型随机变量:在非离散型随机变量中,有一类随机变量可能的取值范围是一个区间或几个区间的并,而且其分布函数可用积分的形式表示。
2.设随机变量X的概率分布函数为,如果存在一个函数
,对于任意的实数x,都有
则称X为连续型随机变量,f(x)为X的概率密度函数,简称为概率密度或密度函数。
3.密度函数f(x)具有性质:1) 2)
满足上述性质的函数f(x)也一定可以作为某一随机变量的概率密度函数。
4. 连续型变量取一特定值a的概率为0,即。
在计算连续型变量落在某一区间内的概率时,不必区分是开区间还是闭区间。
一个事件的概率为0,这个事件不一定是不可能事件。同样一个事件的概率等于1,这个事件也不一定是必然事件。
5.均匀分布:若连续型随机变量X的概率密度函数为
则称X在区间上服从均匀分布,记作
。
服从均匀分布的随机变量X取值落在内任一区间
内的概率与该区间的长度成正比,而与区间的位置无关,即取值在
上是均匀的。
6.指数分布:
若连续型随机变量X的密度函数为
其中为常数,则称X服从参数为
的指数分布,记作
。其分布函数为
指数分布在研究”寿命“一类问题有很重要的应用,这些”寿命“都近似服从指数分布,其中参数表示平均寿命的倒数。
无记忆性:
如果某人年龄已经s岁,则他再存活t年的概率与年龄s无关。
7.正态分布:
若随机变量X的概率密度函数为
其中为常数,且
,则称随机变量X服从参数为
的正态分布,记为
。服从正态分布的随机变量又称为正态变量。
当参数时,正态分布称为标准正态分布,记为
,相应的概率密度函数和分布函数分别特记为
。正态分布又称为高斯分布或者高斯-拉普拉斯分布。
称为位置参数;
称为离散参数,越小函数越陡峭。
当正态函数不是标准化形式时,可以使用来将函数标准化。
四、随机变量函数的分布
设连续型随机变量X具有概率密度函数,其可能的取值范围区间为
,则
若函数在区间
上严格单调,其反函数
具有连续导函数,则
是连续型随机变量,其概率密度函数为
其中。
如果在定义域内不严格单调,可以将定义域分割为多个严格单调的区间再计算。















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









