







文章目录
一、环境的安装
想要训练和自己的数据集和利用模型进行推理,首先要确保自己电脑上已经安装Anconda+cuda+cudnn+pycharm如果已经有可以跳过这一步
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,在这里主要使用它的包管理器conda。
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。而cuDNN是用于深度神经网络的GPU加速库
1. Anaconda的下载和安装
方式一:官网下载
官网链接:https://www.anaconda.com/download/success

方式二:清华镜像下载
如果官网下载不了或者下载的比较慢可以使用下面的链接进行下载
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/

找到自己想要下载的版本即可
下载成功后双击打开安装包,然后一直下一步
安装成功后最关键的地方来了,配置环境变量
首先在电脑搜索框中搜索环境变量 然后依次按图中标的地方打开



到这里进入环境变量页面后只需新建找到自己的安装目录把下面几个文件夹路径添加进去 点击确定保存即可 注意把C:\ProgramData 改为自己的实际安装路径
C:\ProgramData\Anaconda3
C:\ProgramData\Anaconda3\Scripts
C:\ProgramData\Anaconda3\Library\bin
C:\ProgramData\Anaconda3\Library\mingw-w64\bin
之后输入 win+R 输入cmd 打开命令窗 输入 conda info 即可查看自己是否安装并配置环境比变量成功

2. cuda 和cudnn 安装
首先还是win+R 输入cmd 打开命令窗 之后输入 nvidia-smi查询可支持的最高cuda版本,驱动是向下兼容的,所以我推荐安装12.1 版本的就行
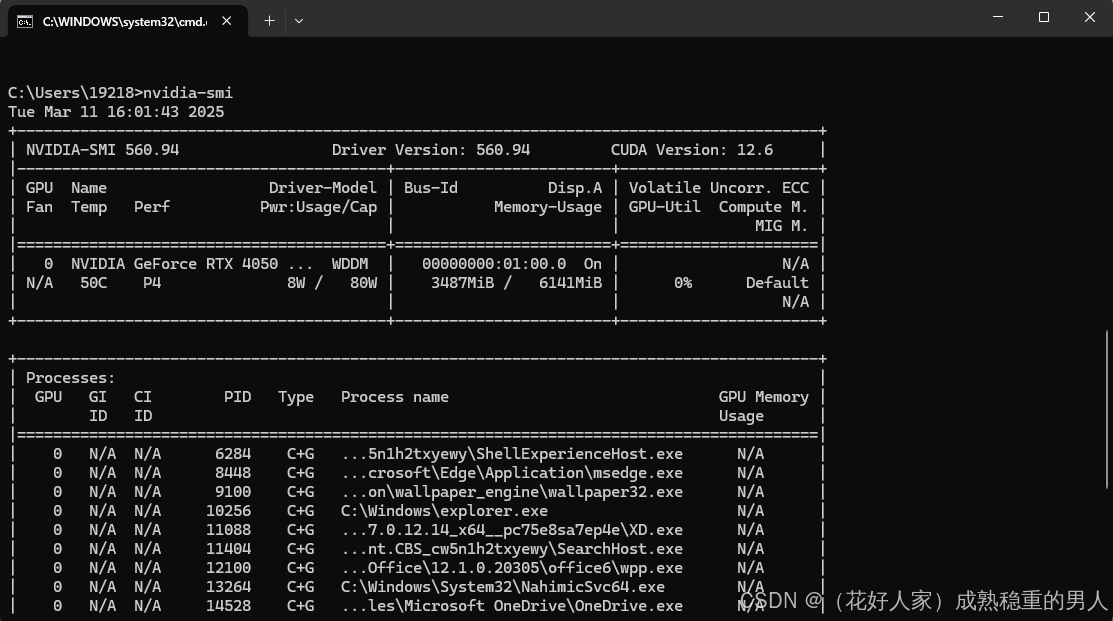
首先还是win+R 输入cmd 打开命令窗 之后输入 nvidia-smi查询可支持的最高cuda版本,驱动是向下兼容的,所以我推荐安装12.1 版本的就行

cuda的安装
双击安装包安装 然后一直下一步,需要注意的地方是安装选项的时候不要选精简 要选择自定义,然后取消勾选下图中的几个选项



安装完成后打开环境变量界面查看环境变量是否安装成功如果没有则手动安装


变量如下:
CUDA_PATH_V12_1填自己的cuda版本号,比如你是cuda12.3改成CUDA_PATH_V12_3
CUDA_PATH
CUDA_PATH_V12_1
值的话修改成自己的路径。
之后打开命令窗输入nvcc -V 命令如果输出版本号则代表成功安装

cudnn的安装
下载地址
https://developer.nvidia.com/rdp/cudnn-archive
下载可能会需要注册账号随便注册一个就行,然后找到跟自己cuda对应的版本

下载之后是一个压缩包,解压下来然后把里面的文件全部复制,粘贴到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1的文件夹.V12.1 是我安装的版本号, 你的可能跟这个有点差别


3.创建虚拟环境
3.1创建虚拟环境
搜索Anaconda Prompt 打开第一个
在打开的终端中输入如下指令创建虚拟环境并指定python版本,其中your_env_name为你要创建得环境名称,在创建过程中出现Proceed 直接在?后打y 然后按回车
conda create -n your_env_name python=3.8
3.2 激活虚拟环境
输入如下命令可激活虚拟环境
conda activate your_env_name
其中 your_env_name为刚刚你创建的虚拟环境的名称
3.3 下载pytorch
pytorch 下载地址如下 https://pytorch.org/get-started/previous-versions/ 选择 跟自己cuda 对应的pytorch版本不建议下载的pytorch版本过新,我这里由于我的cuda是v12.1,所以我这里就以跟cuda12.1 对应的pytorch演示
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
二、YOLO的使用
1.拉取源码
训练之前首先要拉取项目的源码,拉取源码有两种方式,第一种是直接用pip 下载安装包含所有依赖项 的 ultralytics 包,第二种就是从GitHub上下载源码
后续操作都以第一种演示,因为里面很多配置文件都可以改了直接用,免去自己创建的过程了
1.1 PIP下载依赖包
如果你想使用pip 下载的话在你的虚拟环境中输入以下指令
pip install ultralytics
需要注意的是pip 和官方拉取的都是最新的V11如果你想使用其他版本如V8 ,可以使用以下指令
pip install ultralytics==8.2.95
如果下载卡顿或者中断可以换成国内的源
pip install ultralytics==8.2.95 -i https://mirrors.aliyun.com/pypi/simple/
1.2 GitHub拉取源码
下载解压之后在pycharm打开
如果你想在GitHub拉取V8的源码,可以点击下方链接
V8的源码
因为是直接拉取的项目所以还需要手动输入下方指令下载依赖项
pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip uninstall pillow
pip install pillow==6.2.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install psutil -i https://mirrors.aliyun.com/pypi/simple/
pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.准备数据集
2.1 使用官方给出的数据集
你可以选择使用官方给出的几个示例数据集,如coco128,该数据集可以检测80个常见的物体.我们后续的操作都以官网数据集演示
下载链接
下载解压之后存放到你的项目目录, 目录结构如下
├── ultralytics
└── datasets
└── coco128

2.2使用自己的数据集
如果你想完成指定的物体检测任务,那么你就要自己准备数据集,首先你要准备若干张想要检测的物体的图片,其次你要自己打标签,在图片上标注上这个物体是什么
打标签的话可以使用LabelImg这个软件
下载链接
下载解压之后重复重创建虚拟环境的步骤,使用conda创建一个新的虚拟环境用于下载LabelImg的依赖
当你创建并进入的新的虚拟环境之后可以使用在终端输入cd D:\S\D\labelImg-master 进入项目目录下, 其中D:\S\D\labelImg-master 为你下载解压之后保存的目录。需要注意的是大部分人刚进入终端都是处于C盘目录下这时候直接输入cd 切换目录是切换不进去的应该先进入的保存项目目录的磁盘

进入项目目录下后输入下方命令下载依赖
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
//启动软件
python labelImg.py

# VOC转YOLO
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要 一一对应
classes1 = ["people","dog","cat"] # 修改为自己标签中的种类
# 2、voc格式的xml标签文件路径
xml_files1 = r'E:\data\figure\xml'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'E:\data\figure\labels'
convert_annotation(xml_files1, save_txt_files1, classes1)
3. 加载模型
官方给出的加载模型的方式有三种
方式1:从YAML文件构建新模型
model = YOLO("yolov8n.yaml")
这种方式根据给定的yolov8n.yaml配置文件创建一个新的YOLOv8模型实例。
配置文件包含了模型架构的所有细节,比如网络层的类型、参数等。
创建的新模型默认情况下不会带有任何预训练权重,除非后续通过其他方式加载权重。
使用这种方式可以在不依赖预训练权重的情况下定义模型结。适用于需要从头开始训练的情况或者需要定制模型结构的场景。
方式2:从预训练权重构建模型
model = YOLO("yolov8n.pt")
这种方式直接加载一个预先训练好的模型,通常是.pt格式的PyTorch模型文件。
加载的模型不仅包含了模型架构信息,还包括了预训练得到的权重参数,yolov8n.pt就是训练好的能检测coco中的80个类别的模型。
这是最常用的加载方式之一,特别是当您希望利用预训练模型进行预测或者进一步微调的时候。使用预训练权重文件的主要作用是通过微调预训练权重,达到加快自己模型的训练速度的目的。
方式3:从YAML文件构建新模型,并将预训练权重转移到新模型
model = YOLO("yolov8n.yaml").load("yolov8n.pt")
这种方式首先根据yolov8n.yaml文件构建模型结构,然后使用load方法加载预训练权重。
这种方式结合了前两种方式的优点,即可以根据配置文件定义模型结构,并加载预训练权重。
如果模型结构在.yaml文件中有改动,但是仍然希望使用预训练权重初始化模型,则可以采用这种方式。通常这种方式用于需要修改模型结构但仍想利用预训练权重的场景。
模型种类有5中,分别是n、s、m、l、x。其中n最小,x最大,越大模型参数量越大,需要更多的显卡内存来训练,并且运行速度更慢。如果你想切换模型,只需把yolov8n.pt 改为yolov8m.pt即可,yaml同理。
4.开始训练
当你完成了以上所有操作就可以开始训练了,首先在你的项目中新建一个py文件随后复制下方代码运行
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
if __name__ == '__main__':
results = model.train(data="coco128.yaml", epochs=200)
训练中所有关于No module named XXX 的报错都是因为你缺少依赖只需要在终端输入下方命令,其中XXX是你具体缺少的包名
pip install XXX -i https://pypi.tuna.tsinghua.edu.cn/simple/
4.1 训练参数详解
1. data✰✰✰✰✰
data: 数据文件的路径。该参数指定了数据集文件的位置,例如 coco128.yaml。数据集文件包含了训练和验证所需的图像、标签。
这里需要传入的是一个yaml文件,可以参考官方给出的coco128 数据文件

2. epochs ✰✰✰
epochs: 训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。训练的轮数越多,模型对数据的学习就越充分,但也增加了训练时间。
3. patience
patience: 早停的等待轮数。在训练过程中,如果在一定的轮数内没有观察到模型性能的明显提升,就会停止训练。这个参数确定了等待的轮数,如果超过该轮数仍没有改进,则停止训练。
早停
早停能减少过拟合。过拟合(overfitting)指的是只能拟合训练数据, 但不能很好地拟合不包含在训练数据中的其他数据的状态。
4. batch ✰✰✰✰✰
batch: 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为**-1**,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
选取策略
一般认为batch越大越好。因为我们的batch越大我们选择的这个batch中的图片更有可能代表整个数据集的分布,从而帮助模型学习。但batch越大占用的显卡显存空间越多,所以还是有上限的。
5. device ✰✰✰✰✰
device: 训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 cuda device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
其他更多参数大家可以自行参考官方文档 新版yolo11 引入了更多超参,帮助模型更好地泛化到未见数据中,对提高YOLO 模型的稳健性和性能至关重要。
官方文档
4.2 训练完各文件详解
训练完成后会在项目目录下生成一个名为run的文件夹,里面就包含了你训练和预测的记录

train里面就是你训练完成的模型文件,这里面包含是目标检测性能指标,如下图

weights目录:
其他的都是一些关于模型性能的了,如果感兴趣可以去了解一下
5.使用训练的模型进行预测
from ultralytics import YOLO
model = YOLO(r"D:\study\information\Python\L.pt")
model.predict(r"D:\study\information\Python\pit\data\images\flip_Image_20240626145234269.bmp",save=True)
5.1 参数详解
这里得model 导入的就是你训练好的模型路径了
model.predict 传入的第一个值为输入的源,输入源包括静态图像、视频流和各种数据格式。以下是所有yolo支持的输入源

推理可以传入的参数比较少,具体可看下图



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









