"""
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线。
根据学习器的预测结果,把阈值从0变到最大,即刚开始是把每个样本作为正例进行预测,随着阈值的增大,学习器预测正样例数越来越少,
直到最后没有一个样本是正样例。在这一过程中,每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了“ROC曲线”。
ROC曲线以“真正例率”(True Positive Rate,简称TPR)为纵轴,横轴为“假正例率”(False Positive Rate,简称FPR),
ROC偏重研究基于测试样本评估值的排序好坏。
(0, 0)表示将所有的样本预测为负例,(1, 1)则表示将所有的样本预测为正例,
(0, 1)表示正例全部出现在负例之前的理想情况,(1, 0)则表示负例全部出现在正例之前的最差情况。
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, LabelEncoder # 标准化
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import roc_curve, auc
breatcancer = pd.read_csv('breast+cancer+wisconsin+diagnostic/wdbc.data', header=None).iloc[:, 1:]
X = StandardScaler().fit_transform(breatcancer.iloc[:, 1:]) # 数据标准化
n_samples, n_features = X.shape
random_state = np.random.RandomState(0)
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)] # 添加噪声
y = breatcancer.iloc[:, 0] # 对应编码1、2转化为0、1
lab_en = LabelEncoder()
y = lab_en.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0,
shuffle=True, stratify=y)
y_score = dict() # 存储各算法模型的决策得分
svm_linear = SVC(kernel='linear', probability=True, random_state=0)
# 通过decision_function()计算得到的y_score的值,用在roc_curve()函数中
svm_fit = svm_linear.fit(X_train, y_train)
y_score["svm_linear"] = svm_linear.decision_function(X_test)
lg_model = LogisticRegression(max_iter=1000).fit(X_train, y_train) # 逻辑回归
y_score["LogisticRegression"] = lg_model.decision_function(X_test)
lda_model = LinearDiscriminantAnalysis().fit(X_train, y_train) # 线性判别
y_score["LinearDiscriminantAnalysis"] = lda_model.decision_function(X_test)
ada_model = AdaBoostClassifier().fit(X_train, y_train) # 集成学习
y_score["AdaBoostClassifier"] = ada_model.decision_function(X_test)
fpr, tpr, threshold, ks_max, best_thr = dict(), dict(), dict(), dict(), dict()
for key in y_score.keys():
# 计算真正率,假正率,对应阈值
fpr[key], tpr[key], threshold[key] = roc_curve(y_test, y_score[key])
# 计算ks和最佳阈值
KS_max = tpr[key] - fpr[key] # 差值向量
ind = np.argmax(KS_max) # 最大KS值索引
ks_max[key] = KS_max[ind] # 最大KS
best_thr[key] = threshold[key][ind] # 最大阈值
print('%s: fpr = %.5f, tpr = %.5f, 最大KS为:%.5f, 最佳阈值为:%.5f'
% (key, fpr[key][ind], tpr[key][ind], ks_max[key], best_thr[key]))
plt.figure(figsize=(8, 6))
line = ['r-*', 'b-o', 'g-+', 'c-x']
for i, key in enumerate(y_score.keys()):
# 假正率为横坐标,真正率为纵坐标做曲线
plt.plot(fpr[key], tpr[key], line[i], lw=2, label=key+' AUC = %0.2f' % auc(fpr[key], tpr[key]))
plt.plot([0, 1], [0, 1], color='navy', lw=1, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.grid()
plt.xlabel('False Positive Rate', fontsize=12)
plt.ylabel('True Positive Rate', fontsize=12)
plt.title('Binary classification of ROC and AUC', fontsize=14)
plt.legend(loc="lower right", fontsize=12)
plt.show()

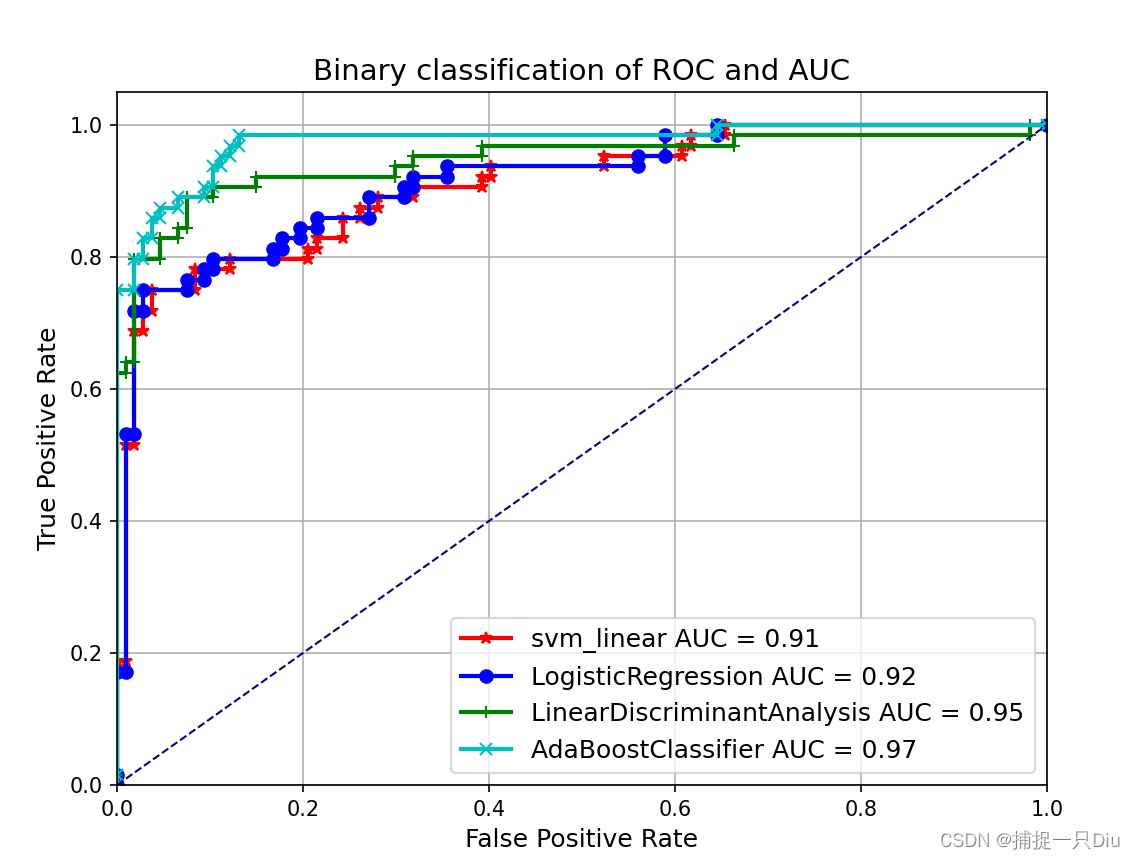








 本文介绍了如何通过SVM、逻辑回归、线性判别分析和AdaBoostClassifier等模型在乳腺癌数据集上计算并绘制ROC曲线,展示了不同模型的真阳性率和假阳性率变化,以及AUC值,以评估模型性能。
本文介绍了如何通过SVM、逻辑回归、线性判别分析和AdaBoostClassifier等模型在乳腺癌数据集上计算并绘制ROC曲线,展示了不同模型的真阳性率和假阳性率变化,以及AUC值,以评估模型性能。


















 5099
5099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











