










问题描述
你进了一家赌场,假设面前有台老虎机(arms)。我们知道,老虎机本质上就是 个运气游戏,我们假设每台老虎机
都有一定概率
吐出一块钱,或者不吐钱( 概 率
)。假设你手上只有
枚代币(tokens),而每摇一次老虎机都需要花费 一枚代币,也就是说你一共只能摇
次,那么如何做才能使得期望回报(expected reward)最大呢?
不同解决思路
设置相关变量
贪心
思路:每次都选择目前估测值最高的老虎机玩,根据玩的结果更新该台老虎机的获奖概率
伪代码:

 贪心
贪心
思路:一些机会用来尝试不同的老虎机(不根据估测概率随机选---探索),根据统计结果估测每台老虎机出奖励的概率(随着尝试次数的增多,估计会越来越准确);另一些机会根据估测直接用在获奖概率最高的老虎机上(利用)
流程图:
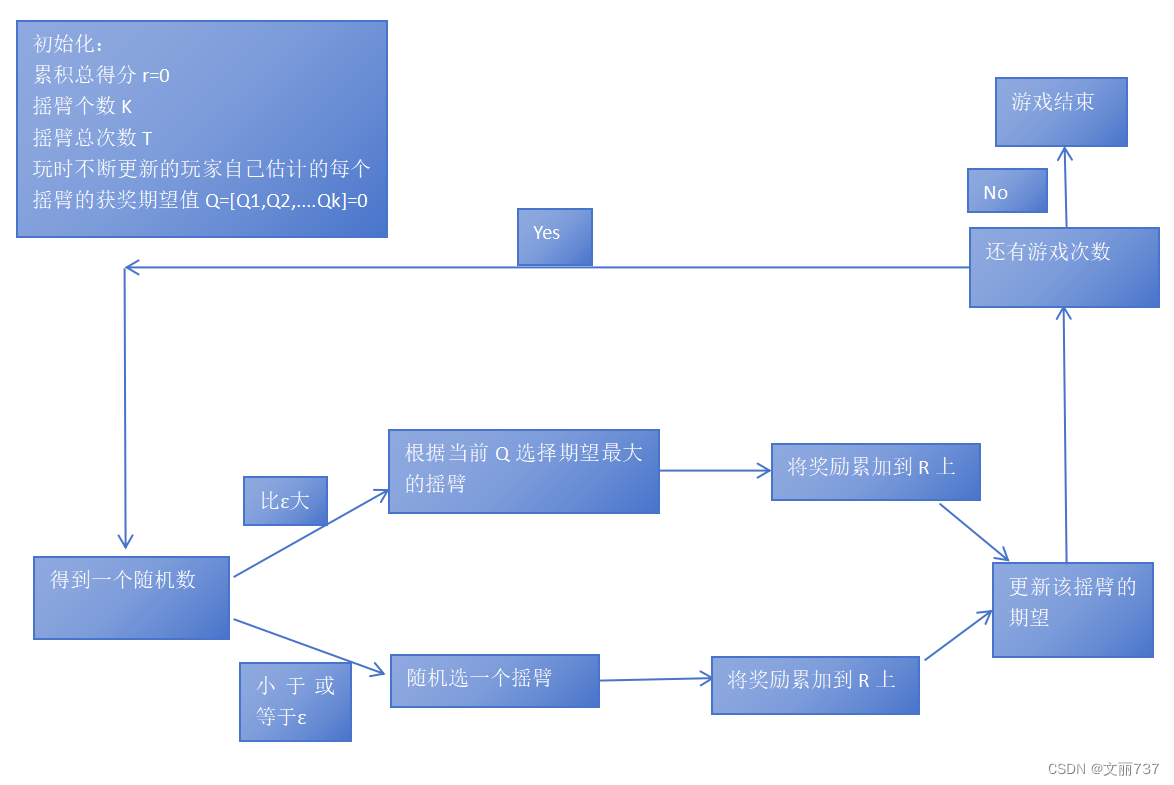
伪代码:

softmax
思路:每次都是随机玩(不是等概率随机),但是抽中出奖概率高的老虎机的概率更大
伪代码:

程序设计
由于每台老虎机默认出奖概率设置、返回奖励机制在三种算法下统一。可用类先设计好
老虎机类
- 属性:台数、每台机器出奖概率(设置为可手动设置也可随机初始)、最优机器概率
- 方法:按照出奖概率返回奖励(1或0)
ps:
有0.4的概率出奖即,随机生成一个[0,1]的数,小于0.4的概率
小于0.4时返回1;否则返回0 即可实现
class BernoulliBandit():
def __init__(self, K, probas=None): #n为摇臂的个数,probas为每个摇臂获得奖励的概率
assert probas is None or len(probas) == K
self.K = K
if probas is None:
np.random.seed(int(time.time()))
self.probas = [np.random.random() for _ in range(self.K)]
else:
self.probas = probas
self.best_proba = max(self.probas)
def generate_reward(self, i):
# The player selected the i-th machine.
if np.random.random() < self.probas[i]:
return 1 #满足发生的概率,就获得奖励1
else:
return 0求解算法有关参数设计
:第i台老虎机评估的概率 ------列表即可
:第i台老虎机玩过的次数 --------列表即可
:总获奖积分 ------数即可
:第k台老虎机返回的奖励 ------列表即可
y:平均每步得分(用来衡量算法好坏) ------列表即可
贪心算法代码
def greedy_strategy(bandit,T,r,Q,count):
r=0
y=[]
for t in range(1,T+1):
j=np.argmax(Q)
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return y贪心算法代码
def greedy_e_strategy(bandit,K,T,epsilon,r,Q,count):
r=0
y=[]
for t in range(1,T+1):
if np.random.random()<epsilon:
j=np.random.randint(0,K)
else:
j=np.argmax(Q)
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return ysoftmax算法代码
def softmax(bandit,K,T,epsilon,Q,r,count):
r=0
y=[]
property_list=np.zeros(K)
for t in range(1,T+1):
Probability_accumulation=0
total_accumulation=sum(pow(e,Q[i]/epsilon) for i in range(K))
random_value=np.random.random()
for i in range(K):
property_list[i]=pow(e,Q[i]/epsilon)/total_accumulation
Probability_accumulation+=property_list[i]
if random_value<Probability_accumulation :
j=i
break
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return y结果查看
- 可视化平均奖励
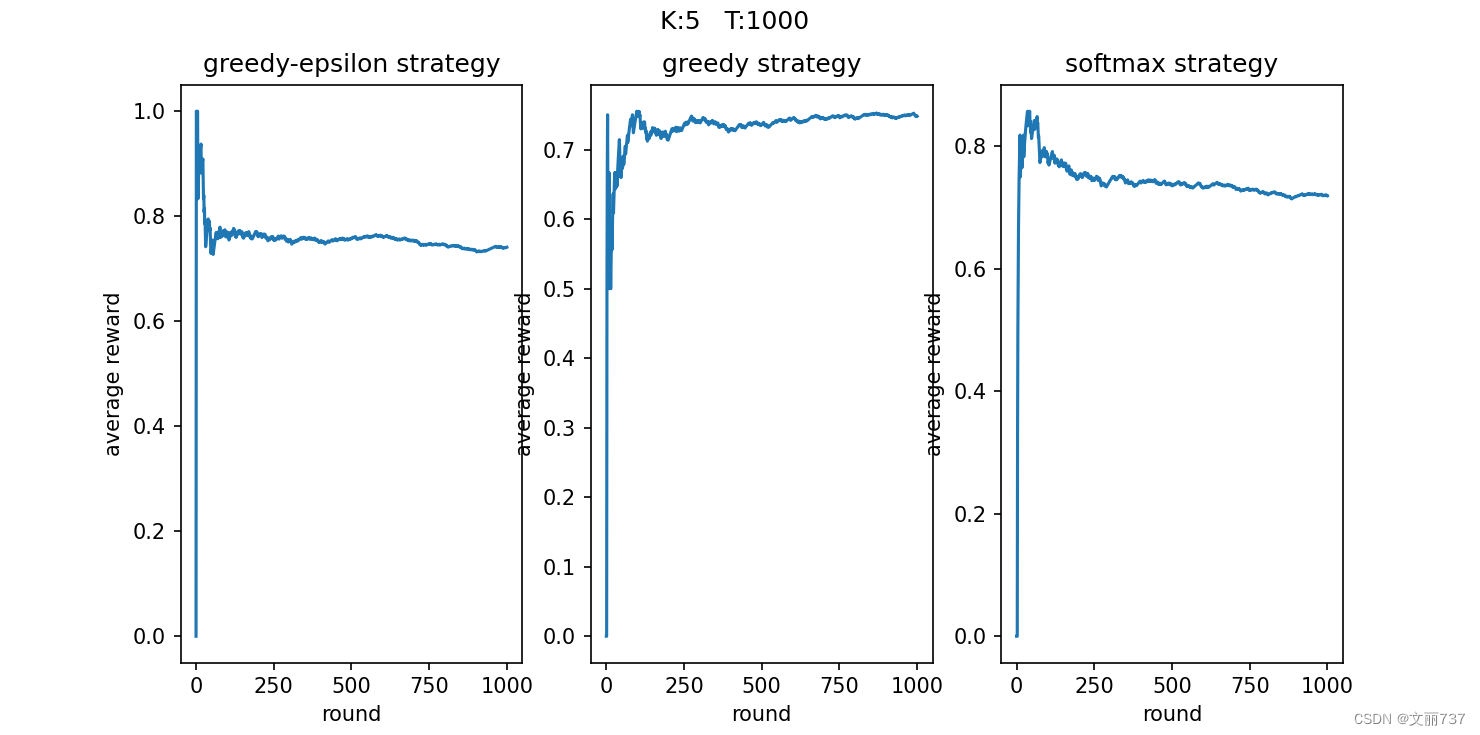
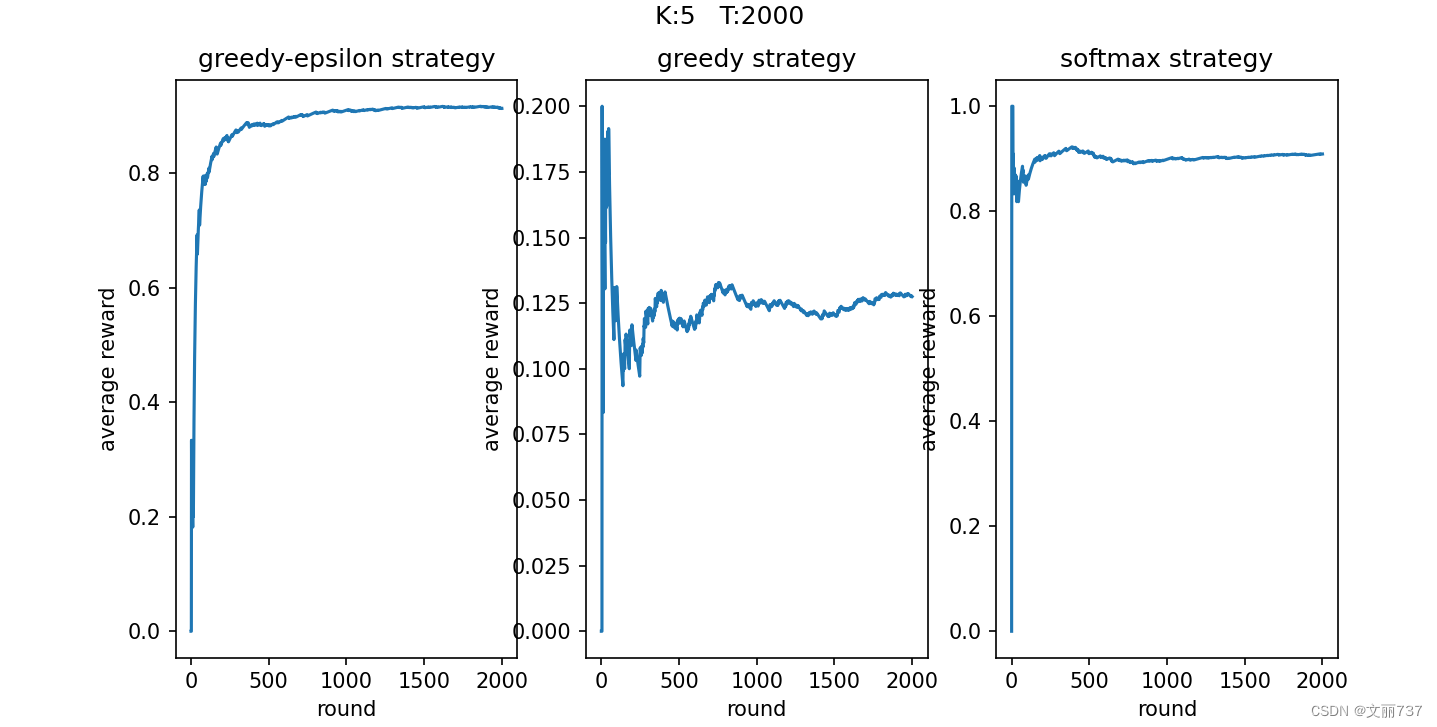
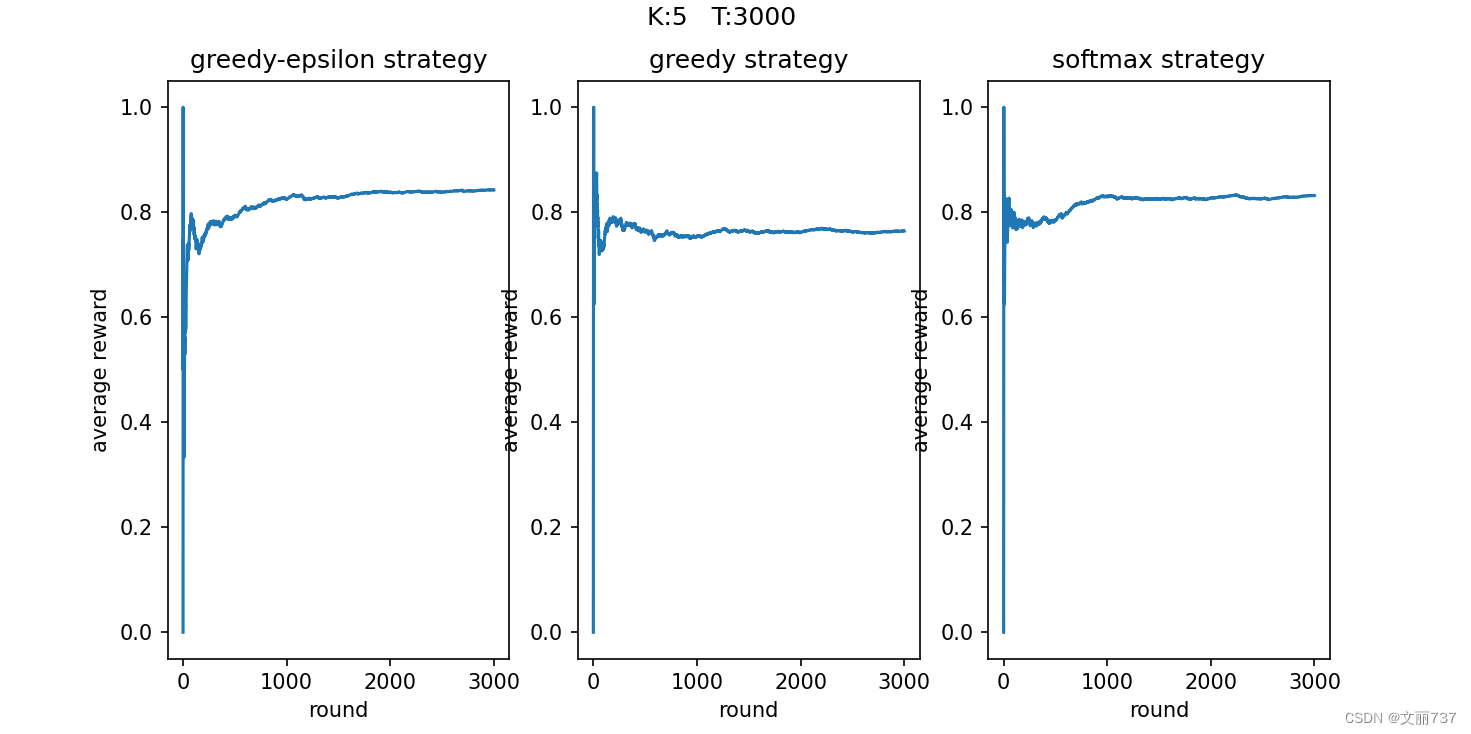
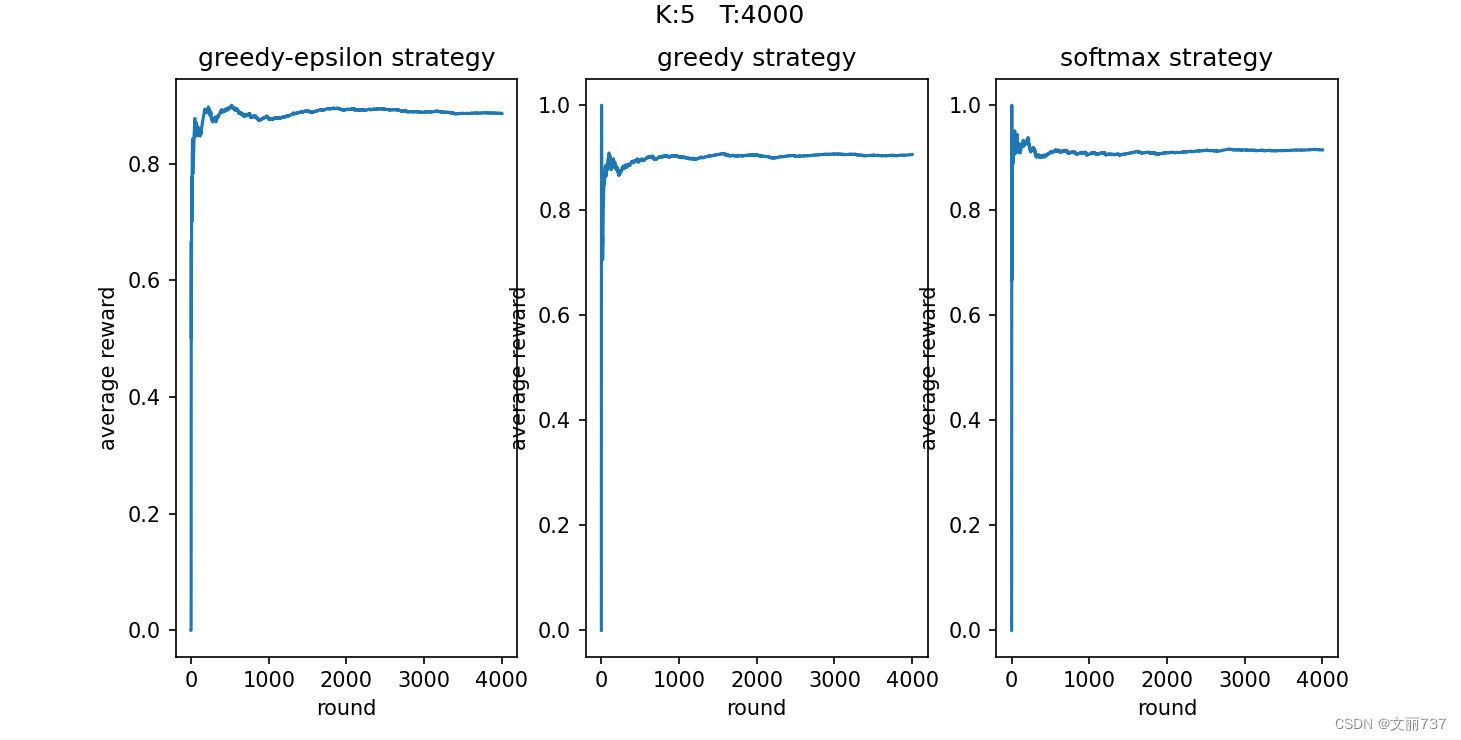
随着尝试次数的增加,平均得分趋于稳定,其中贪心(中间)的结果浮动较大。
- 每台老虎机估测获奖概率与实际获奖概率比较

整体代码
import numpy as np
import time
import matplotlib.pyplot as plt
e=2.718
class BernoulliBandit():
def __init__(self, K, probas=None): #n为摇臂的个数,probas为每个摇臂获得奖励的概率
assert probas is None or len(probas) == K
self.K = K
if probas is None:
np.random.seed(int(time.time()))
self.probas = [np.random.random() for _ in range(self.K)]
else:
self.probas = probas
self.best_proba = max(self.probas)
def generate_reward(self, i):
# The player selected the i-th machine.
if np.random.random() < self.probas[i]:
return 1 #满足发生的概率,就获得奖励1
else:
return 0
#参数K:摇臂个数,T:试验次数,epsilon:探索概率,r:累积奖励,Q:每个摇臂的估计值,count:每个摇臂的选择次数
def greedy_e_strategy(bandit,K,T,epsilon,r,Q,count):
r=0
y=[]
for t in range(1,T+1):
if np.random.random()<epsilon:
j=np.random.randint(0,K)
else:
j=np.argmax(Q)
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("\n贪心-ε策略:\n")
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return y
def greedy_strategy(bandit,T,r,Q,count):
r=0
y=[]
for t in range(1,T+1):
j=np.argmax(Q)
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("\n贪心策略:\n")
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return y
def softmax(bandit,K,T,epsilon,Q,r,count):
r=0
y=[]
property_list=np.zeros(K)
for t in range(1,T+1):
Probability_accumulation=0
total_accumulation=sum(pow(e,Q[i]/epsilon) for i in range(K))
random_value=np.random.random()
for i in range(K):
property_list[i]=pow(e,Q[i]/epsilon)/total_accumulation
Probability_accumulation+=property_list[i]
if random_value<Probability_accumulation :
j=i
break
reward=bandit.generate_reward(j)
r+=reward
y.append(r/t)
Q[j]=(Q[j]*count[j]+reward)/(count[j]+1)
count[j]+=1
print("\nsoftmax:\n")
print("累积奖励:",r)
print("每个摇臂选择次数: ",count)
print("每个摇臂的估计值: ",Q)
print("每个摇臂真实获奖的概率: ",bandit.probas)
return y
fig,axs=plt.subplots(1,3,figsize=(10,5))
k_=5
T_=4000
bandit = BernoulliBandit(K=k_)
y_ge=greedy_e_strategy(bandit,K=k_,T=T_,epsilon=0.1,r=0,Q=np.zeros(k_),count=np.zeros(k_))
x=[i for i in range(0,T_+1)]
y_ge=[0]+y_ge
axs[0].plot(x,y_ge)
axs[0].set_xlabel('round')
axs[0].set_ylabel('average reward')
axs[0].set_title('greedy-epsilon strategy')
y_g=greedy_strategy(bandit,T=T_,r=0,Q=np.zeros(k_),count=np.zeros(k_))
x=[i for i in range(0,T_+1)]
y_g=[0]+y_g
axs[1].plot(x,y_g)
axs[1].set_xlabel('round')
axs[1].set_ylabel('average reward')
axs[1].set_title('greedy strategy')
y_sf=softmax(bandit,K=k_,T=T_,epsilon=0.1,r=0,Q=np.zeros(k_),count=np.zeros(k_))
x=[i for i in range(0,T_+1)]
y_sf=[0]+y_sf
axs[2].plot(x,y_sf)
axs[2].set_xlabel('round')
axs[2].set_ylabel('average reward')
axs[2].set_title('softmax strategy')
plt.suptitle("K:%d T:%d "%(k_,T_))
plt.show()
想法:
1、在估测每台老虎机出奖概率的初始上,正常全零,会发现贪心浮动很大(时而很好时而很差),由于贪心的本质找到一个好的老虎机后该台评分被拉高,就接着选这台,即使后面没有奖励该台的评分已经超过0了,在贪心算法下它不会再选别的老虎机了。就是哪台第一次出奖励就一路选到底。但是若把
设置为全1将大不相同!贪心也被赋予探索能力了,得分很好,本质上是失误多就不选你了。
2、这个问题可以看成多台老虎机也可以看成一个老虎机的多个摇臂。
3、可再定义忏悔值等不同指标去帮助观测算法在此问题上的差异















 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









