






看到这个标题,我首先就想到了线性相关,这个模型是否就是类似于一个线性方程
3.1 基本形式
给定X
X=(x1;x2;x3;x4;x5..;xd),xi就是X在第i个属性上的取值。
好瓜=(青绿;蜷缩;浊响)。
线性模型:通过属性的线性组合来进行预测的函数。
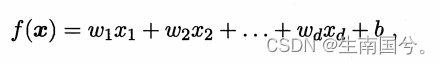
第一章

写成向量的形式
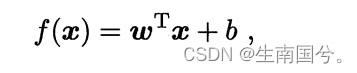
现在我们想确定f(x),已知的是X,就差w和b了 。
线性模型的优点:①形式简单、②有很好的可解释性(因为w能够很直观的表示出各个属性在预测中的重要性)
![]()
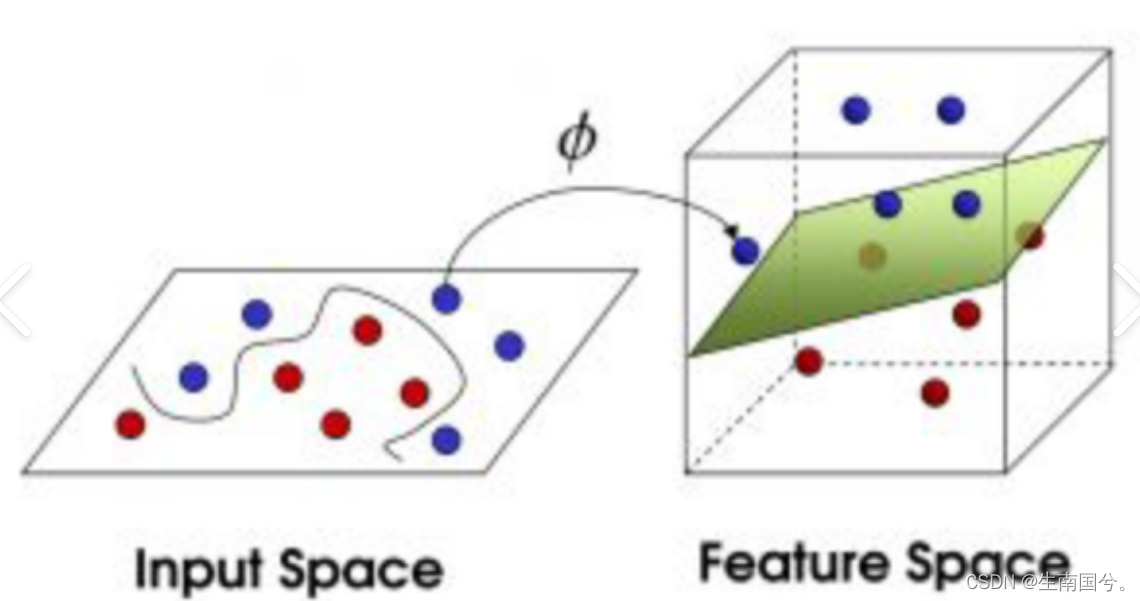
线性模型可以通过引入 层级结构 (可以理解为上节课院长讲到的tranform中6层的哪个结构,就是有子注意力机制和前馈神经网络)或者 高维映射 (在一个平面上混乱的点,你没办法把他们区分开。但是如果你把不同的点映射到高维的空间里面 比如 二维 到 三维 你就可以通过一个平面来区分) 而得到。
3.2 线性回归
线性回归:学得一个模型以 尽可能的准确 的预测实值输出标记。
对于上述的公式x是它的属性值,当它是数值型的时候,还很好理解,但是如果它现在是一些历离散的数据,该如何去计算然后预测呢?
这个时候我们需要考虑“序”的问题
有序的离散值,就连续化。
无序的离散值,就向量化。
譬如:
大 中 小——1 0.5 0
西瓜 南瓜 黄瓜——(1 0 0):表示是西瓜,不是南瓜,不是黄瓜
那现在我们解决了x的问题,对于线性模型,还有w和b的值该怎么办呢
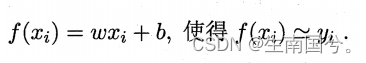
想要这个模型很好,无非就是让预测的值和真实的值越接近越好,还记得我们上节课讲到的衡量回归i问题的指标——均方误差
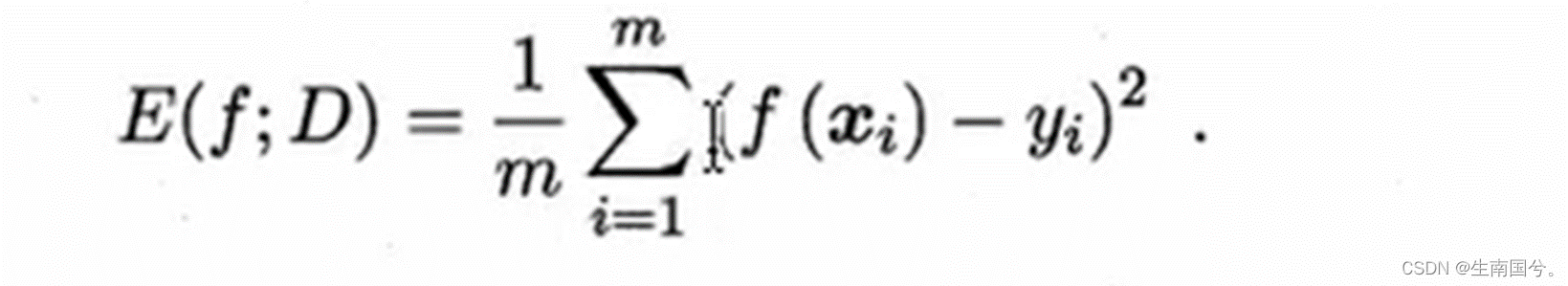
如果我们可以使得均方误差最小化,那么我们的模型当然就会更好,
这里 我们就使用 “最小二乘法” 来是实现均方误差最小化。
在线性回归中,最小二乘法就是:找到一条直线使得所有样本到直线的欧氏距离之和最小
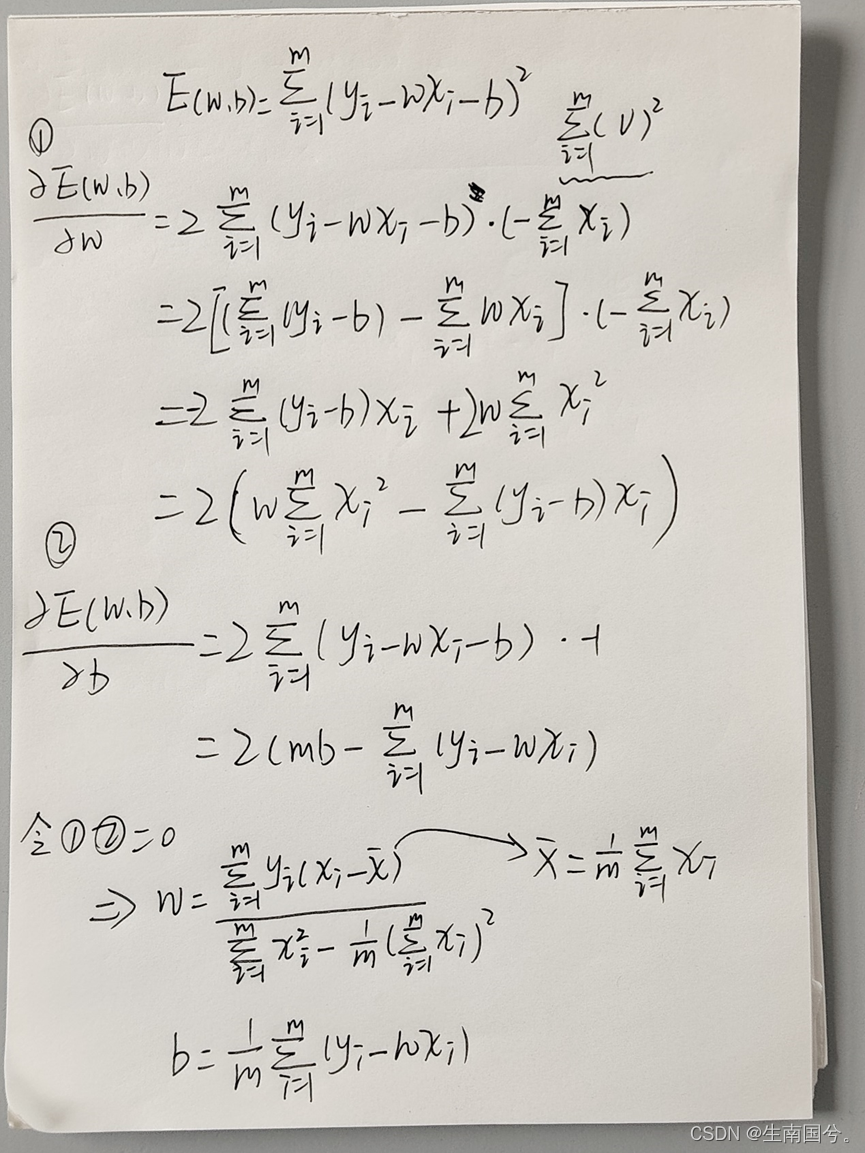
这样就可以得到解了。
当x的属性值变多,X就成了一个向量。这个时候可以把w和b一起写在w 中。

和上面类似的此时
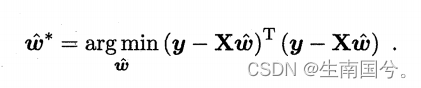
要对它求偏导,这里就涉及到矩阵的求导

这个是我之前总结的,
最终你会得到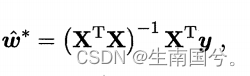
此时,X的转置*X,可能是满秩可能是降秩。
当x的列数多余行数,就不满秩。因为这样你的秩最大也就是行数显然是小于行数的,这个时候就会解出多个解。
多个w都可以使我们的均方误差最小化,那我们到底该选择哪一个呢?就可以考虑引入正则化。
我认为枕着化是不是就是通过引入一些约束,然后就可以更好的确定我们到底选择哪个解。
线性模型也会有一些变化:
譬如
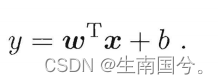

这样其实就实现了,线性模型预测出的结果向非线性转化。用线性模型的方式去逼近y的对数值
这样逼近的方法,就可以叫做:联系函数 g(·)
比如上述的g(·)=ln(·)
3.3 对数几率回归
上面我们将线性模型运用到了非线性模型上,如果是分类任务的话,又该怎么办?
可以考虑刚刚提到的联系函数。
如果我们找到一个联系函数,让分类任务中的y真实标记与线性回归模型的预测值联系起来。
如下;单位阶跃函数
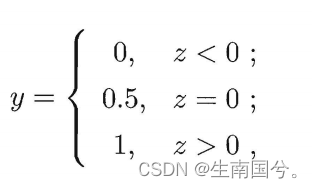

但是这个函数是不连续的,因此我们得找到一个代替函数,希望它是单调可微。
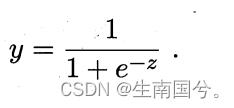
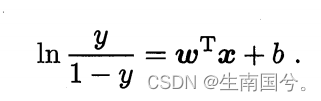
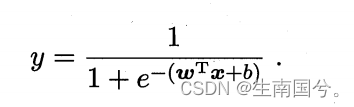
y/1-y:就是几率
lny/1-y :就是对数几率
对于对数几率回归,我们采用最大似然法,求W和b值。
















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











