






目录
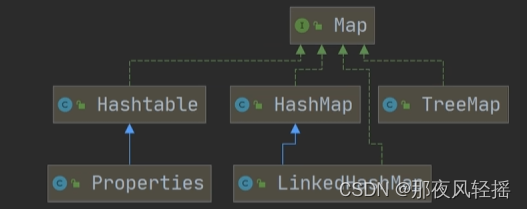
一.Map:
1.基本介绍:

2.Map常用方法:

3.Map的遍历方法:

//第一组: 先取出 所有的 Key , 通过 Key 取出对应的 Value
Set keyset = map.keySet();
//(1) 增强 for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组: 把所有的 values 取出
Collection values = map.values();
//这里可以使用所有的 Collections 使用的遍历方法
//(1) 增强 for
System.out.println("---取出所有的 value 增强 for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的 value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过 EntrySet 来获取 k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强 for
System.out.println("----使用 EntrySet 的 for 增强(第 3 种)----");
for (Object entry : entrySet) {
//将 entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用 EntrySet 的 迭代器(第 4 种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}4.HashMap:
1.基本介绍:

2.HashMap底层扩容机制:

5.Hashtable:
1.基本介绍:
- 存放的元素是键值对,Hashtable的键和值都不能为null,否则会抛出NullPointException异常。
- Hashtable的使用方法和HashMap一样
- Hashtable是线程安全的(synchronized),HashMap是线程不安全的。
2.HashMap和Hashtable的对比:

6.Properties:
1.基本介绍:

Properties继承了Hashtable,可以通过k-v存放数据,key和value不能为null。key
7.如何选择集合类:

8.Treeset:
treeSet排序操作
TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用 String 的 compareTo 方法进行字符串大小比较
//如果老韩要求加入的元素,按照长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});9.TreeMap:
TreeMap排序操作:
//使用默认的构造器,创建 TreeMap, 是无序的(也没有排序)
TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的 k(String) 的大小进行排序
//按照 K(String) 的长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
})
/*2. 调用 put 方法
2.1 第一次添加, 把 k-v 封装到 Entry 对象,放入 root
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的 key , 给当前 key 找到适当位置
parent = t;
cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类的 compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果遍历过程中,发现准备添加 Key 和当前已有的 Key 相等,就不添加
return t.setValue(value);
} while (t != null);
}
*/二.Collections工具类:
1.基本介绍:

2.Collection方法:

//shuffle(List):对 List 集合元素进行随机排序
Collections.shuffle(list);
//reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
//sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
//sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码. return ((String) o2).length() - ((String) o1).length();
}
});
//swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list, 0, 1);

//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom 出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将 src 中的内容复制到 dest 中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给 dest 赋值,大小和 list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
//如果 list 中,有 tom 就替换成 汤姆
Collections.replaceAll(list, "tom", "汤姆");三.泛型:
1.泛型的优点:

2.泛型的基本介绍:

public class Generic03 {
public static void main(String[] args) {
//注意,特别强调: E 具体的数据类型在定义 Person 对象的时候指定,即在编译期间,就确定 E 是什么类型
Person<String> person = new Person<String>("韩顺平教育");
person.show(); //String
/*
class Person<E> {
E s ;//E 表示 s 的数据类型, 该数据类型在定义 Person 对象的时候指定,即在编译期间,就确定 E
是什么类型
public Person(E s) {//E 也可以是参数类型
this.s = s;
}
public E f() {//返回类型使用 E
return s;
}
}
*/
你可以这样理解,上面的 Person 类
class Person {
String s ;//E 表示 s 的数据类型, 该数据类型在定义 Person 对象的时候指定,即在编译期间,就确定 E
是什么类型
public Person(String s) {//E 也可以是参数类型
this.s = s;
}
public String f() {//返回类型使用 E
return s;
}
}
*/3.泛型使用细节:
- 给泛型指向数据类型是,要求是引用类型,不能是基本数据类型。
- 在给泛型指定具体类型后,可以传入该类型或者其子类类型。
ArrayList<Integer> list1 = new ArrayList<Integer>();
List<Integer> list2 = new ArrayList<Integer>();
//在实际开发中,我们往往简写
ArrayList<Integer> list3 = new ArrayList<>();
List<Integer> list4 = new ArrayList<>();
ArrayList<Pig> pigs = new ArrayList<>();
//如果是这样写 泛型默认是 Object
ArrayList arrayList = new ArrayList();//等价 ArrayList<Object> arrayList = new ArrayList<Object>();4.自定义泛型:
1.自定义泛型类:
- 普通成员可以使用泛型 (属性、方法)
-
使用泛型的数组,不能初始化,数组在 new 不能确定 T 的类型,就无法在内存开空间。
- 静态方法中不能使用类的泛型,静态是和类相关的,在类加载时,对象还没有创建 所以,如果静态方法和静态属性使用了泛型,JVM 就无法完成初始化
2.自定义泛型接口:
- 接口中,静态成员也不能使用泛型。
-
泛型接口的类型 , 在继承接口或者实现接口时确定
-
没有指定类型,默认为 Object
//实现接口时,直接指定泛型接口的类型
//class bb implement IUsb<Integer, Float>{
public Float get(Integer integer) {
return null;
}
public void hi(Float aFloat) {
}
public void run(Float r1, Float r2, Integer u1, Integer u2) {
}
}
interface IA extends IUsb<String, Double> {
}
//在继承接口 指定泛型接口的类型
//当我们去实现 IA 接口时,因为 IA 在继承 IUsu 接口时,指定了 U 为 String R 为 Double
//,在实现 IUsu 接口的方法时,使用 String 替换 U, 是 Double 替换 R
class AA implements IA {
@Override
public Double get(String s) {
return null;
}
@Override
public void hi(Double aDouble) {
}
@Override
public void run(Double r1, Double r2, String u1, String u2) {
}
}
interface IUsb<U, R> {
//普通方法中,可以使用接口泛型
R get(U u);
void hi(R r);
void run(R r1, R r2, U u1, U u2);
}3.自定义泛型方法:

class Fish<T, R> {//泛型类
public void run() {//普通方法
}
public<U,M> void eat(U u, M m) {//泛型方法
}
//说明
//1. 下面 hi 方法不是泛型方法
//2. 是 hi 方法使用了类声明的 泛型
public void hi(T t) {
}
}














 7732
7732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









