







Redis主从集群
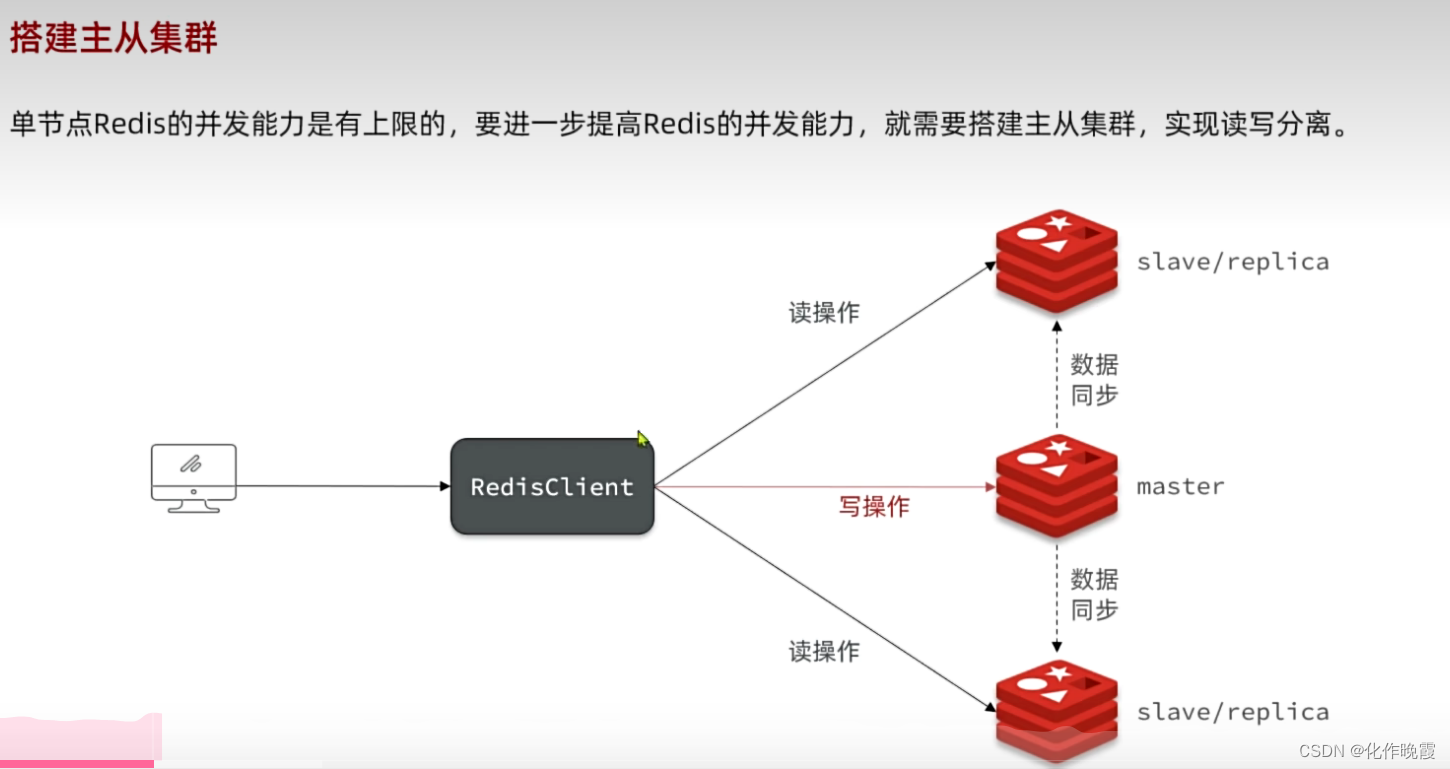
搭建集群
选择在虚拟机上利用3个Docker容器搭建主从集群,容器信息如下
容器名字: 角色: IP: 映射端口:
r1 master 192.168.202.129 7001
r2 slave 7002
r3 slave 7003
利用compose搭建

文件内容:
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003"]netwrok_mode是网络模式,以前我们默认使用的是桥接模式,是利用docker给我们搭建的虚拟网,用了host模式就是跟主机一起使用主机网络,就是相当于主机的一个进程。端口也不用做映射了。
第一
我们首先在虚拟机目录下建一个空的redis文件夹
第二
拉取redis镜像
docker pull redis第三
将docker-compose.yaml文件放在redis文件夹下面
第四
cd redis然后执行
docker compose up -d虽然现在是启动了这三个实例,但是我们还没有指定主从关系,所以我们需要指定
# Redis5.0以前
slaveof <masterip> <masterport>
# Redis5.0以后
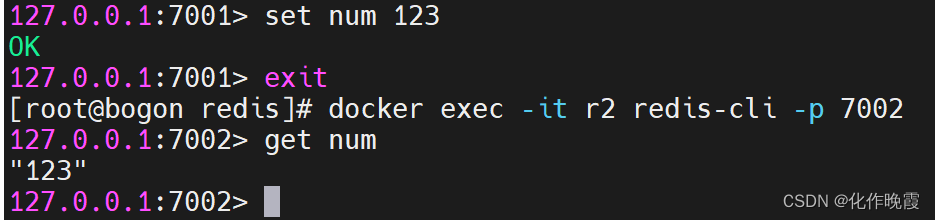
replicaof <masterip> <masterport>先连接r2,使它成为奴隶
# 连接r2
docker exec -it r2 redis-cli -p 7002
# 认r1主,也就是7001
slaveof 192.168.202.129 7001连接r3使它成为奴隶
# 连接r3
docker exec -it r3 redis-cli -p 7003
# 认r1主,也就是7001
slaveof 192.168.202.129 7001连接r1,查看集群状态
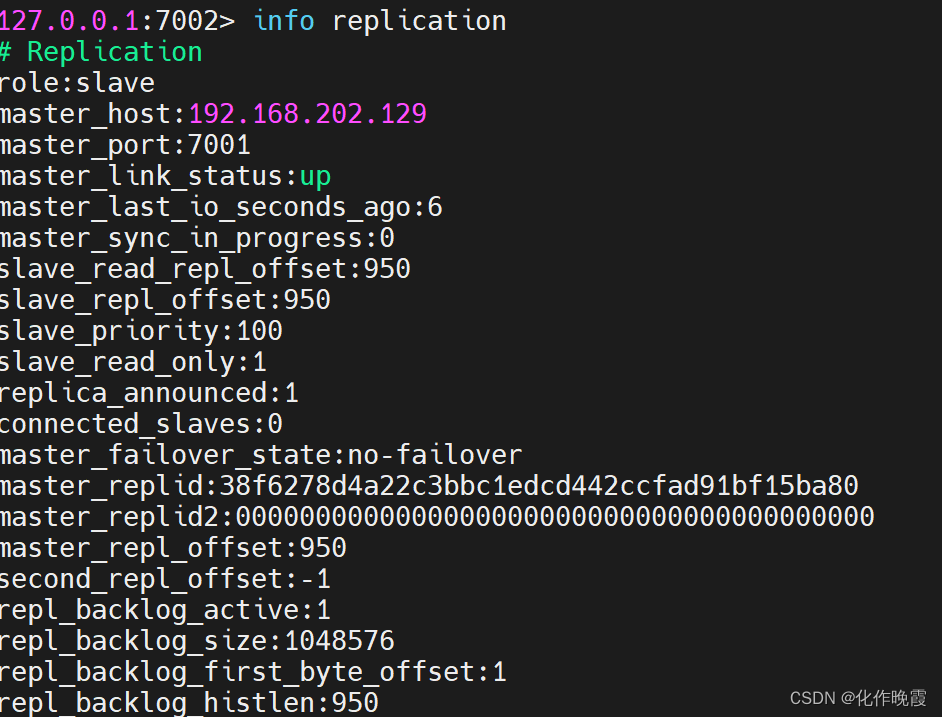
# 连接r1
docker exec -it r1 redis-cli -p 7001
# 查看集群状态
info replicationexit是断开连接。
读写分离。
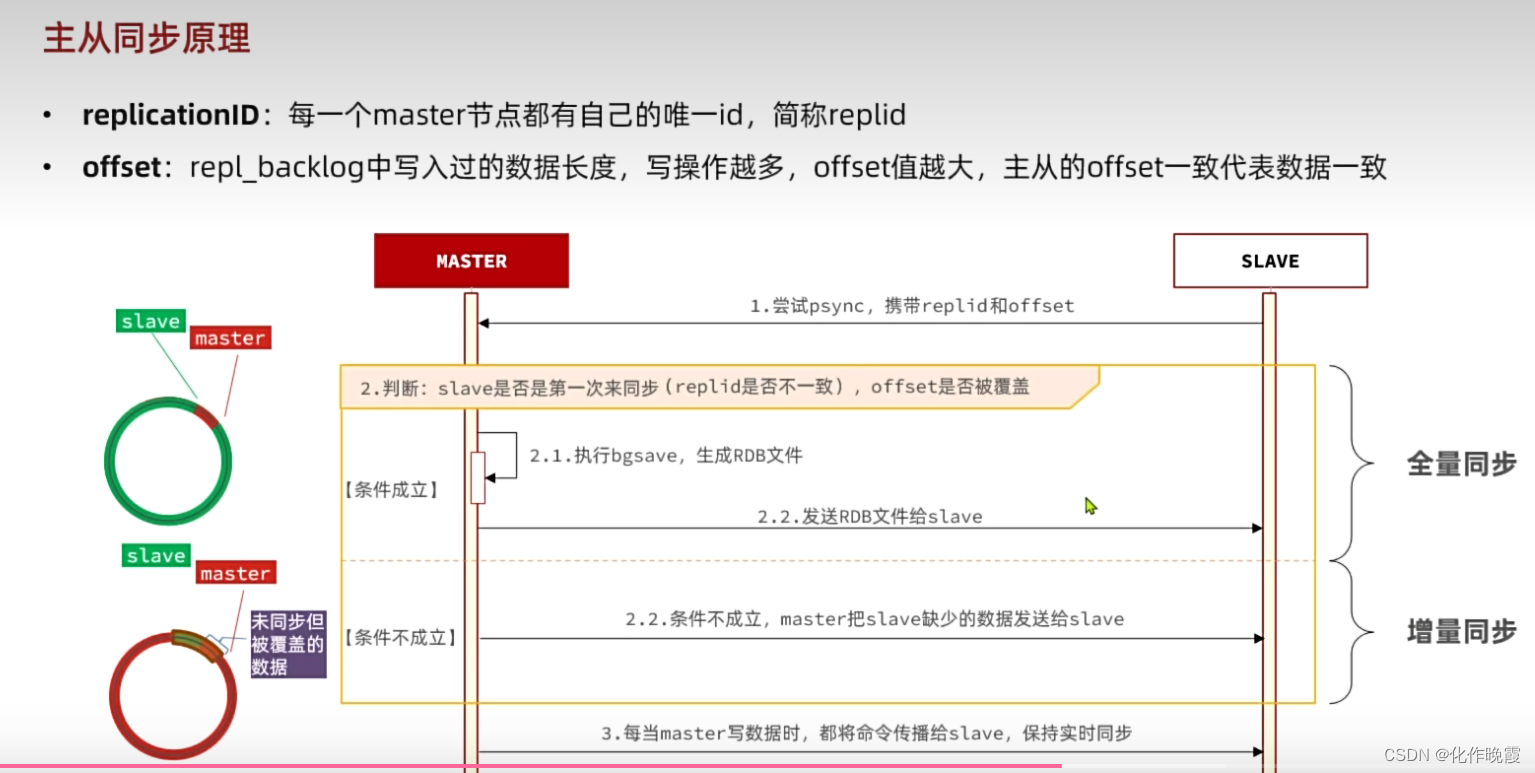
主从同步原理
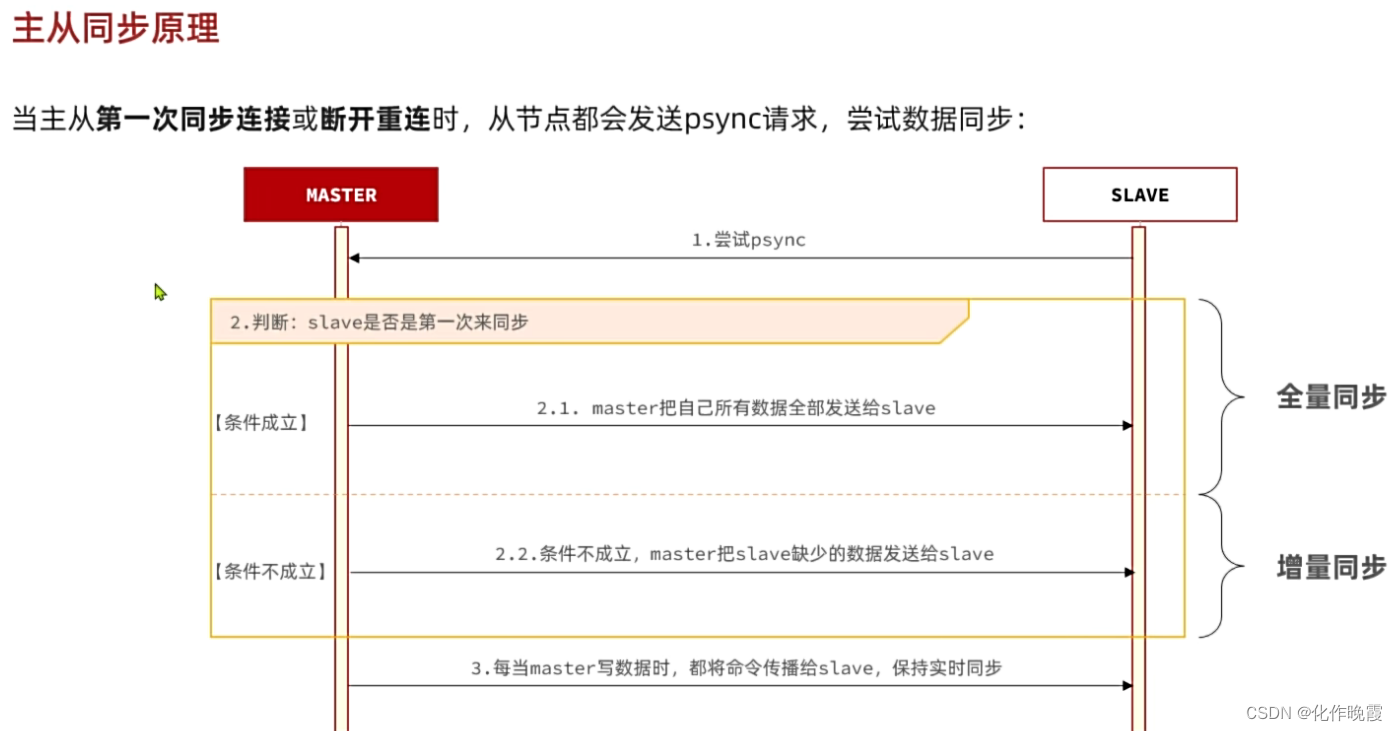
1.如何判断是否是第一次连接
replicationID:每一个master节点都有自己的ID
每个节点在连接之前都认为自己是主人,所以每个节点的ID都不一样,但是经过集群连接之后,每个的ID都一样。所以判断的标准就是,ID是否一样。

2.如何把数据都发送过去

将数据全都写在这个RDB文件里面
3.怎么把缺失的数据发送过去,又是怎么知道缺失了什么数据呢

就是在主从关系建立的时候,把所有的命令写入在一个repl_backlog文件,从节点也写入,当再次连接的时候,从节点就把offset值发送过去,然后,通过对比,就把主节点多的命令再发送过去。
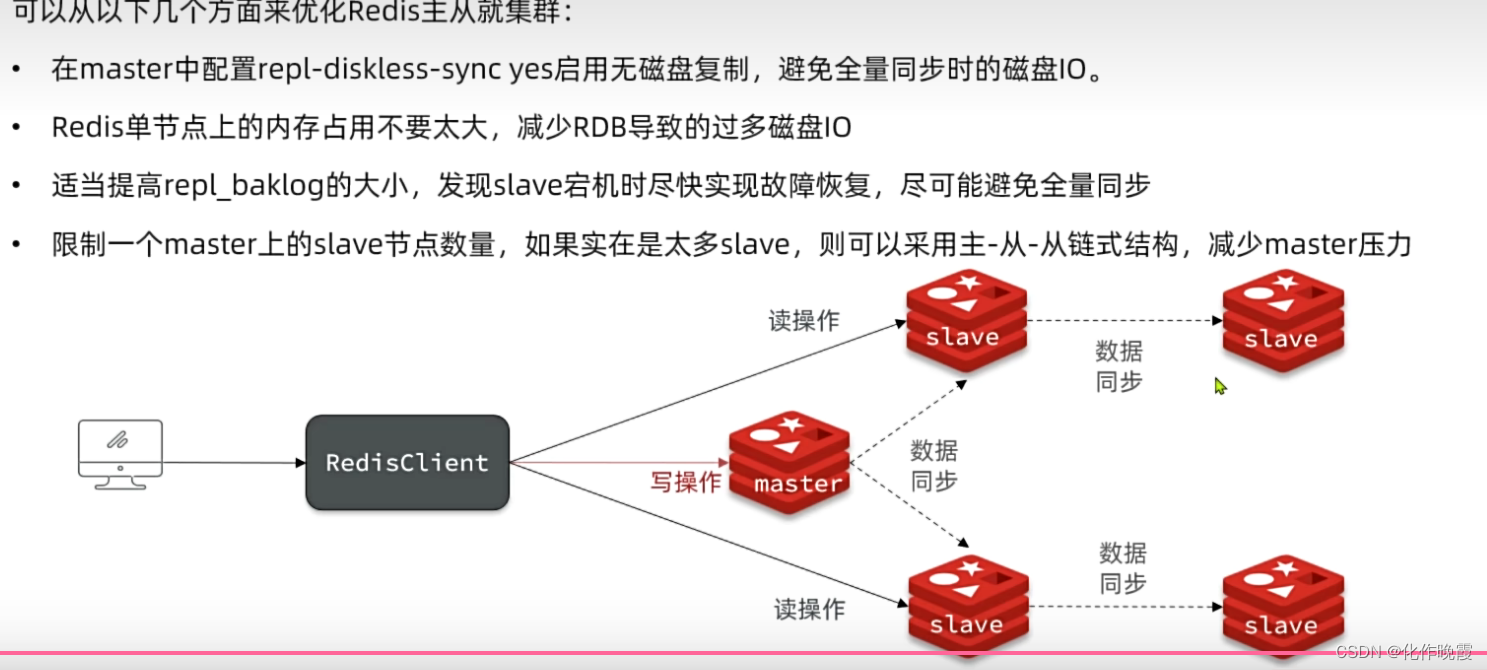
主从集群优化

redis使用的是环形数组存储的执行过的命令,异常情况就是数据越来越多覆盖了从节点还未执行的指令,这时候只能使用全量同步,但是我们要避免这样费时费力的操作。
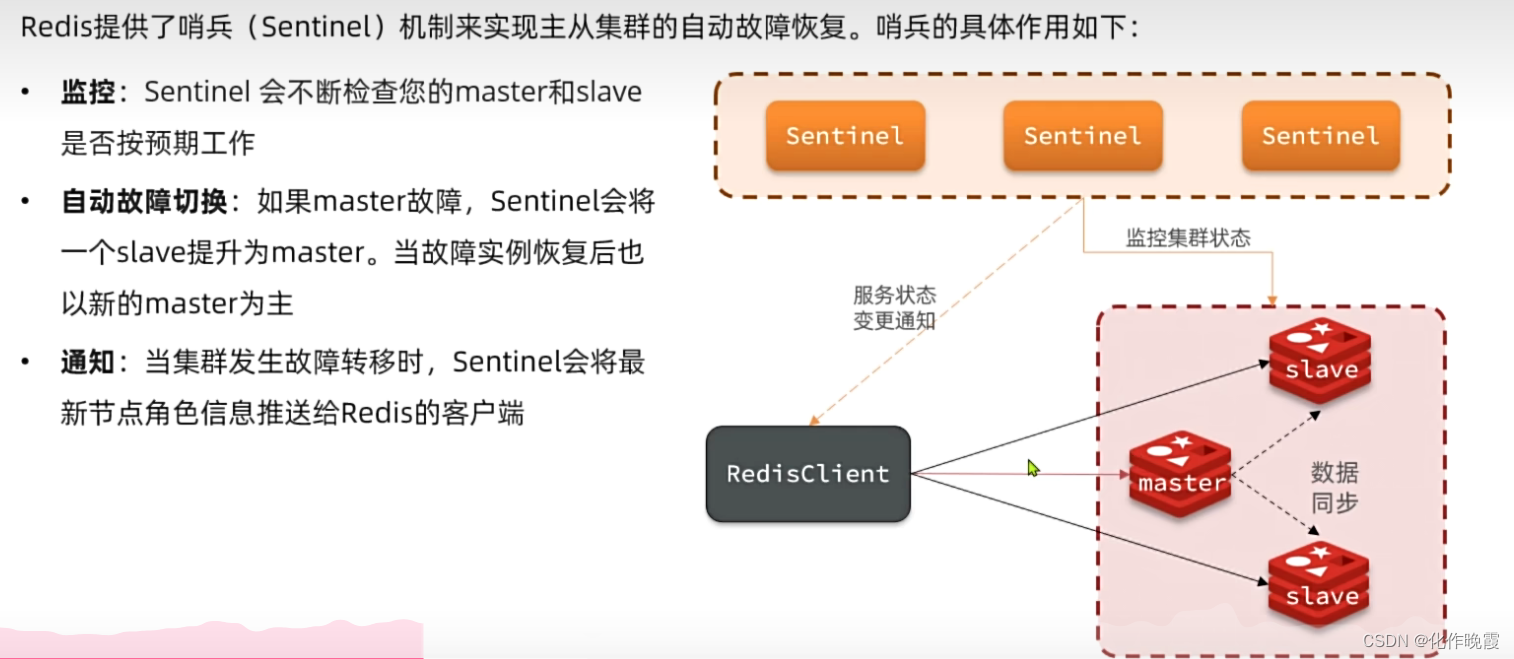
哨兵原理
但是出现故障的是主节点呢
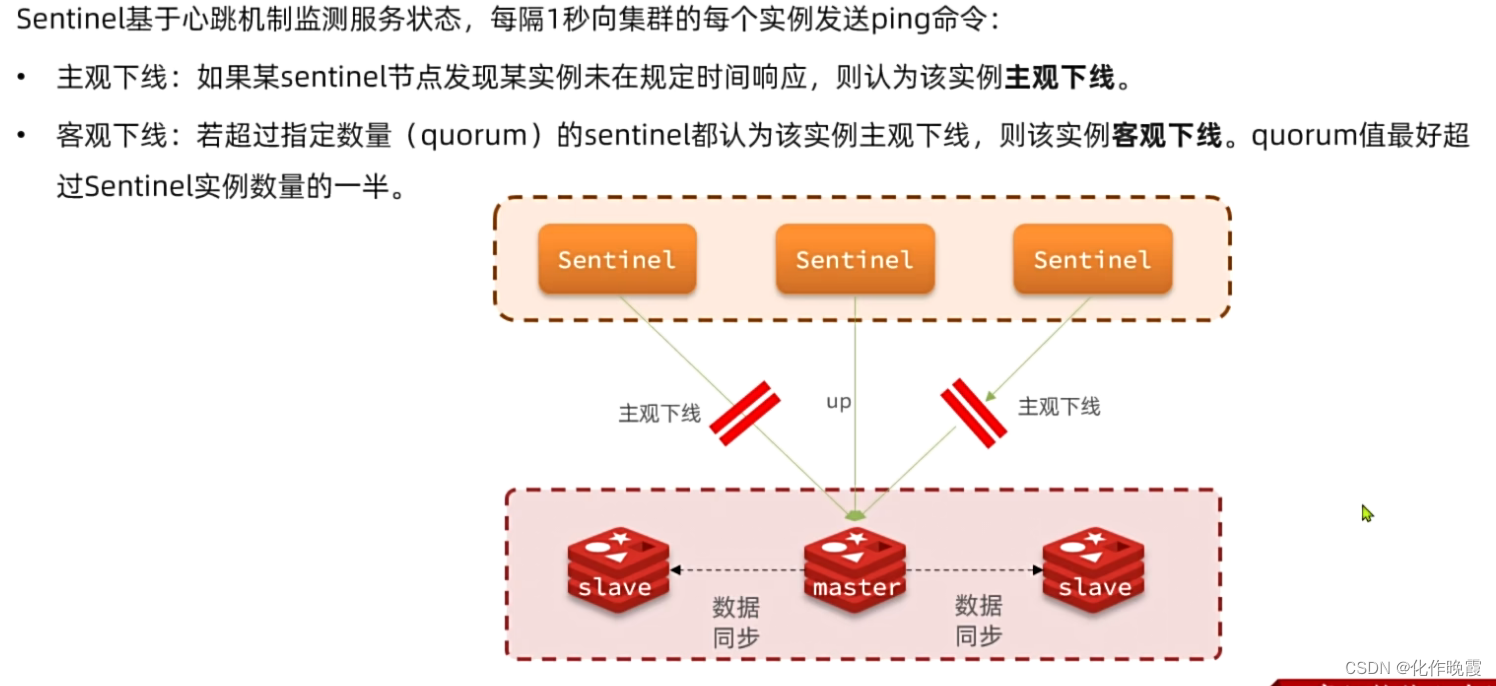
1.哨兵如何监控状态
2.选举新的master

3.如何实现故障转移
搭建哨兵集群
首先我们停掉之前搭建的主从集群
cd redis
docker compose down
找到准备好的文件sentinel.conf
内容如下:
sentinel announce-ip "192.168.202.129"
sentinel monitor hmaster 192.168.202.129 7001 2
sentinel down-after-milliseconds hmaster 5000
sentinel failover-timeout hmaster 60000sentinel announce-ip "129.168.202.129":声明当前sentinel的ip
hmaster是集群名称
sentinel monitor hmaster 192.168.202.129 7001 2 : 指定集群的主节点信息 2是指主观下线达到2的时候就会变成客观下线。
-
sentinel down-after-milliseconds hmaster 5000:声明master节点超时多久后被标记下线 -
sentinel failover-timeout hmaster 60000:在第一次故障转移失败后多久再次重试
在redis文件夹下搭建三个目录s1 s2 s3。
然后将sentinel.conf复制到s1 s2 s3。
更改compose.yaml的文件内容
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002", "--slaveof", "192.168.150.101", "7001"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003", "--slaveof", "192.168.150.101", "7001"]
s1:
image: redis
container_name: s1
volumes:
- /root/redis/s1:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27001"]
s2:
image: redis
container_name: s2
volumes:
- /root/redis/s2:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27002"]
s3:
image: redis
container_name: s3
volumes:
- /root/redis/s3:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27003"]docker compose up -d
然后就搭建好了哨兵集群。
当我们运行docker stop r1 便会发现s1 s2 s3 日志发生了变化。
Sentinel三作用:
-
集群监控
-
故障恢复
-
状态通知
Sentinel如何判断一个redis实例是否健康?
-
每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线(
sdown) -
如果大多数sentinel都认为实例主观下线,则判定服务客观下线(
odown)
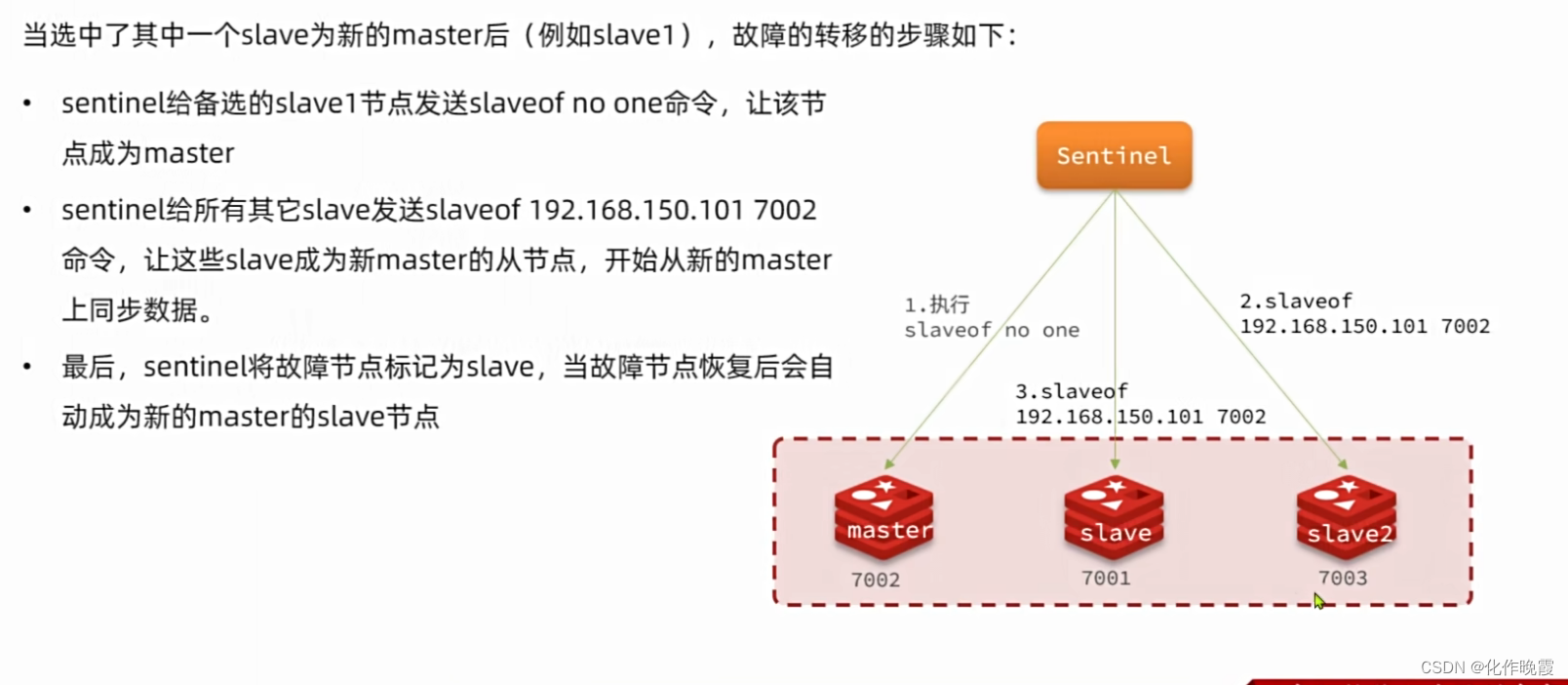
故障转移步骤有哪些?
-
首先要在
sentinel中选出一个leader,由leader执行failover -
选定一个
slave作为新的master,执行slaveof noone,切换到master模式 -
然后让所有节点都执行
slaveof新master -
修改故障节点配置,添加
slaveof新master
sentinel选举leader的依据是什么?
-
票数超过sentinel节点数量1半
-
票数超过quorum数量
-
一般情况下最先发起failover的节点会当选
sentinel从slave中选取master的依据是什么?
-
首先会判断slave节点与master节点断开时间长短,如果超过
down-after-milliseconds * 10则会排除该slave节点 -
然后判断slave节点的
slave-priority值,越小优先级越高,如果是0则永不参与选举(默认都是1)。 -
如果
slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高 -
最后是判断slave节点的
run_id大小,越小优先级越高(通过info server可以查看run_id)。
分片集群
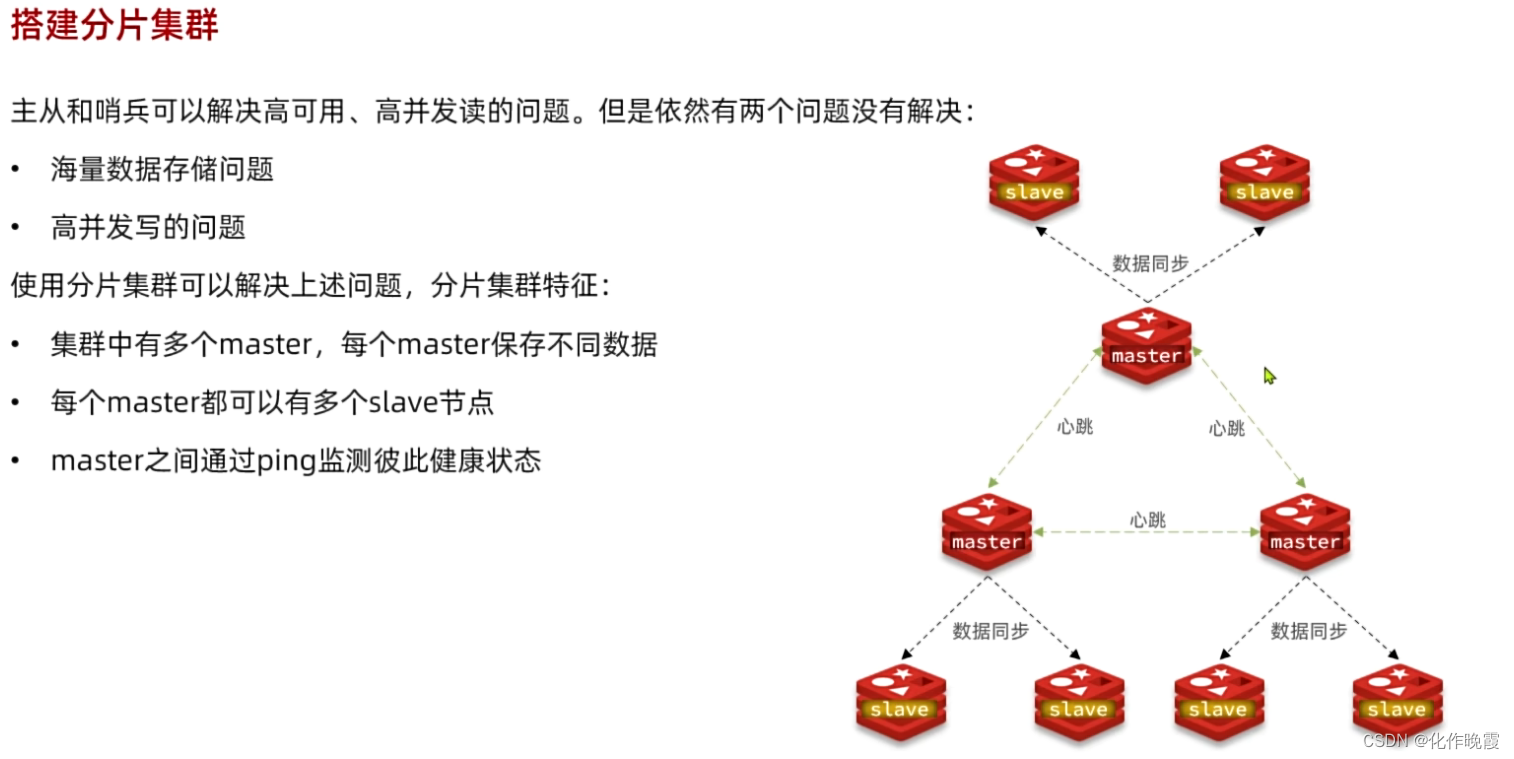
搭建分片集群
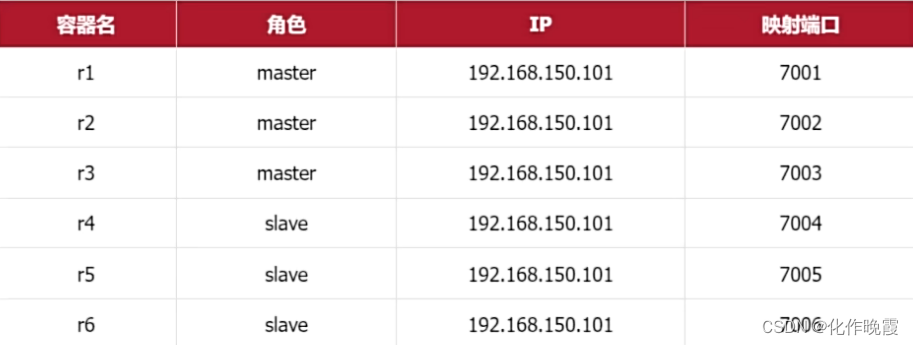
三主三从。
首先在根目录下创建redis-cluster
将compose.yaml文件的内容替换为这个。
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r4:
image: redis
container_name: r4
network_mode: "host"
entrypoint: ["redis-server", "--port", "7004", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r5:
image: redis
container_name: r5
network_mode: "host"
entrypoint: ["redis-server", "--port", "7005", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r6:
image: redis
container_name: r6
network_mode: "host"
entrypoint: ["redis-server", "--port", "7006", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]然后cd redis-cluster
接着将compose.yaml文件复制在这个文件
docker compose up -d 启动
ps -ef | grep redis 查看redis运行情况
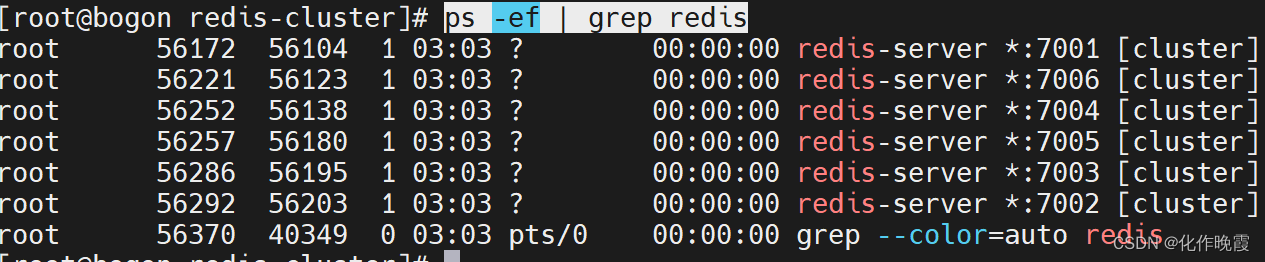
但是现在它们还没有关联关系,所以我们需要创建集群。
# 进入任意节点容器
docker exec -it r1 bash
# 然后,执行命令
redis-cli --cluster create --cluster-replicas 1 \
192.168.202.129:7001 192.168.202.129:7002 192.168.202.129:7003 \
192.168.202.129:7004 192.168.202.129:7005 192.168.202.129:7006
-
redis-cli --cluster:代表集群操作命令 -
create:代表是创建集群 -
--cluster-replicas 1:指定集群中每个master的副本个数为1-
此时
节点总数 ÷ (replicas + 1)得到的就是master的数量n。因此节点列表中的前n个节点就是master,其它节点都是slave节点,随机分配到不同master
-
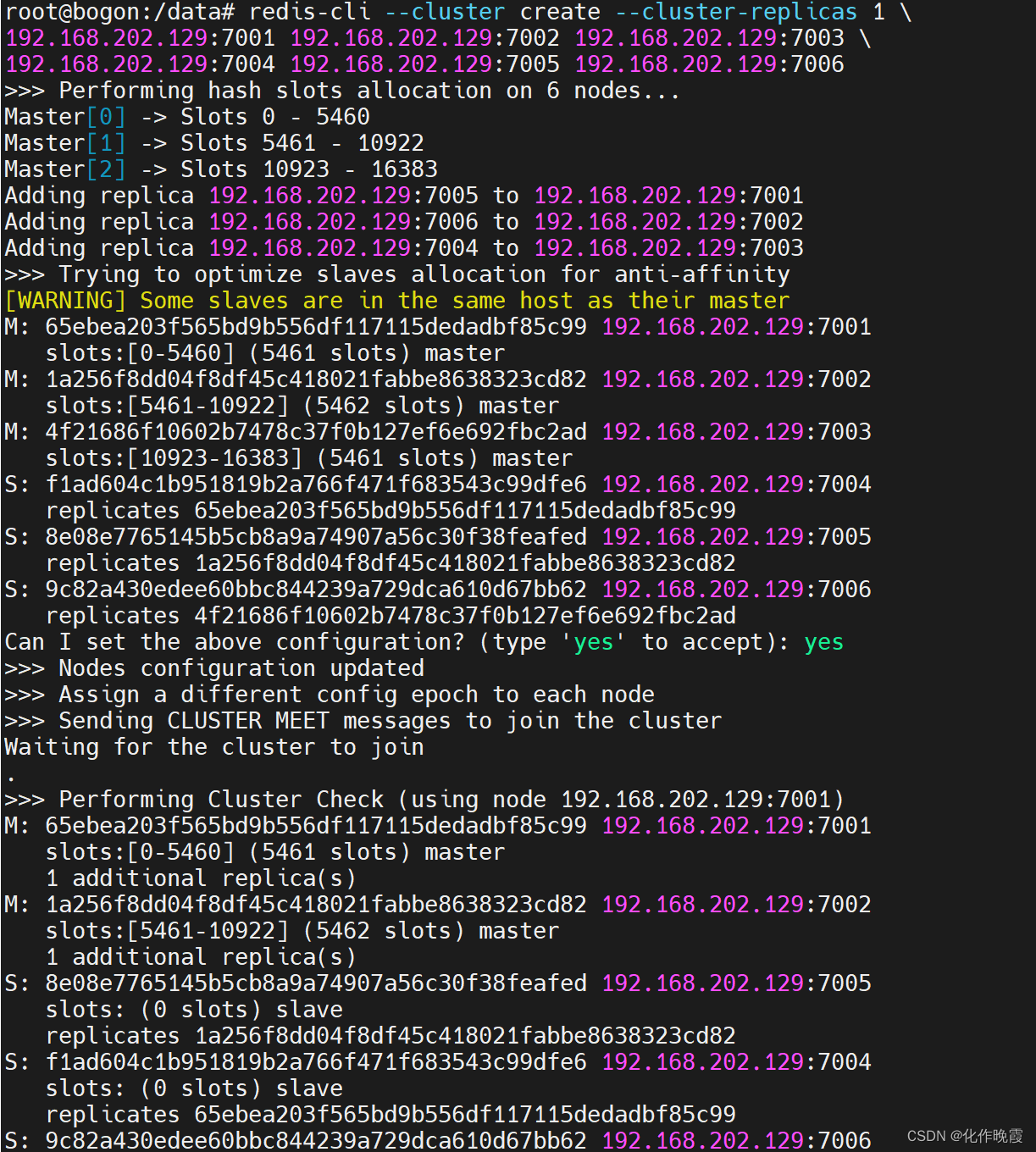
这里展示了集群中master与slave节点分配情况,并询问你是否同意。节点信息如下:
-
7001是master,节点id后6位是da134f -
7002是master,节点id后6位是862fa0 -
7003是master,节点id后6位是ad5083 -
7004是slave,节点id后6位是391f8b,认ad5083(7003)为master -
7005是slave,节点id后6位是e152cd,认da134f(7001)为master -
7006是slave,节点id后6位是4a018a,认862fa0(7002)为master
散列插槽
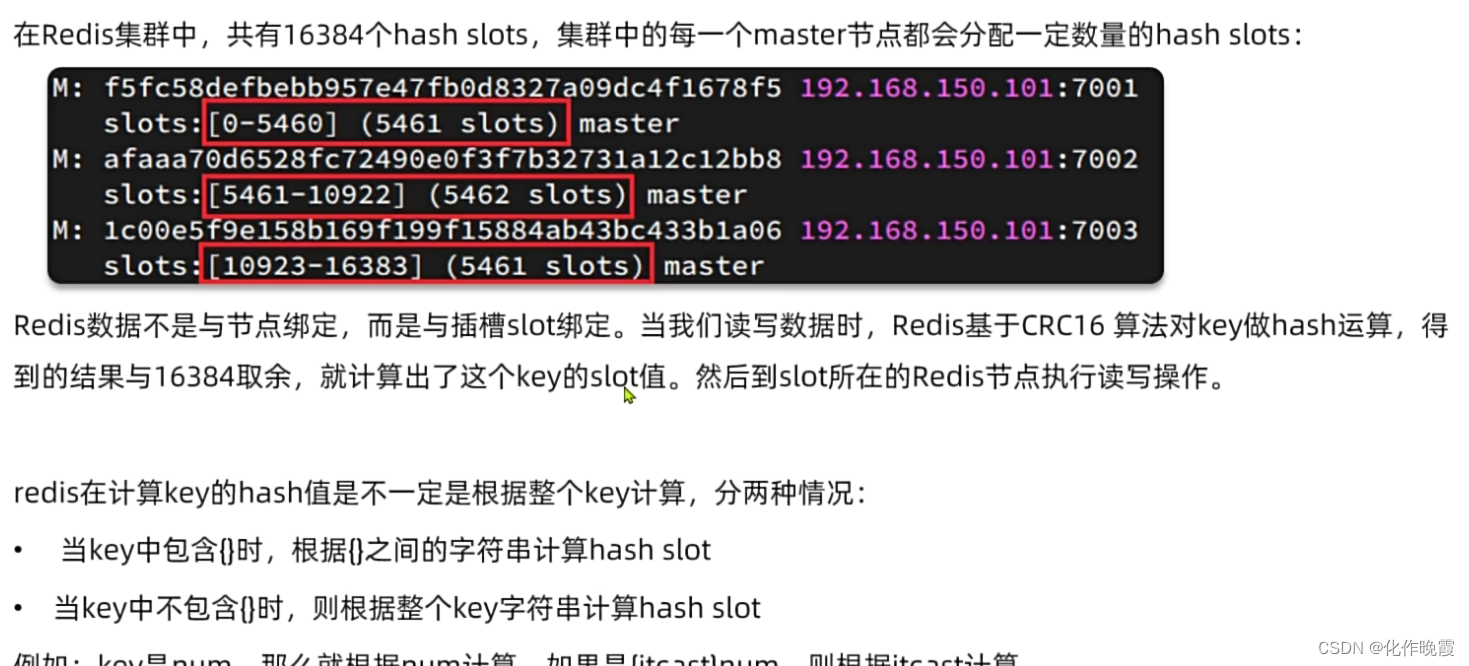
存数据不是跟据节点,而是根据槽来存数据。
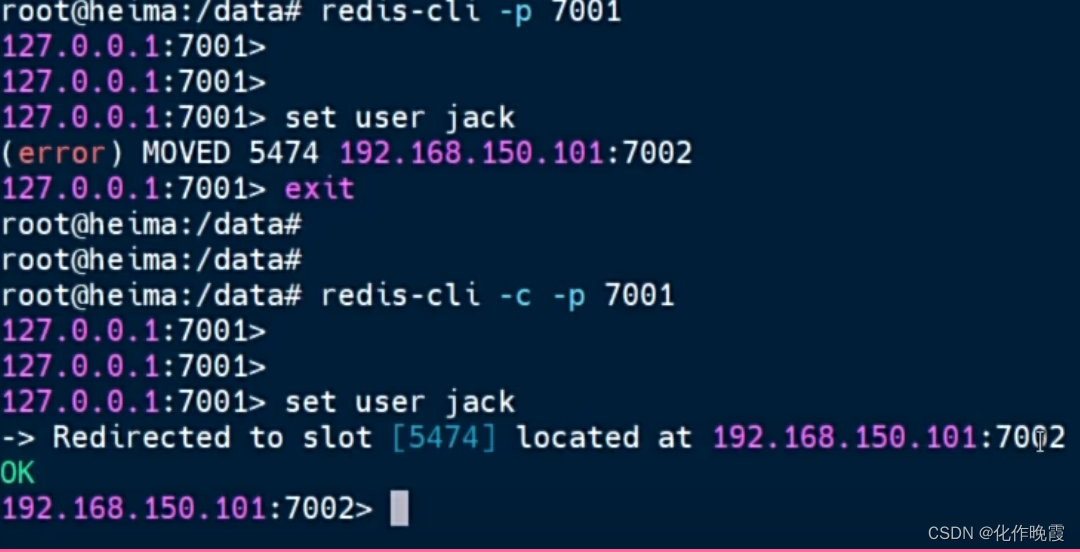
我们设数据的时候,不要用
redis-cli -p 7001因为可能计算出来的槽不是在7001管控范围内。
所以我们需要以集群模式存储数据
redis-cli -c -p 7001表示我是以集群模式连接,现在是7001而已,要是存数据的时候,依然可以随意跳转。
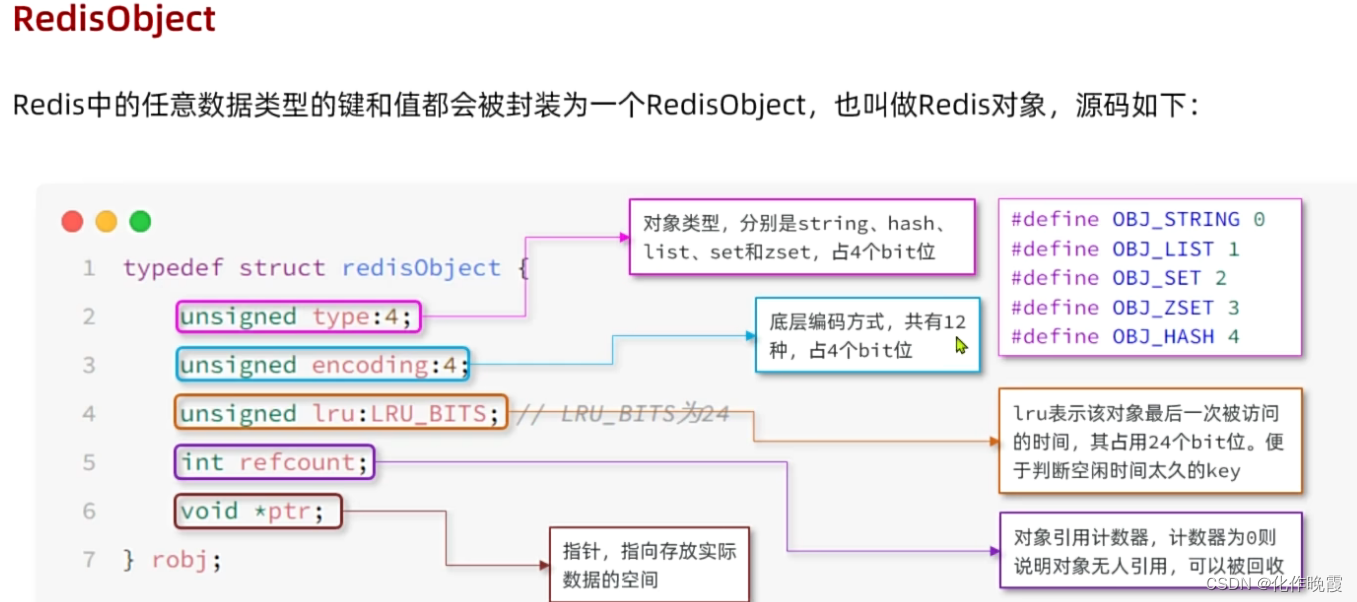
Redis数据结构
RedisObject
SkipList
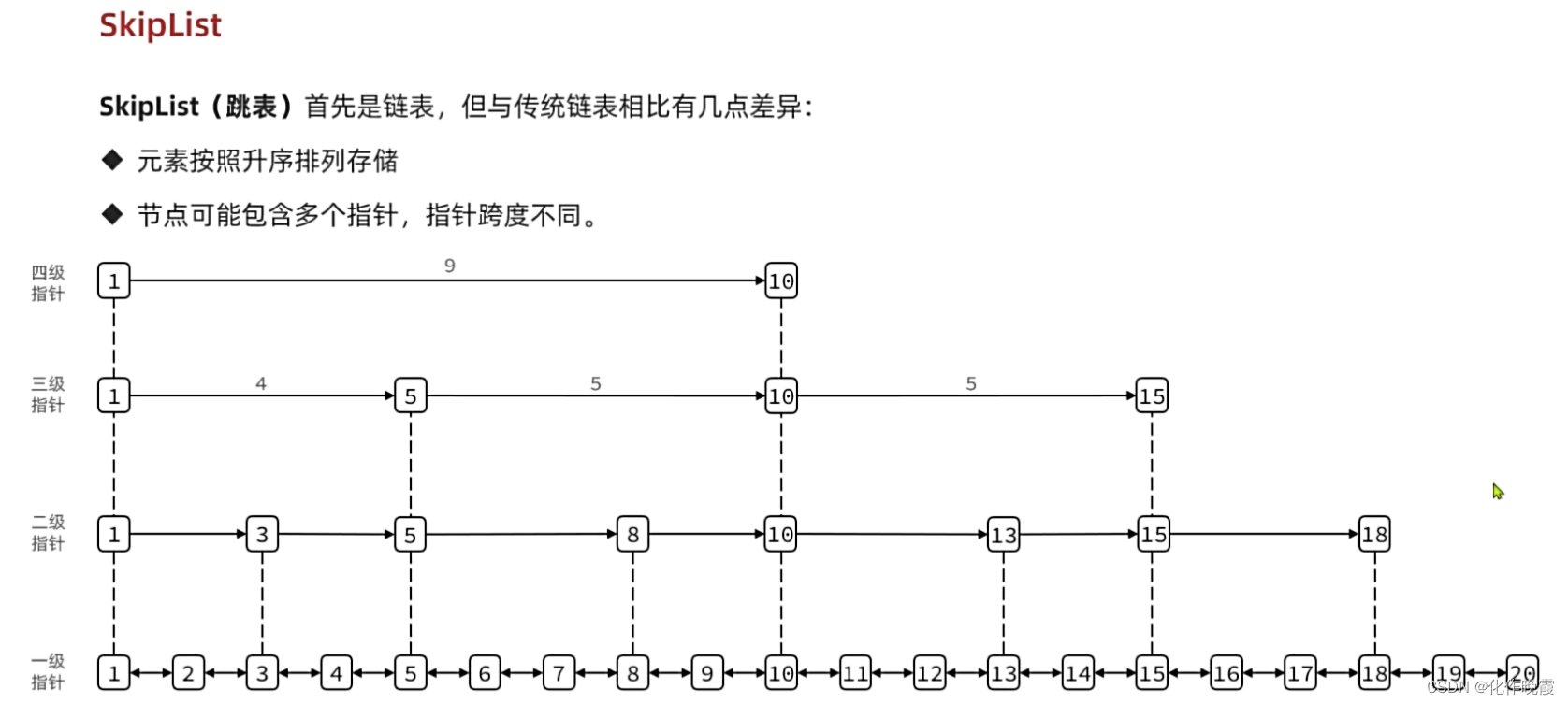
SortedSet

Redis内存回收机制
过期key处理
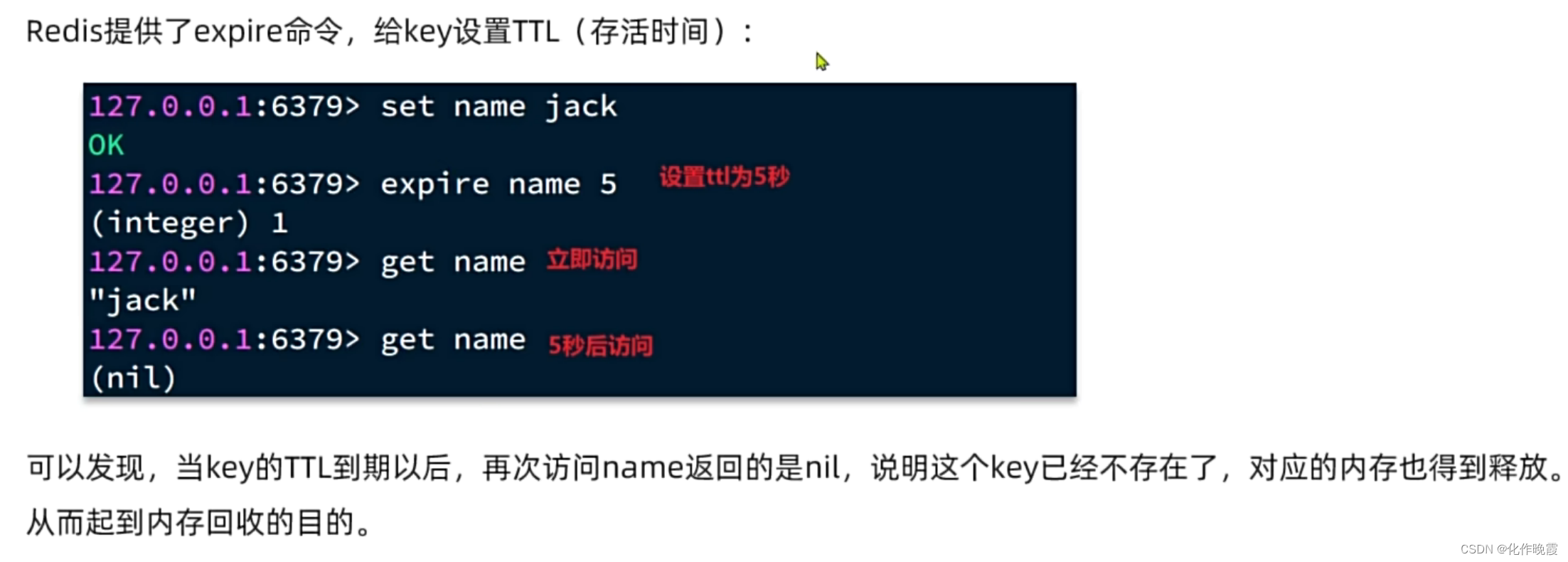
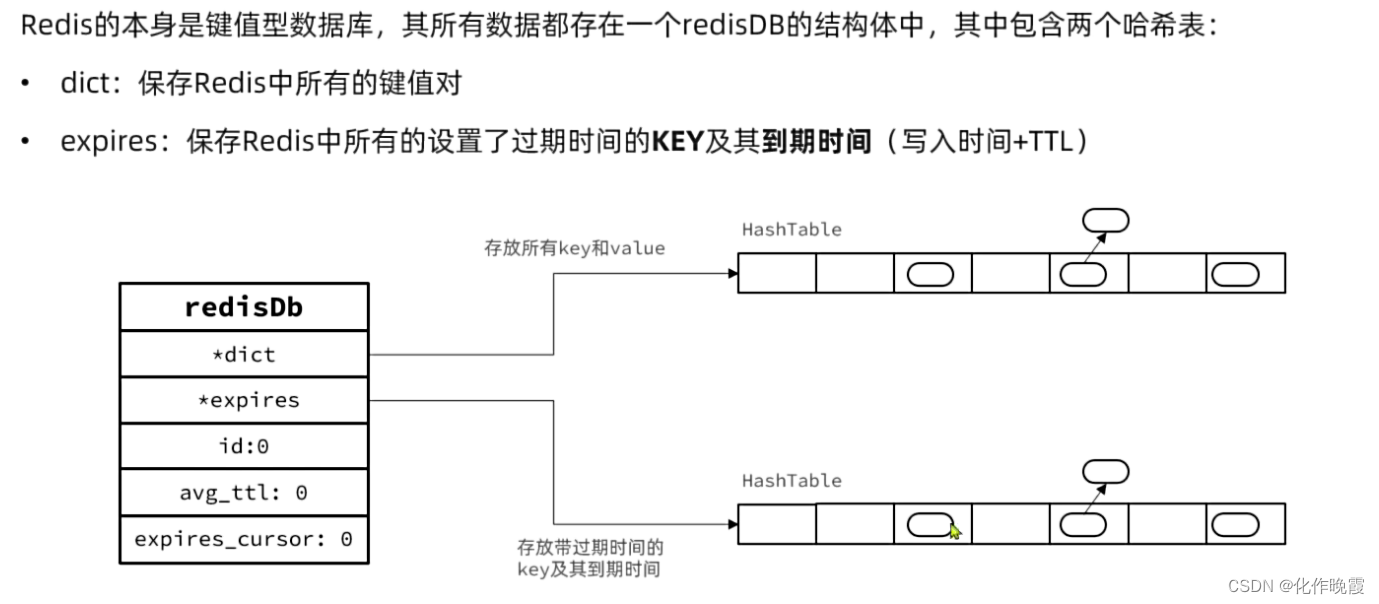
redis是怎么知道key过期了呢?

内存淘汰策略

因为我们总是倾向于淘汰对业务不重要的key,所以我们优先选择带有volatile
第二就是假如以前不怎么使用的Key刚好被访问,但是经常使用的刚好没有被访问,可能经常使用的key就被lru淘汰了,所以更加推荐使用lfu。

缓存问题
缓存一致性
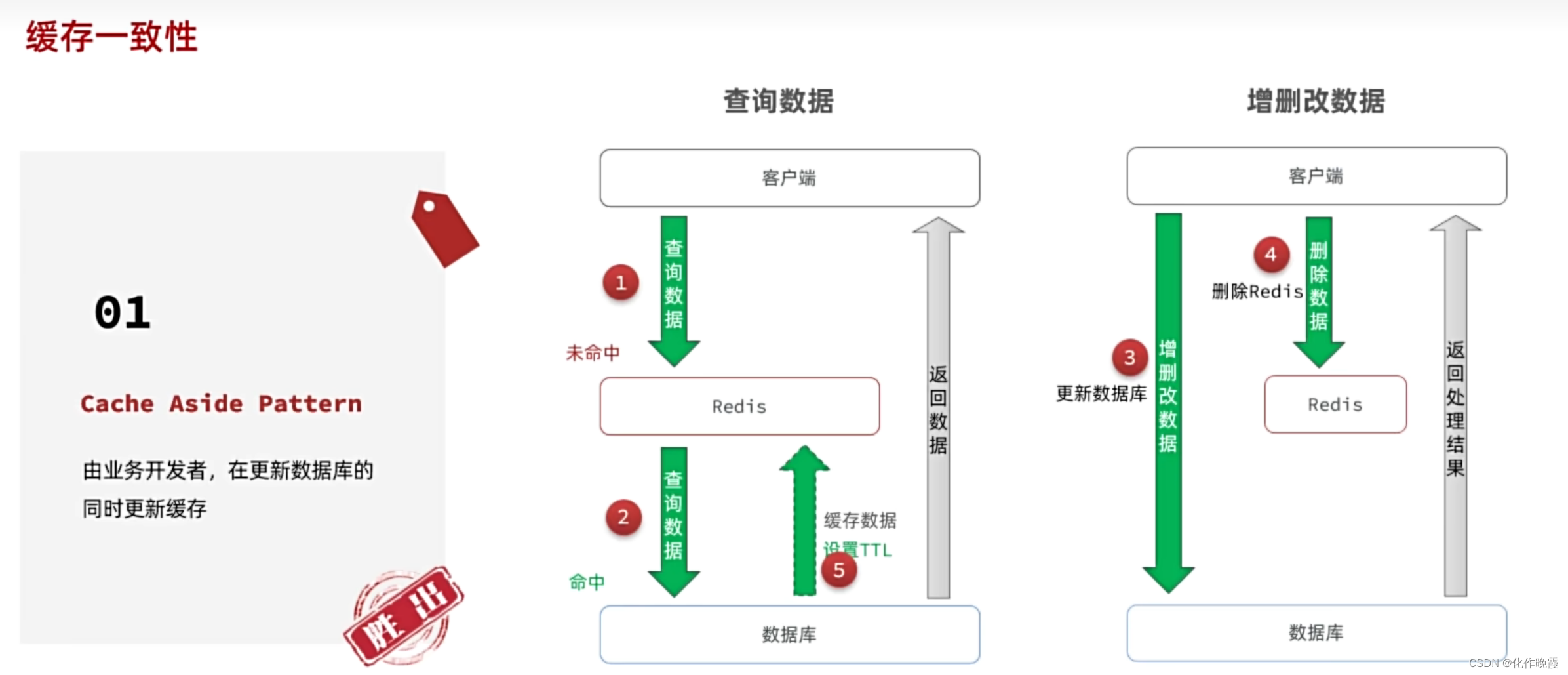
主要是高并发查询更改同时存在。

缓存穿透
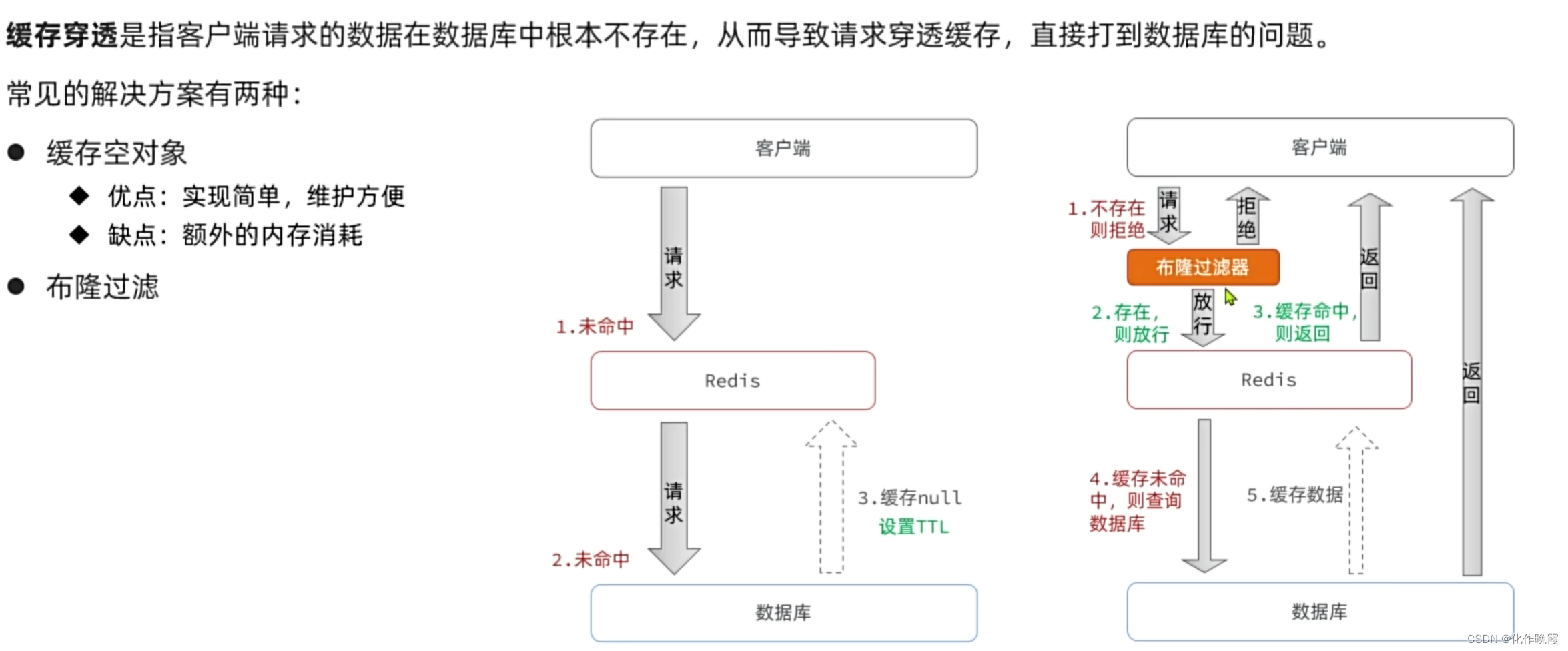
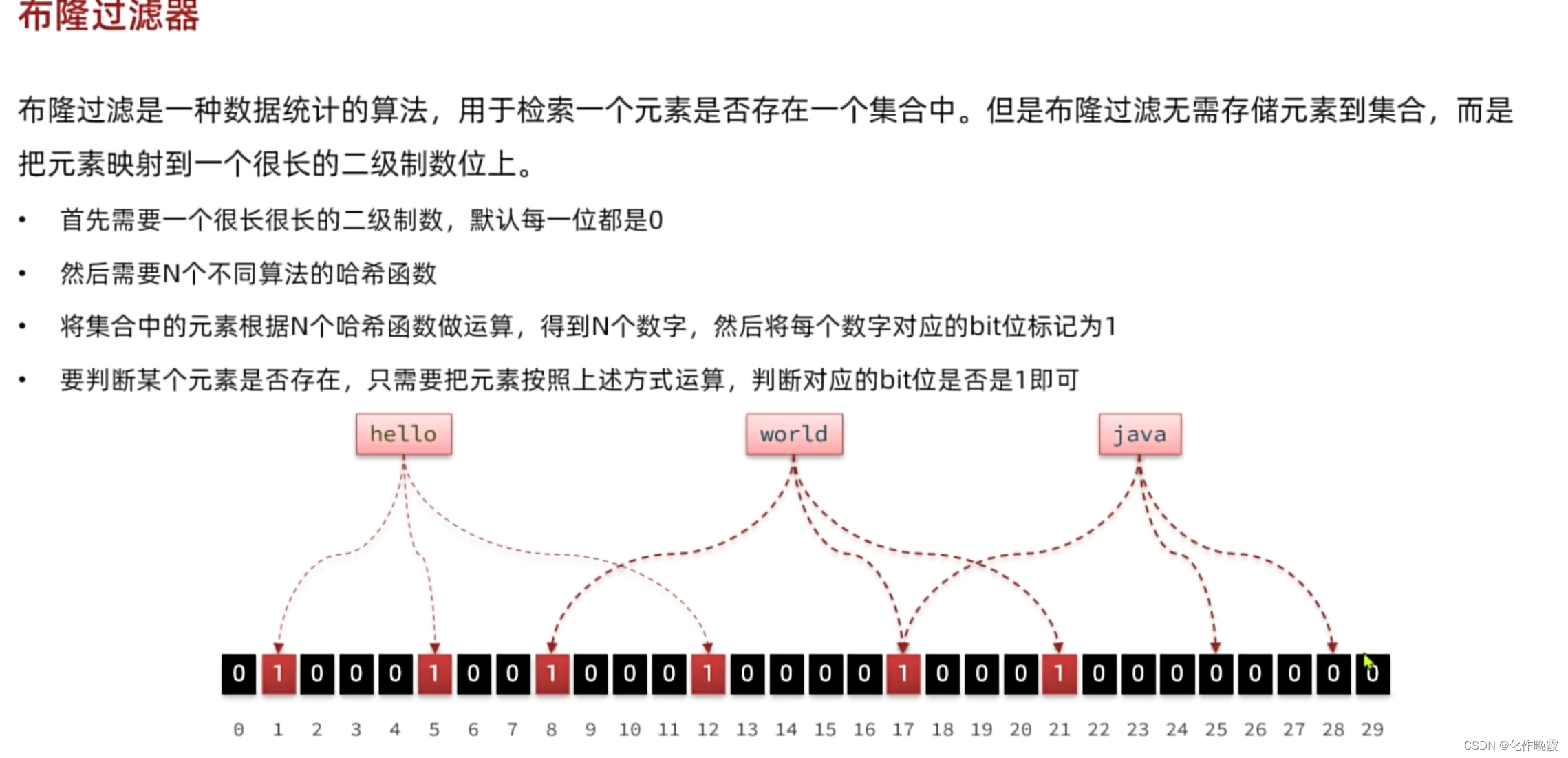
可能会有一个没有存储的数据刚好计算之后就是之前已经被标注的1.
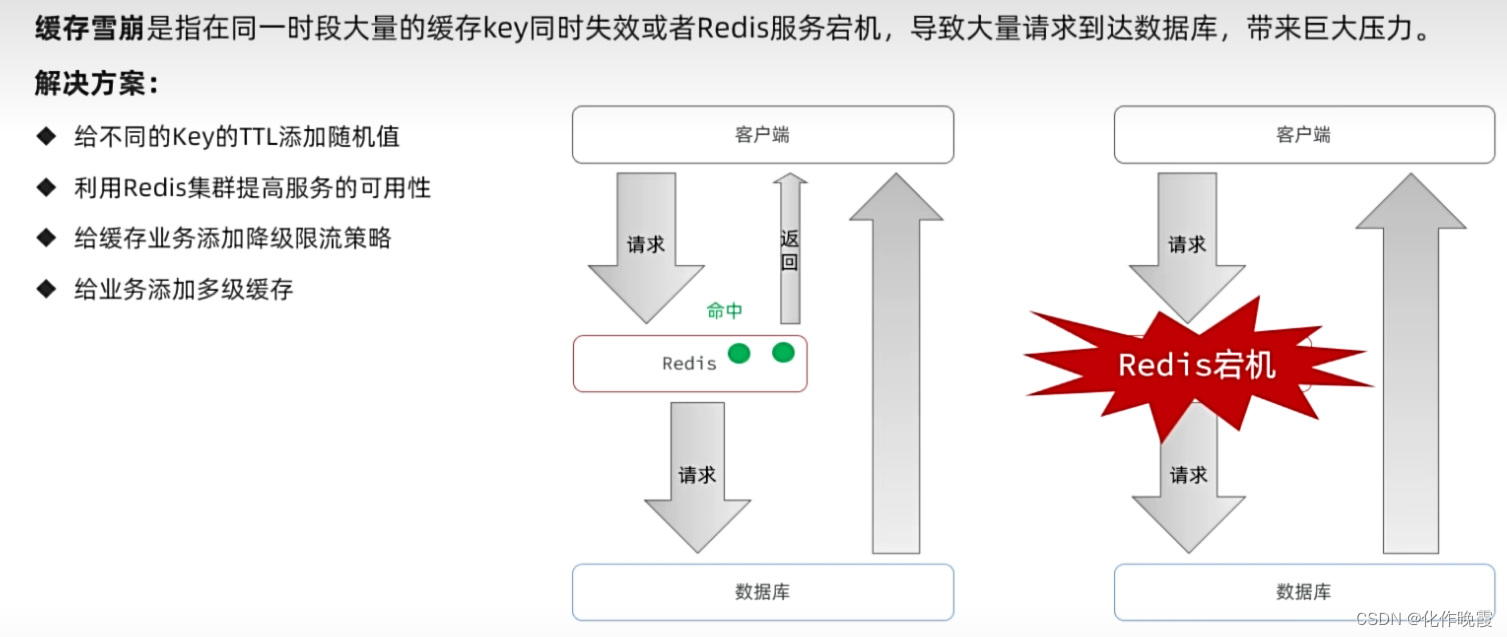
缓存雪崩
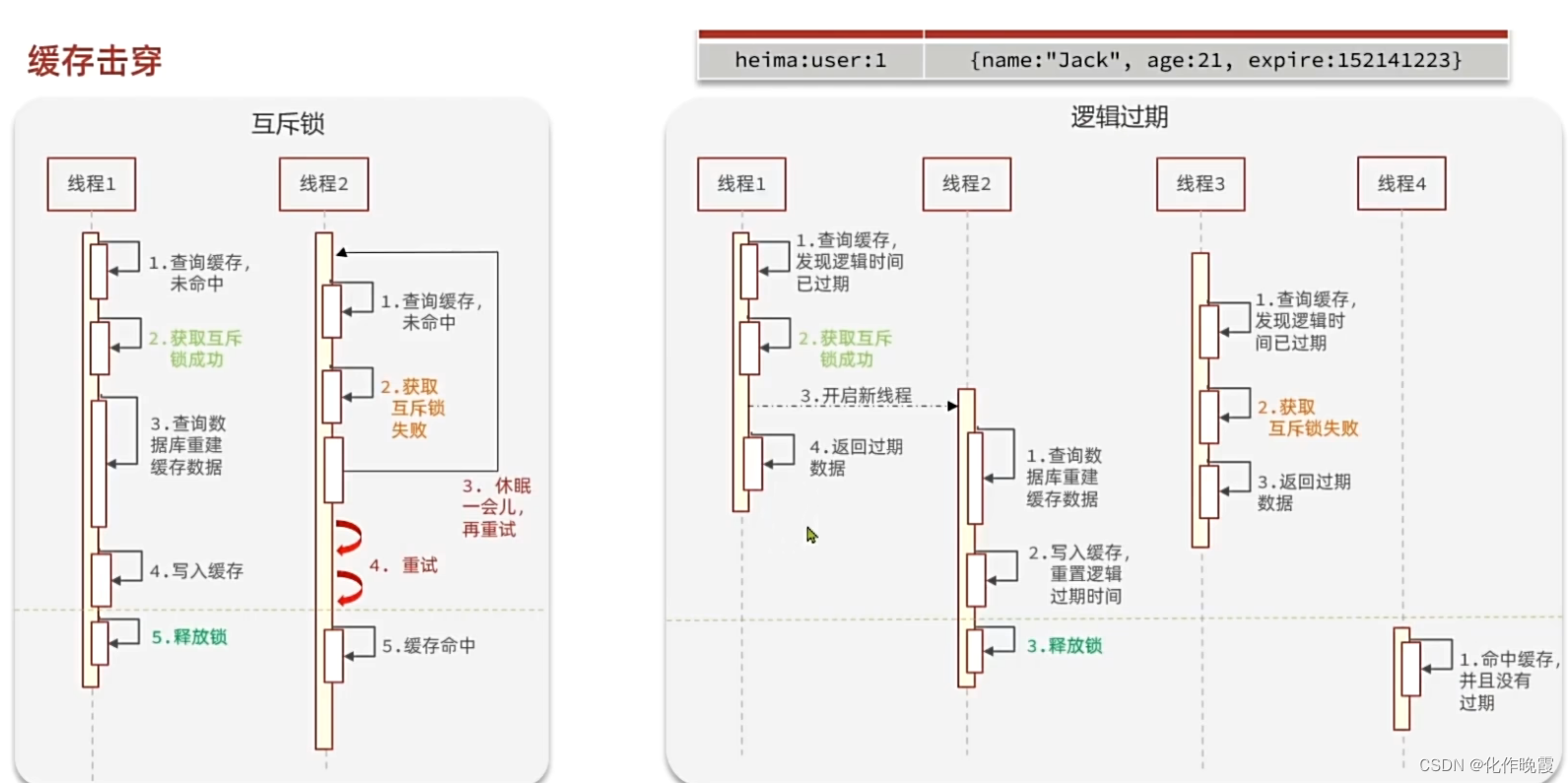
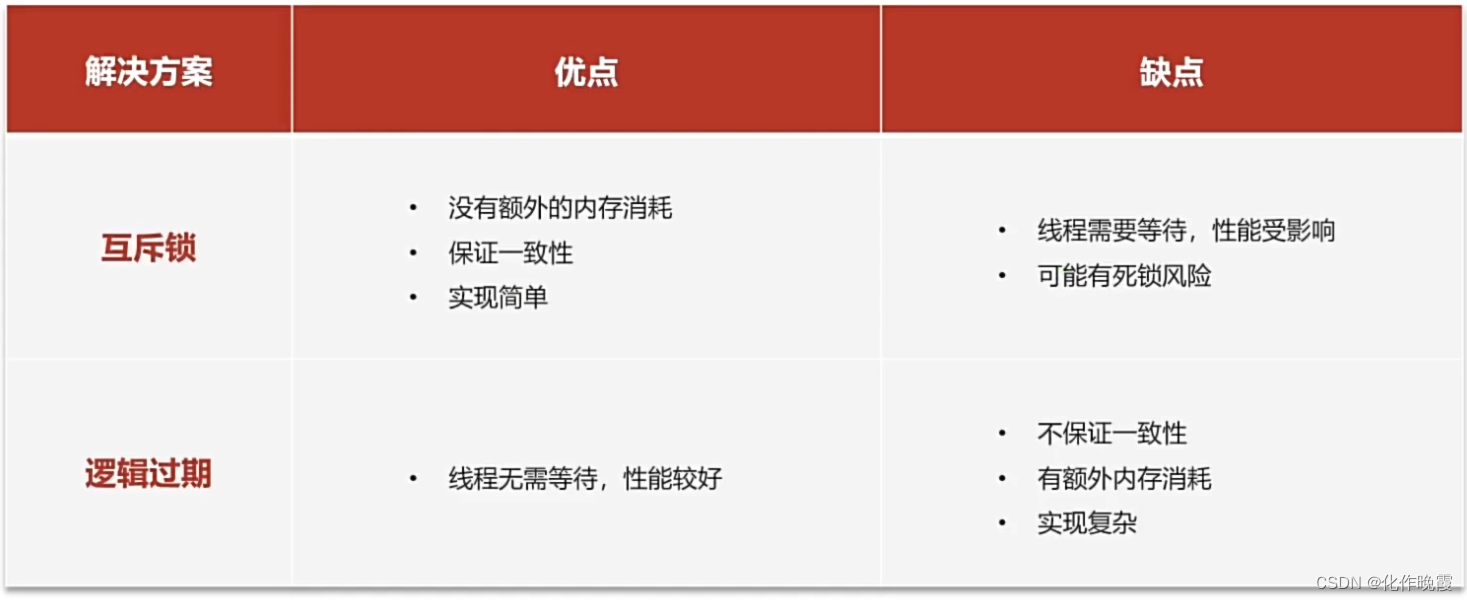
缓存击穿
















 5638
5638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









