






题目概况
本次题目是来自VCTF纳新赛的题目
链接
https://ctf.venomsec.com/#/index![]() https://ctf.venomsec.com/#/index本次的文案是以reverse方向为主的,所以就在这两个题目上下手
https://ctf.venomsec.com/#/index本次的文案是以reverse方向为主的,所以就在这两个题目上下手

先来看第一个题目
ezre
先进行查壳操作,可以看到是64位的
打开前的准备

用ida打开文件之后,进入以下界面

同样的,按F5进入mian函数界面
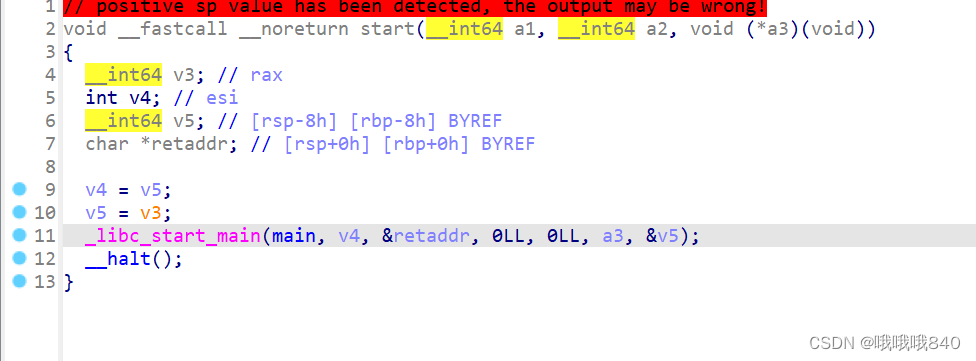
点击mian进入主函数,得到以下代码

代码如下:
__int64 __fastcall main(int a1, char **a2, char **a3)
{
size_t v3; // rax
const char *v4; // rax
size_t v6; // [rsp+8h] [rbp-8h]
__isoc99_scanf("%21s", byte_41E0);
v6 = strlen(byte_41E0);
v3 = strlen(aThi51sKey);
sub_1492(&unk_4160, aThi51sKey, v3);
sub_16B3(&unk_4160, byte_41E0, v6);
v4 = (const char *)sub_1249(byte_41E0, (unsigned int)v6);
if ( !strcmp(s1, v4) )
puts("success!");
else
puts("fail!");
return 0LL;
}代码分析
大致思路
首先,在代码的最开头,我们通过伪C代码的分析可以知道:
第7行先进行代码的输入(最多能输入21个字符),将这段字符的位置传给byte_41E0的位置
第8行和第9行分别计算两个位置所带的字符串的长度
第10行到第12行对上面的两个位置以及unk_4160进行某些操作
现在的主要思路就是在第10到第12行的位置的分许中来进行
内部函数的分析
第10行
点击进去进行分析
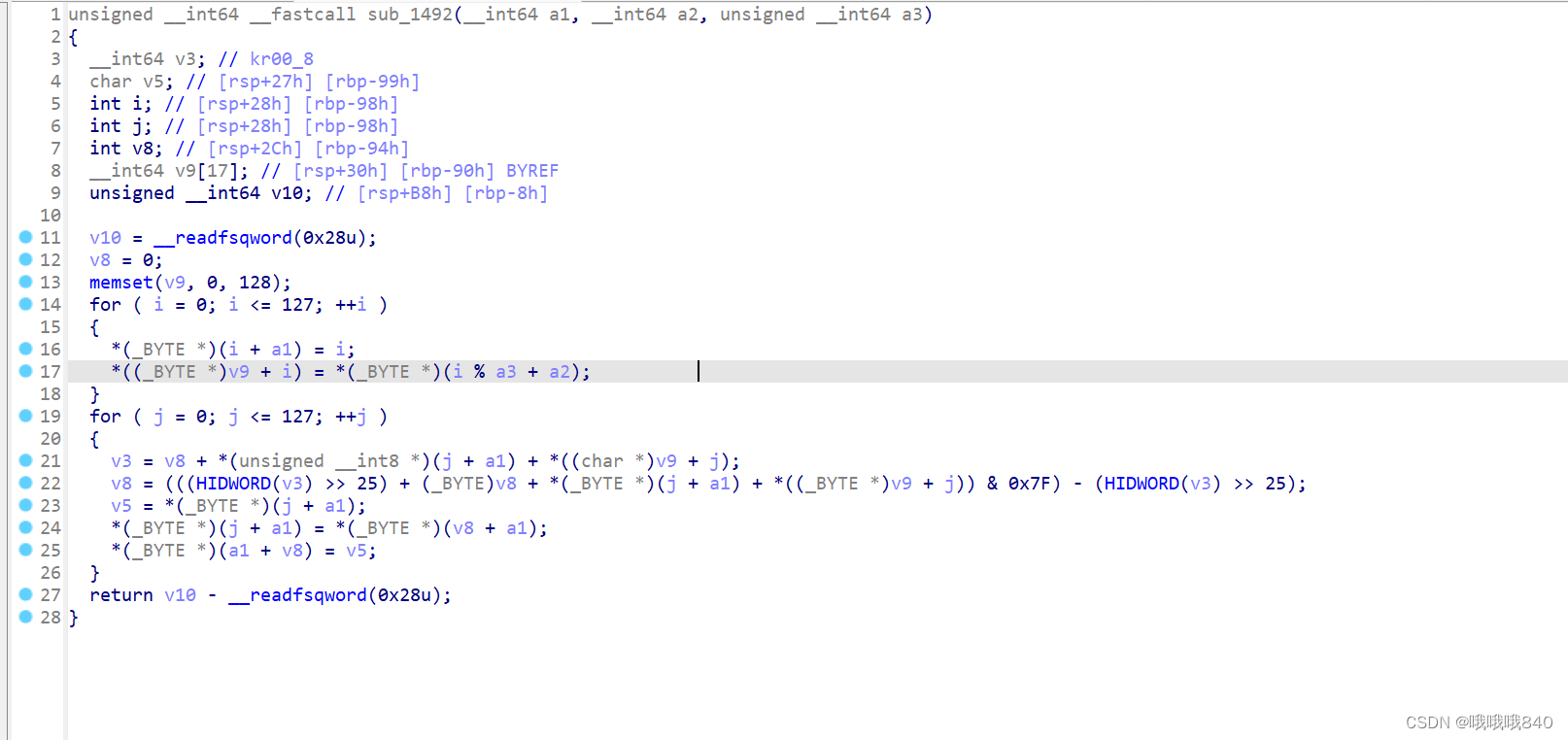
代码如下:
unsigned __int64 __fastcall sub_1492(__int64 a1, __int64 a2, unsigned __int64 a3)
{
__int64 v3; // kr00_8
char v5; // [rsp+27h] [rbp-99h]
int i; // [rsp+28h] [rbp-98h]
int j; // [rsp+28h] [rbp-98h]
int v8; // [rsp+2Ch] [rbp-94h]
__int64 v9[17]; // [rsp+30h] [rbp-90h] BYREF
unsigned __int64 v10; // [rsp+B8h] [rbp-8h]
v10 = __readfsqword(0x28u);
v8 = 0;
memset(v9, 0, 128);
for ( i = 0; i <= 127; ++i )
{
*(_BYTE *)(i + a1) = i;
*((_BYTE *)v9 + i) = *(_BYTE *)(i % a3 + a2);
}
for ( j = 0; j <= 127; ++j )
{
v3 = v8 + *(unsigned __int8 *)(j + a1) + *((char *)v9 + j);
v8 = (((HIDWORD(v3) >> 25) + (_BYTE)v8 + *(_BYTE *)(j + a1) + *((_BYTE *)v9 + j)) & 0x7F) - (HIDWORD(v3) >> 25);
v5 = *(_BYTE *)(j + a1);
*(_BYTE *)(j + a1) = *(_BYTE *)(v8 + a1);
*(_BYTE *)(a1 + v8) = v5;
}
return v10 - __readfsqword(0x28u);
}我们主要来考虑一下for循环的问题
第一个for循环的代码逻辑
首先它将0到127位置上的值都变为了i(一一对应的,第i个位置就是i)
也就可以理解为将这些值初始化的一个操作
紧接着,从a2取地址值将位置进行操作传给v9
a3是从main函数里面传输进去的

要注意的是,这里的a2不是字符,是a2的地址a3是mian函数里面的字符串长度
![]()

同样的,看到i%a3的计算,我们不难看出
for ( i = 0; i <= 127; ++i )
{
*(_BYTE *)(i + a1) = i;
*((_BYTE *)v9 + i) = *(_BYTE *)(i % a3 + a2);
}这里的rc4加密算法的模已经被更改了
(正常的rc4的模为256,而这里为128,更改过后的要注意变化)
总体来说,分为了以下几步:
进入加密算法函数看加密的过程进行分析
base64加密过程
点进去base64加密过程的函数中,我们可以看到这样的一串

这是一个base64算法的加密过程
点击下面的a123456789xyza进去,我们可以得到这样的一串字符串

这就是经过更改的表
注意:这一串字符串并不是原本的base64解码的表格
原本的表格是这样的

由此可知,我们的数表在这里进行了更改
对该代码进行base64解码
在线工具推荐使用赛博厨子 网址
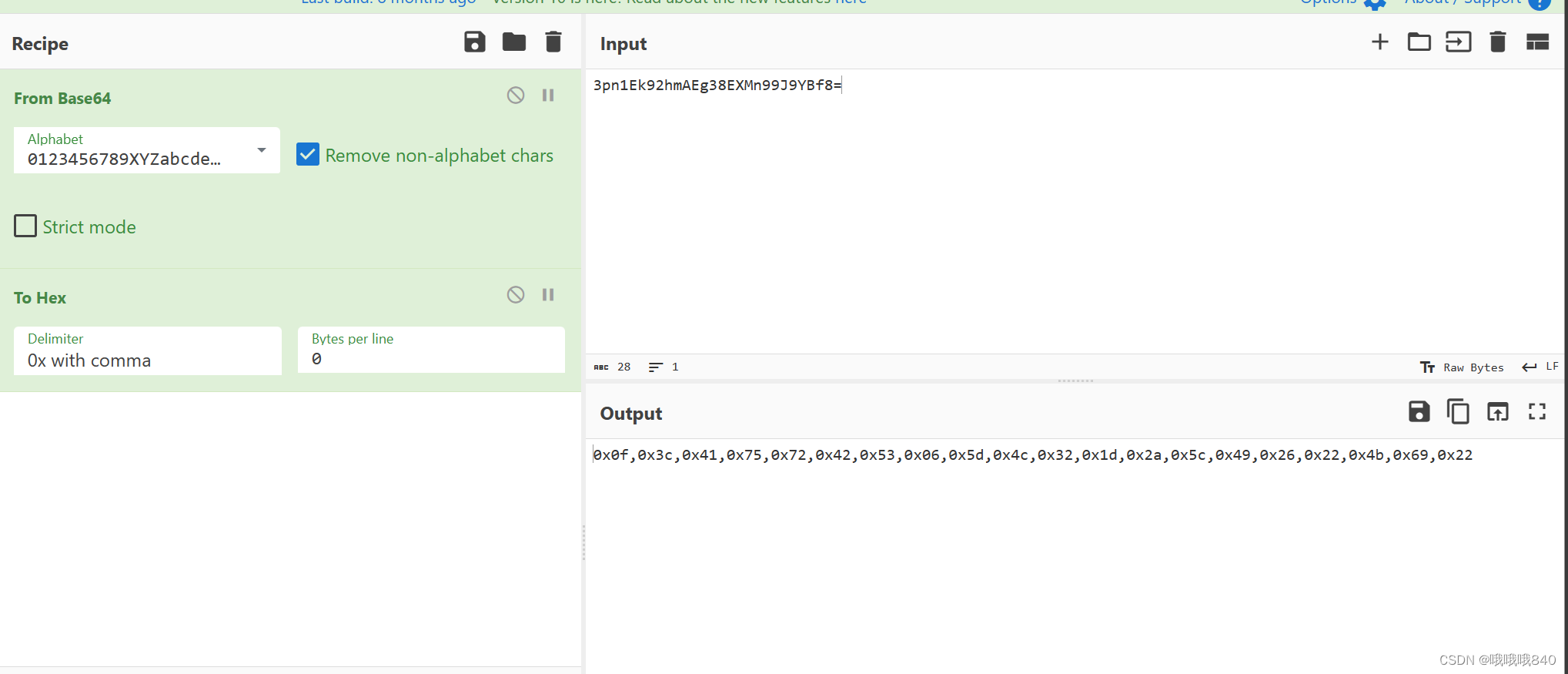
获得的结果:
0x0f,0x3c,0x41,0x75,0x72,
0x42,0x53,0x06,0x5d,0x4c,
0x32,0x1d,0x2a,0x5c,0x49,
0x26,0x22,0x4b,0x69,0x22如果不嫌麻烦,可以自行创建一个脚本进行解码操作,不过进行的步骤有点复杂,我之后会来开一期进行讲解
将上述的地址的字符进行输出,代码如下:
#include <stdio.h>
#include <string.h>
int main()
{
char a[] = {0x0f, 0x3c, 0x41, 0x75, 0x72, 0x42, 0x53, 0x06, 0x5d, 0x4c, 0x32, 0x1d, 0x2a, 0x5c, 0x49, 0x26, 0x22, 0x4b, 0x69, 0x22};
for (int i = 0; i < sizeof(a)/sizeof(a[0]); i++) {
printf("%c", a[i]);
}
return 0;
}
输出结果如下:
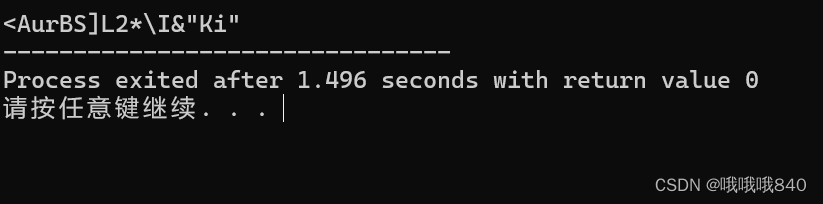
<AurBS]L2*\I&"Ki"
不过官方的wp的解答的情况是这样的
\x0f<AurBS\x06]L2\x1d*\\I&"Ki"
那就以官方的为准
同时,进行rc4的算法解密
import base64
import string
def rc4_init(s,key,length):
k = []
for i in range(128):
k.append('0')
for i in range(128):
s[i] = i
k[i] = key[i%length]
j = 0
for i in range(128):
j = (j+s[i]+ord(k[i]))%128
#print j
tmp = s[i]
s[i] = s[j]
s[j] = tmp
def rc4_crypt(s,data,length):
i = 0
j = 0
data1 = ''
for k in range(length):
i = (i+1)%128
j = (j+s[i])%128
tmp = s[i]
s[i] = s[j]
s[j] = tmp
t = (s[i]+s[j])%128
data1 += chr(data[k]^s[t])
return data1
str1 = "3pn1Ek92hmAEg38EXMn99J9YBf8="
string1 = "0123456789XYZabcdefghijklABCDEFGHIJKLMNOPQRSTUVWmnopqrstuvwxyz+/="
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
data = base64.b64decode(str1.translate(str.maketrans(string1,string2)))
print(data)
key = "Thi5_1S_key?"
s = []
for i in range(128):
s.append(0)
rc4_init(s,key,len(key))
data1 = rc4_crypt(s,data,len(data))
print(data1)
#
\x0f<AurBS\x06]L2\x1d*\\I&"Ki"'
flag{Simple_rEvErse}flag{Simple_rEvErse}















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









