






电商实战——Hadoop实现(2)
项目要求:
- 根据电商日志文件,分析:
统计页面浏览量(每行记录就是一次浏览)
统计各个省份的浏览量 (需要解析IP)
日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
实现统计各个省份的浏览量 (需要解析IP)步骤:
创建一个ContentUtils类
-
包含一个静态方法 getPageId,用于从给定的URL中提取页面ID。它使用了Apache Commons Lang库中的 StringUtils.isBlank 方法来检查字符串是否为空或空白,然后使用正则表达式来匹配并提取 topicId 参数的值。
import org.apache.commons.lang3.StringUtils;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ContentUtils {
public static String getPageId(String url){String pageId="-"; if (StringUtils.isBlank(url)){ return pageId; } Pattern pattern =Pattern.compile("topicId=[0-9]+"); Matcher matcher=pattern.matcher(url); if(matcher.find()){ pageId=matcher.group().split("topicId=")[1]; } return pageId; } }
创建一个IPParser类
- 继承自 IPSeeker(未在代码中给出,可能是一个用于解析IP地址的自定义类或库)。
包含一个单例模式的实现,用于创建和获取 IPParser 的实例。
analyseIp 方法用于解析IP地址,并返回一个包含国家、省份和城市的 RegionInfo 对象。它首先检查IP地址是否为空或无效,然后使用父类的方法 getCountry 来获取国家信息,并根据获取到的信息进行进一步的处理,以确定省份和城市。
部分代码:
public class IPParser extends IPSeeker {
// 地址 仅仅只是在idea环境中使用,部署在服务器上,
// 需要先将qqwry.dat放在集群的各个节点某个有读取权限目录,
// 然后在这里指定全路径
private static final String ipFilePath = "/home/hadoop/lib/qqwry.dat";
// 部署在服务器上
private static IPParser obj = new IPParser(ipFilePath);
protected IPParser(String ipFilePath) {
super(ipFilePath);
}
public static IPParser getInstance() {
return obj;
}
/**
* 解析ip地址
* @param ip
* @return
*/
public RegionInfo analyseIp(String ip) {
if (ip == null || "".equals(ip.trim())) {
return null;
}
RegionInfo info = new RegionInfo();
try {
String country = super.getCountry(ip);
if ("局域网".equals(country) || country == null || country.isEmpty() || country.trim().startsWith("CZ88")) {
// 设置默认值
info.setCountry("中国");
info.setProvince("上海市");
} else {
int length = country.length();
int index = country.indexOf('省');
if (index > 0) { // 表示是国内的某个省
info.setCountry("中国");
info.setProvince(country.substring(0, Math.min(index + 1, length)));
int index2 = country.indexOf('市', index);
if (index2 > 0) {
// 设置市
info.setCity(country.substring(index + 1, Math.min(index2 + 1, length)));
}
} else {
String flag = country.substring(0, 2);
switch (flag) {
case "内蒙":
info.setCountry("中国");
info.setProvince("内蒙古自治区");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
// TODO:针对其他旗或者盟没有进行处理
}
break;
case "广西":
case "西藏":
case "宁夏":
case "新疆":
info.setCountry("中国");
info.setProvince(flag);
country = country.substring(2);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
break;
case "上海":
case "北京":
case "重庆":
case "天津":
info.setCountry("中国");
info.setProvince(flag + "市");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('区');
if (index > 0) {
// 设置市
char ch = country.charAt(index - 1);
if (ch != '小' || ch != '校') {
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
if ("unknown".equals(info.getCity())) {
// 现在city还没有设置,考虑县
index = country.indexOf('县');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
}
break;
case "香港":
case "澳门":
info.setCountry("中国");
info.setProvince(flag + "特别行政区");
break;
default:
info.setCountry(country); // 针对其他国外的ip
}
}
}
} catch (Exception e) {
// nothing
}
return info;
}
**
* ip地址对应的info类
*
*/
public static class RegionInfo {
private String country ;
private String province ;
private String city ;
public String getCountry() {
return country;
}
创建一个IPParser类
- 这个类用于解析IP地址,并将IP地址映射到具体的国家和地区信息。
- 它使用内存映射文件和随机文件访问来提高读取IP地址数据库的效率。
- 包含单例模式,确保全局只有一个IPSeeker实例。
- 提供了多种方法来获取IP地址的国家、地区信息,以及IP范围记录。
- 部分代码如下:
public class IPSeeker {
public static final String ERROR_RESULT = “错误的IP数据库文件”;
// 一些固定常量,比如记录长度等等
private static final int IP_RECORD_LENGTH = 7;
private static final byte AREA_FOLLOWED = 0x01;
private static final byte NO_AREA = 0x2;
// 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找
private Hashtable ipCache;
// 随机文件访问类
private RandomAccessFile ipFile;
// 内存映射文件
private MappedByteBuffer mbb;
// 单一模式实例
private static IPSeeker instance = null;
// 起始地区的开始和结束的绝对偏移
private long ipBegin, ipEnd;
// 为提高效率而采用的临时变量
private IPLocation loc;
private byte[] buf;
private byte[] b4;
private byte[] b3;
/** */
/**
* 私有构造函数
*/
protected IPSeeker(String ipFilePath) {
ipCache = new Hashtable();
loc = new IPLocation();
buf = new byte[100];
b4 = new byte[4];
b3 = new byte[3];
try {
ipFile = new RandomAccessFile(ipFilePath, "r");
} catch (FileNotFoundException e) {
System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用");
ipFile = null;
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
public List getIPEntries(String s) {
List ret = new ArrayList();
try {
// 映射IP信息文件到内存中
if (mbb == null) {
FileChannel fc = ipFile.getChannel();
mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length());
mbb.order(ByteOrder.LITTLE_ENDIAN);
}
int endOffset = (int) ipEnd;
for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
int temp = readInt3(offset);
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
return ret;
}
private int readInt3(int offset) {
mbb.position(offset);
return mbb.getInt() & 0x00FFFFFF;
}
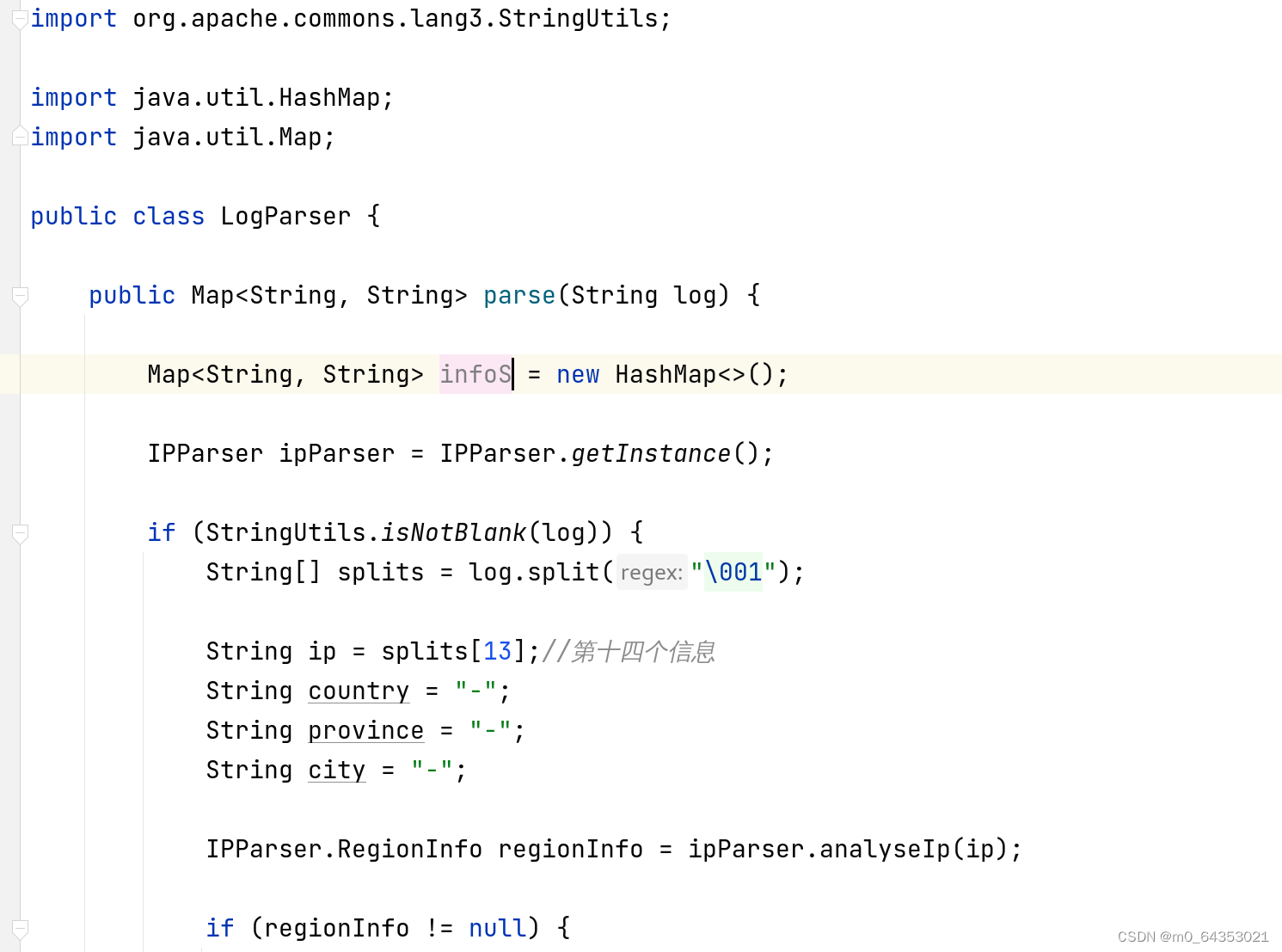
创建一个LogParser类
- 用于解析日志文件中的每条记录,提取IP地址、URL和时间等信息。
使用IPParser来解析IP地址对应的国家、省份和城市信息。
将解析结果存储在Map中返回。 - 部分代码如下:
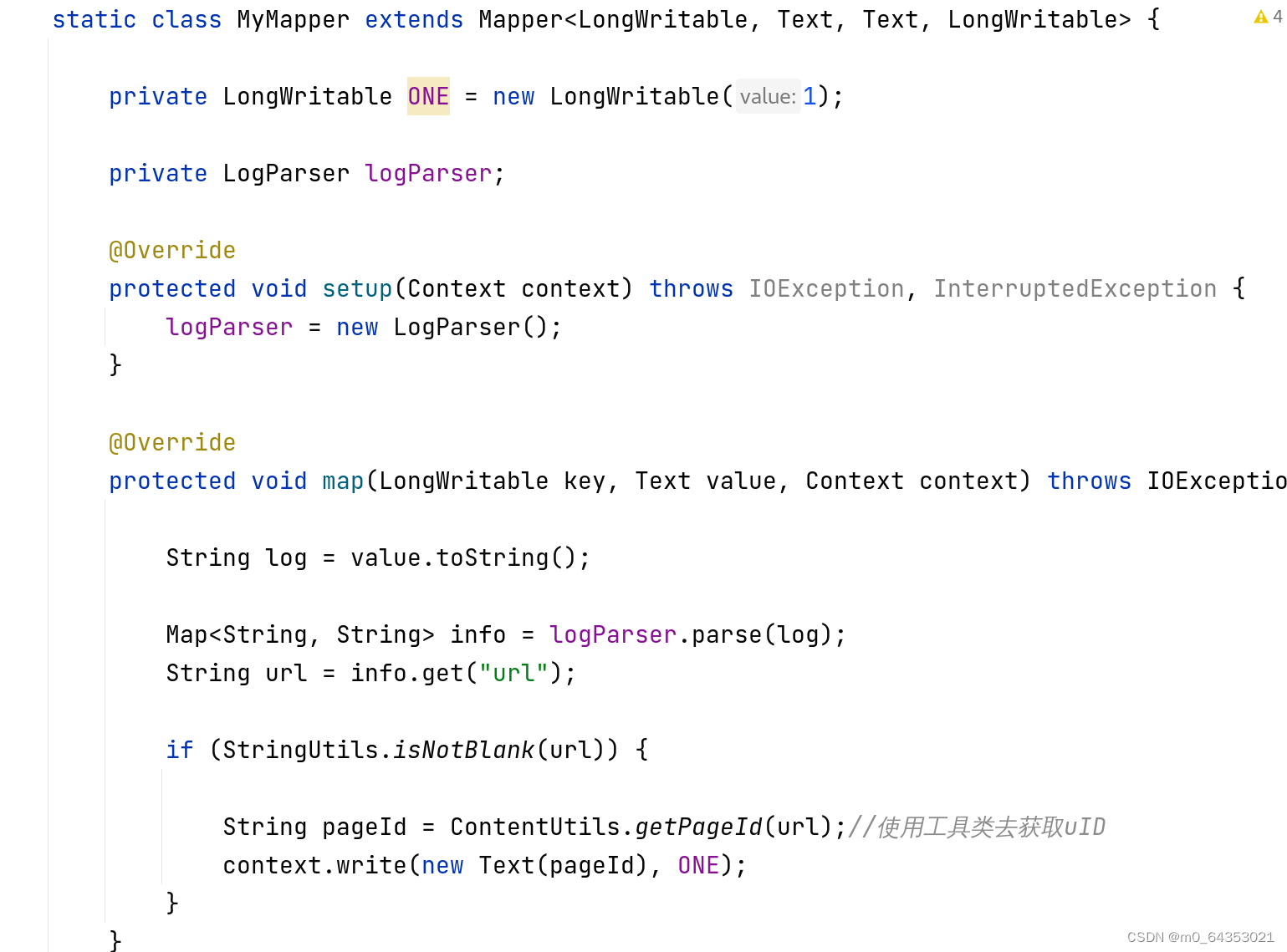
创建一个PageStatApp类
- 这个应用程序的目的是统计不同页面的浏览量。
它使用自定义的MyMapper类来处理日志数据,从每条日志中提取URL,然后使用ContentUtils.getPageId方法来获取页面ID。
每个页面ID作为MapReduce的键,对应的值是固定值1。
MyReducer类负责接收所有具有相同页面ID的键值对,并对它们进行汇总,输出每个页面的浏览量。 - 部分代码如下:

创建一个ProvinceStatApp类
- 这个应用程序的目的是统计不同省份的浏览量。
- 类似于PageStatApp,它使用自定义的MyMapper类来处理日志数据,但是这次它提取的是IP地址,并使用IPParser的analyseIp方法来解析IP地址到省份信息。
如果IP地址能够成功解析到省份,省份名称作为MapReduce的键,对应的值同样是固定值1;如果无法解析,则使用"-"作为键。 - MyReducer类的工作方式与PageStatApp中的相同,对每个省份的浏览量进行汇总。
- 部分代码如下:



















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









