







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、llamindex给的agent工作流程
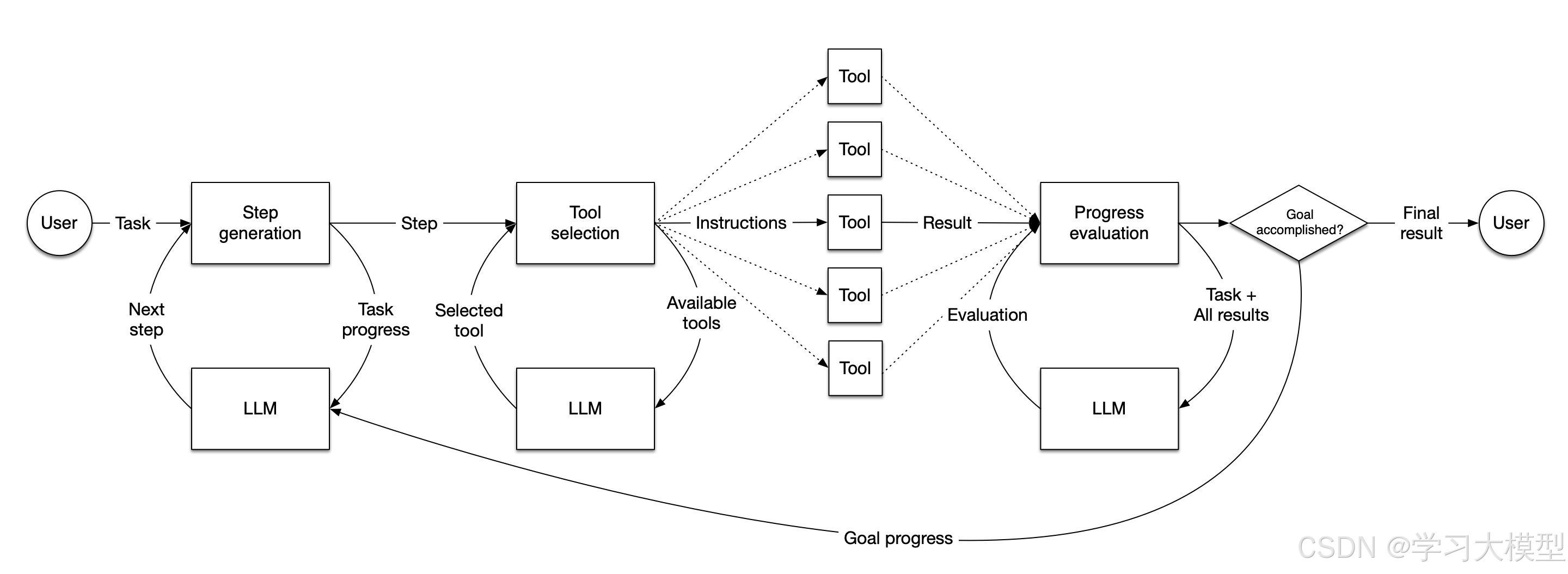
二、workflow
1.导入本地大模型
代码如下(示例):导入的千问的0.5b大模型
之前也有尝试用vllm接口,然后用llama-index的openailike接口掉,但是做结构化输出的函数一直出错,然后就换本地调用了
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core import Settings
llm=HuggingFaceLLM(
model_name="LLM_model/Qwen2.5-0.5B-Instruct",
tokenizer_name="LLM_model/Qwen2.5-0.5B-Instruct",
context_window=30000,
max_new_tokens=2000,
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
device_map="auto")
2.定义事件
一个agent的工作流应该是这样:
- 处理最新的传入用户消息,包括添加到内存和准备聊天历史记录
- 使用聊天历史记录和工具构建 ReAct 提示
- 使用 react 提示符调用 llm,并解析函数/工具调用
- 如果没有工具调用,我们可以返回
- 如果有工具调用,我们需要执行它们,然后使用最新的工具调用循环返回以获得新的 ReAct 提示
所以应该定义这些事件
1.用于处理新消息和准备聊天历史记录的事件
2.使用 react 提示符提示 LLM 的事件
3.触发工具调用的事件(如果有)
4.用于处理工具调用结果的事件(如果有)
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import ToolSelection, ToolOutput
from llama_index.core.workflow import Event
class PrepEvent(Event):
pass
class InputEvent(Event):
input: list[ChatMessage]
class ToolCallEvent(Event):
tool_calls: list[ToolSelection]
class FunctionOutputEvent(Event):
output: ToolOutput
3.定义工作流
定义了上面的agent工作步骤的函数
from typing import Any, List
from llama_index.core.agent.react import ReActChatFormatter, ReActOutputParser
from llama_index.core.agent.react.types import (
ActionReasoningStep,
ObservationReasoningStep,
)
from llama_index.core.llms.llm import LLM
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.tools.types import BaseTool
from llama_index.core.workflow import (
Context,
Workflow,
StartEvent,
StopEvent,
step,
)
from llama_index.llms.openai import OpenAI
class ReActAgent(Workflow):
def __init__(
self,*args: Any,
llm: LLM | None = None,
tools: list[BaseTool] | None = None,#导入的工具列表
extra_context: str | None = None,
**kwargs: Any,
) -> None:
super().__init__(*args, **kwargs)
self.tools = tools or []
self.llm = llm or OpenAI()
self.memory = ChatMemoryBuffer.from_defaults(llm=llm)
#from_defaults是这个类的方法,相当于读取llm参数,然后返回一个处理历史消息的类
self.formatter = ReActChatFormatter(context=extra_context or "")
#将工具描述、聊天历史和当前的推理步骤格式化为一组 ChatMessage 对象
self.output_parser = ReActOutputParser()
# 判断模型返回是否符合格式,如果是的,则利用正则表达式提取action,Thought等信息
self.sources = []
@step
async def new_user_msg(self, ctx: Context, ev: StartEvent) -> PrepEvent:
# 将用户消息添加到内存中,并清除全局上下文以跟踪新的推理字符串。
self.sources = []
# get user input
user_input = ev.input
user_msg = ChatMessage(role="user", content=user_input)
self.memory.put(user_msg)#提取键,加进去
# clear current reasoning,设置上下文变量,这个变量可以在下面直接掉
await ctx.set("current_reasoning", [])
return PrepEvent()
@step
async def prepare_chat_history(
self, ctx: Context, ev: PrepEvent
) -> InputEvent:
#使用聊天记录、工具和当前推理(如果有)准备 react 提示
# get chat history
chat_history = self.memory.get()#根据最大token限制,减少历史消息的数量
current_reasoning = await ctx.get("current_reasoning", default=[])
#这个事件还有可能再次发生,所以这里会调current_reasoning然后也放进提示词里
llm_input = self.formatter.format(
self.tools, chat_history, current_reasoning=current_reasoning
)
return InputEvent(input=llm_input)
@step
async def handle_llm_input(
self, ctx: Context, ev: InputEvent
) -> ToolCallEvent | StopEvent:
# 根据大模型的回复,判断是否结束推理,或者需要调用工具
chat_history = ev.input
response = await self.llm.achat(chat_history)
try:
reasoning_step = self.output_parser.parse(response.message.content)
#参数解析判断当前步骤是否结束
(await ctx.get("current_reasoning", default=[])).append(
reasoning_step
)#将推理步骤添加到当前推理中
if reasoning_step.is_done:
self.memory.put(
ChatMessage(
role="assistant", content=reasoning_step.response
)
)
return StopEvent(
result={
"response": reasoning_step.response,
"sources": [*self.sources],
"reasoning": await ctx.get(
"current_reasoning", default=[]
),
}
)
#如果是工具,则获取参数,并返回工具调用事件
elif isinstance(reasoning_step, ActionReasoningStep):
tool_name = reasoning_step.action
tool_args = reasoning_step.action_input
return ToolCallEvent(
tool_calls=[
ToolSelection(
tool_id="fake",
tool_name=tool_name,
tool_kwargs=tool_args,
)
]
)
#工具参数等错误时就报错,这个用装饰器设置参数整个步骤多尝试几次来减缓
except Exception as e:
(await ctx.get("current_reasoning", default=[])).append(
ObservationReasoningStep(
observation=f"There was an error in parsing my reasoning: {e}"
)
)
# if no tool calls or final response, iterate again
return PrepEvent()
@step
async def handle_tool_calls(
self, ctx: Context, ev: ToolCallEvent
) -> PrepEvent:
# 进行工具调用
tool_calls = ev.tool_calls
tools_by_name = {tool.metadata.get_name(): tool for tool in self.tools}
#如果没有工具说明模型输出有问题
for tool_call in tool_calls:
tool = tools_by_name.get(tool_call.tool_name)
if not tool:
(await ctx.get("current_reasoning", default=[])).append(
ObservationReasoningStep(
observation=f"Tool {tool_call.tool_name} does not exist"
)
)
continue
try:
#将参数输入函数
tool_output = tool(**tool_call.tool_kwargs)
self.sources.append(tool_output)
(await ctx.get("current_reasoning", default=[])).append(
ObservationReasoningStep(observation=tool_output.content)
)
except Exception as e:
(await ctx.get("current_reasoning", default=[])).append(
ObservationReasoningStep(
observation=f"Error calling tool {tool.metadata.get_name()}: {e}"
)
)
# 返回准备数据事件,那里判断是否结束调用
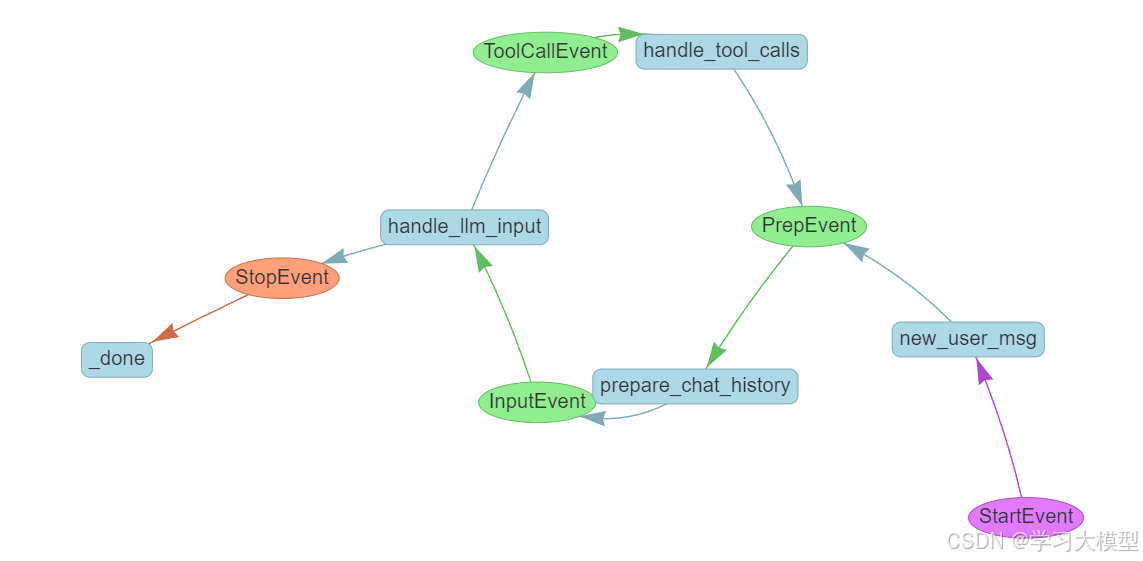
return PrepEvent()4.工作流可视化
from llama_index.utils.workflow import draw_all_possible_flows
draw_all_possible_flows(
ReActAgent, filename="text_to_sql_table_retrieval.html"
)
5.输入工具,输出结果
用简单的加和×,然后进行输入
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
def add(x: int, y: int) -> int:
"""Useful function to add two numbers."""
return x + y
def multiply(x: int, y: int) -> int:
"""Useful function to multiply two numbers."""
return x * y
tools = [
FunctionTool.from_defaults(add),
FunctionTool.from_defaults(multiply),
]
agent = ReActAgent(
llm=llm, tools=tools, timeout=120
)
ret = await agent.run(input="1+3+68*78")
ret["response"]这里用verbose可以可视化看到,先后进行了几个步骤,中间调用了工具,但是这里的verbose看不到,用官方的ReActAgent类会输出细节,类在这里
from llama_index.core.agent import ReActAgent

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









