







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
Polars 可以通过 Python 包管理器 pip 进行安装。打开命令行界面并运行以下命令:
pip install polars
使用 Polars 中加载数据集
Polars 提供了从各种来源加载数据的便捷方法,包括 CSV 文件、Parquet 文件和 Pandas DataFrames。读取 CSV 或 parquet 文件的方法与 Pandas 库相同。
read csv file
import polars as pl
data = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
check the head
data.head()
输出:
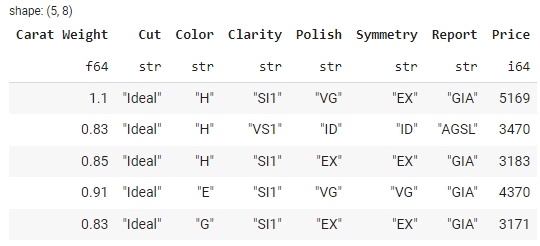
的类型是:polars.DataFrame
type(data)
polars.dataframe.frame.DataFrame
Polars 的常见数据操作函数
Polars 提供了一套全面的数据操作功能,让您可以轻松选择、过滤、排序、转换和清理数据。让我们来看一些常见的数据操作任务,以及如何使用 Polars 完成这些任务:
1. 选择和筛选数据
若要从 DataFrame 中选择特定列,可以使用 select() 该方法。下面是一个示例:
import polars as pl
Load diamond data from a CSV file
df = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
Select specific columns: carat, cut, and price
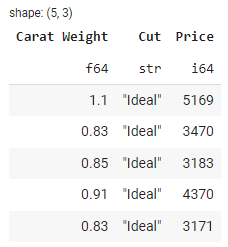
selected_df = df.select([‘Carat Weight’, ‘Cut’, ‘Price’])
show selected_df head
selected_df.head()
输出:
可以使用 filter()方法根据某些条件筛选行。例如,要筛选克拉大于 1.0 的行,您可以执行以下操作:
import polars as pl
Load diamond data from a CSV file
df = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
filter the df with condition
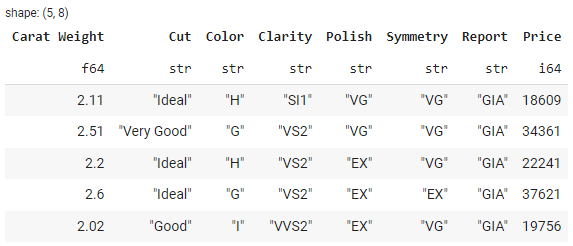
filtered_df = df.filter(pl.col(‘Carat Weight’) > 2.0)
show filtered_df head
filtered_df.head()
输出:
2. 对数据进行排序和排序
Polars 提供了基于一列或多列对 DataFrame 进行排序的方法:sort()。下面是一个示例:
import polars as pl
Load diamond data from a CSV file
df = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
sort the df by price
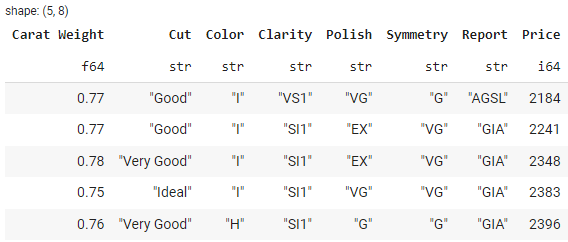
sorted_df = df.sort(by=‘Price’)
show sorted_df head
sorted_df.head()
输出:
3. 处理缺失值
Polars 提供了处理缺失值的便捷方法。该方法允许您删除包含任何缺失值的行:drop_nulls()
import polars as pl
Load diamond data from a CSV file
df = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
drop missing values
cleaned_df = df.drop_nulls()
show cleaned_df head
cleaned_df.head()
输出:
或者,可以使用 fill_nulls()方法将缺失值替换为指定的默认值或填充方法。
4. 根据特定列对数据进行分组
若要根据特定列对数据进行分组,可以使用 groupby()方法。以下示例按列 Cut对数据进行分组,并计算每个组 Price的平均值:
import polars as pl
Load diamond data from a CSV file
df = pl.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
group by cut and calc mean of price
grouped_df = df.groupby(by=‘Cut’).agg(pl.col(‘Price’).mean())
show grouped_df head
grouped_df.head()
输出:
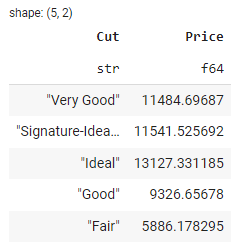
在上面的输出中,您可以按 Cut 查看钻石的平均价格。
5. 连接和组合 DataFrame
Polars 为连接和组合数据帧提供了灵活的选项,允许您合并和连接来自不同来源的数据。若要执行联接操作,可以使用 join()方法。以下示例演示了基于公共列的两个 DataFrame 之间的内部联接:
import polars as pl
Create the first DataFrame
df1 = pl.DataFrame({
‘id’: [1, 2, 3, 4],
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’]
})
Create the second DataFrame
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-jrWW93LA-1713568478969)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6229
6229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









