






在开始前,请确保您有一定的LLM基础😊
量化通过将浮点权重映射到有限整数空间(如 int8),降低模型存储和计算开销。本文以 GPT-2 为例,分析三种量化方法:absmax、zeropoint 和 LLM.int8()
叠甲:我对文章中提到的所有算法的数学解析只是片面的,深入研究会在不久的将来发布(也许吧😔),敬请期待😊(欢迎各位大佬指出错误😊)
1.absmax量化
1.1量化目标
将浮点张量 映射到整数空间
,满足:
,
其中 为线性或非线性映射函数,反量化后误差最小化:
,
1.2数学推导
- 缩放因子:
令张量 的最大绝对值为
,则缩放因子定义为:
选择 127 而非 128 是为了避免对称量化时溢出。例如,若 M=1M=1,则量化范围为 [−127,127][−127,127],总区间长度为 254,而非 255。
- 量化与反量化公式:
误差分析:
- 舍入误差:由 round 操作引入,服从均匀分布
- 截断误差:当
时,值被截断至边界,误差为:
总误差满足:
1.3代码实现
def absmax_quantize(X):
scale = 127 / torch.max(torch.abs(X)) # 计算缩放因子(防止溢出)
X_quant = (scale * X).round() # 缩放后取整得到量化值
X_dequant = X_quant / scale # 反量化恢复近似值
return X_quant.to(torch.int8), X_dequant 数学验证:若 =
, 则
。量化结果为
,反量化后为
,误差为
2.zeropoint量化
2.1数学推导
- 值域与缩放因子:
令 ,值域
缩放因子为:
(确保映射到8位无符号整数范围[0, 255])
- 零点偏移:
调整偏移使 映射到
:
- 量化公式:
- 反量化:
误差分析:
- 零点偏移误差:由 round 引入,误差为
- 量化总误差:
2.2代码实现
def zeropoint_quantize(X):
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range # 处理全零张量
scale = 255 / x_range # 缩放因子覆盖整个int8范围
zeropoint = (-scale * torch.min(X) - 128).round() # 零点偏移计算
X_quant = torch.clip((X * scale + zeropoint).round(), -128, 127) # 量化+截断
X_dequant = (X_quant - zeropoint) / scale # 反量化
return X_quant.to(torch.int8), X_dequant
数学验证:若 ,则
,
。量化结果为
,反量化后为
,误差为
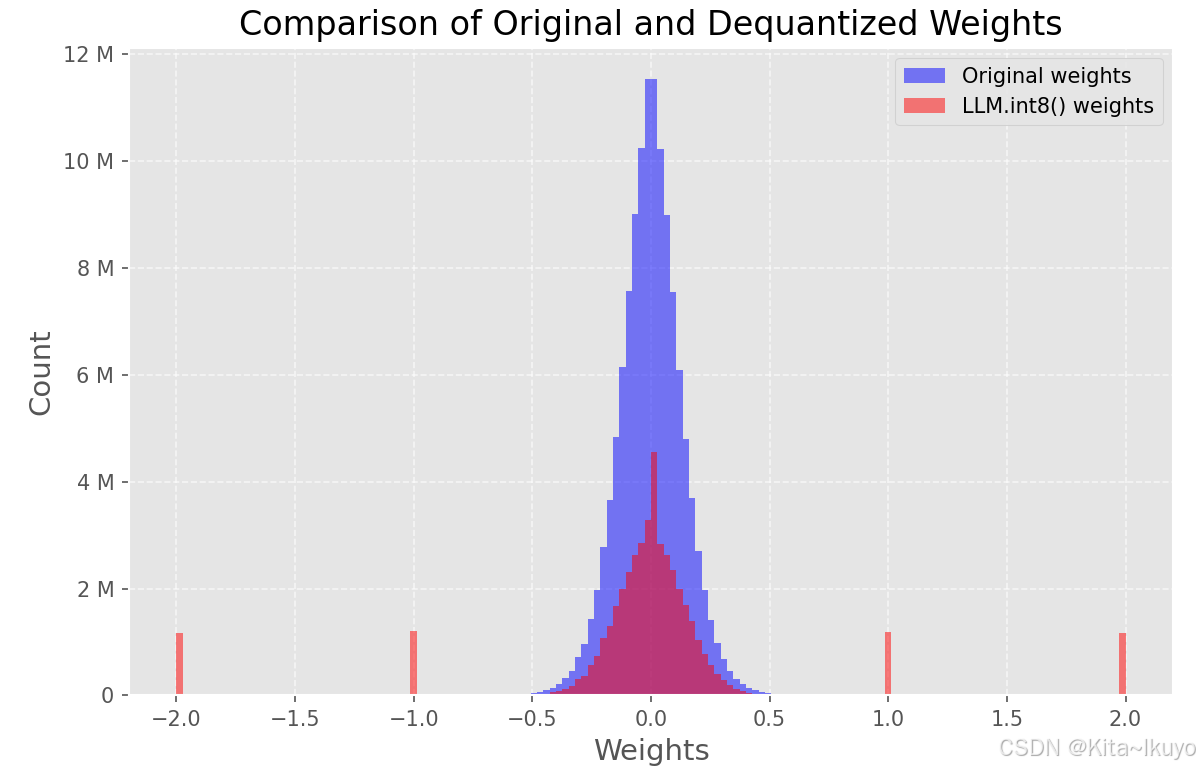
3.LLM.int8()
3.1混合精度量化原理
-
离群值分离:
对权重矩阵,检测离群值
,
通常取 ,保留离群值为 FP16
- 子矩阵量化:
对非离群值部分 使用向量量化:
其中每列独立计算 和
3.2动态反量化
在矩阵乘法 中:
通过分离计算,减少离群值对整体精度的影响
-
误差控制:离群值的 FP16 保留使大权重误差降低
倍。
-
计算效率:仅对非离群值量化,平衡速度与精度。
4.实验结果分析
4.1权重分布分析
- KL 散度质量分布差异:
计算原始权重与量化权重的 KL 散度:
absmax 量化导致高 KL 散度(尾部截断)
zeropoint 量化 KL 散度较低,保留分布形状
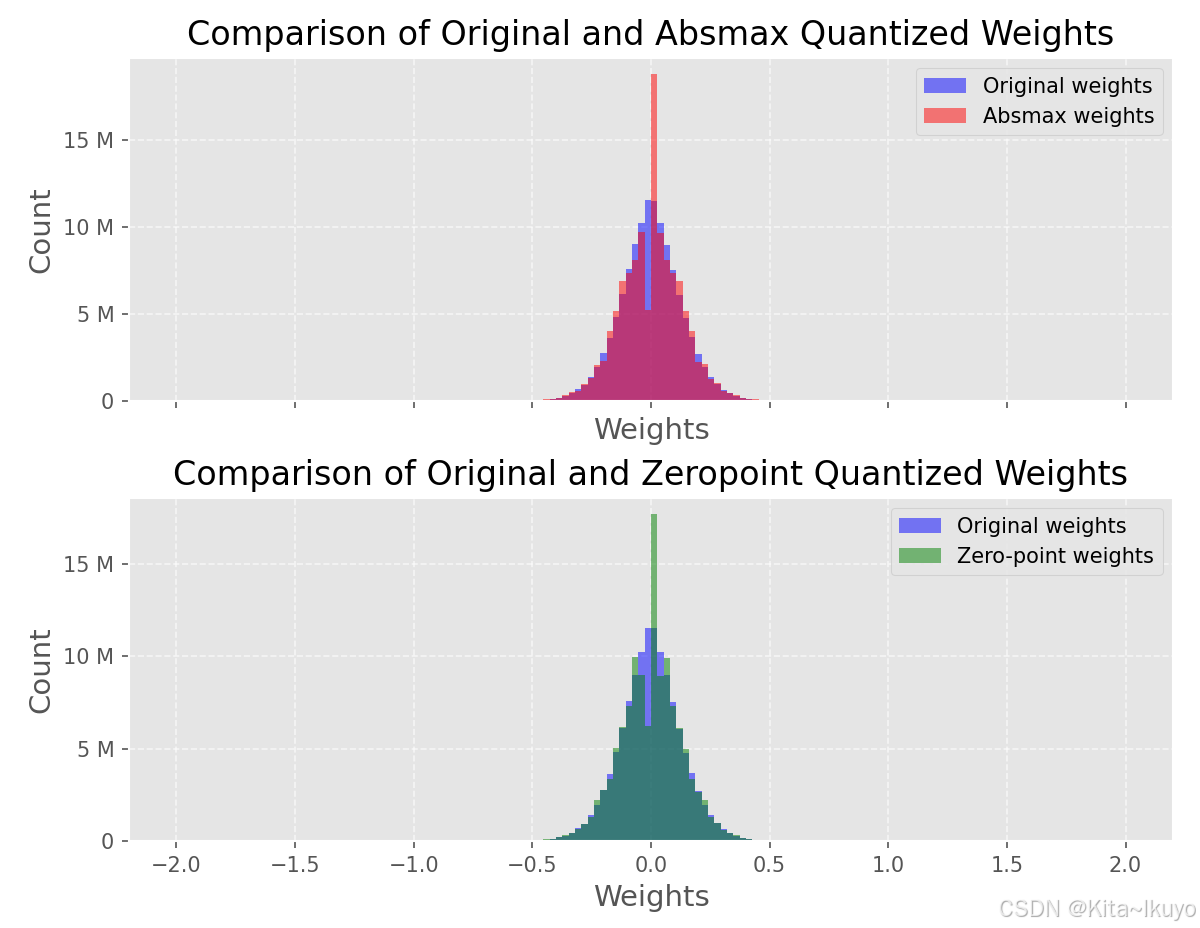
4.2模型困惑度
困惑度 与量化误差呈正相关
# 计算模型困惑度
def calculate_perplexity(model, text):
encodings = tokenizer(text, return_tensors='pt').to(device)
input_ids = encodings.input_ids
target_ids = input_ids.clone()
with torch.no_grad(): #禁用梯度计算,减少内存占用
outputs = model(input_ids, labels=target_ids)
# 计算负对数似然损失
neg_log_likelihood = outputs.loss
# 计算困惑度(困惑度是负对数似然损失的指数值)
ppl = torch.exp(neg_log_likelihood)
return ppl最后
Model size: 510,342,192 bytes
Original weights:
tensor([[-0.4738, -0.2614, -0.0978, ..., 0.0513, -0.0584, 0.0250],
[ 0.0874, 0.1473, 0.2387, ..., -0.0525, -0.0113, -0.0156],
[ 0.0039, 0.0695, 0.3668, ..., 0.1143, 0.0363, -0.0318],
...,
[-0.2592, -0.0164, 0.1991, ..., 0.0095, -0.0516, 0.0319],
[ 0.1517, 0.2170, 0.1043, ..., 0.0293, -0.0429, -0.0475],
[-0.4100, -0.1924, -0.2400, ..., -0.0046, 0.0070, 0.0198]],
device='cuda:0')
Absmax quantized weights:
tensor([[-21, -12, -4, ..., 2, -3, 1],
[ 4, 7, 11, ..., -2, -1, -1],
[ 0, 3, 16, ..., 5, 2, -1],
...,
[-12, -1, 9, ..., 0, -2, 1],
[ 7, 10, 5, ..., 1, -2, -2],
[-18, -9, -11, ..., 0, 0, 1]], device='cuda:0',
dtype=torch.int8)
Zero-point quantized weights:
tensor([[-20, -11, -3, ..., 3, -2, 2],
[ 5, 8, 12, ..., -1, 0, 0],
[ 1, 4, 18, ..., 6, 3, 0],
...,
[-11, 0, 10, ..., 1, -1, 2],
[ 8, 11, 6, ..., 2, -1, -1],
[-18, -8, -10, ..., 1, 1, 2]], device='cuda:0',
dtype=torch.int8)
--------------------------------------------------
Original model:
I want to play. Not because I love football. I want to play with my wife. Not because I know how much I like to watch
football. I like to be around people that don't seem like me, like the players in college,
--------------------------------------------------
Absmax model:
I want to play a lot of games here on the Nintendo Switch, so we wanted one for us at Nintendo," said Tom Hyuk. "And a bunch of games at GameStop where we were really close to selling it. Because we wanted to
--------------------------------------------------
Zeropoint model:
I want to play as the No. 1 running back in Buffalo on Thursday night vs. the Green Beret. Will you like the new style of offensive philosophy? No. Yes. That will be interesting to know. Will you like the way the
--------------------------------------------------
LLM.int8() model:
I want to play the game for him, but I need to get to know him before he gets any older," he said. "It's been a long time."
Carr had a different take on it.
"I think
--------------------------------------------------
Original perplexity: 10.59
Absmax perplexity: 20.95
Zeropoint perplexity: 23.95
Perplexity (LLM.int8()): 8.90
==== model compressibility ====
Original model 510,342,192 bytes
8-bit Quantized Model size: 176,527,896 bytes
Compression Rate:65.41%完整代码实现请见我的github仓库:naidezhujimo/Three-methods-of-quantification


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









