







今天有一个随堂小测,大家要是不会可以私信我哦。
接下来我们回顾一下我讲的15个知识点吧!
1.结构体
结构体是不需要头文件的,可以直接声明,先看个例子:
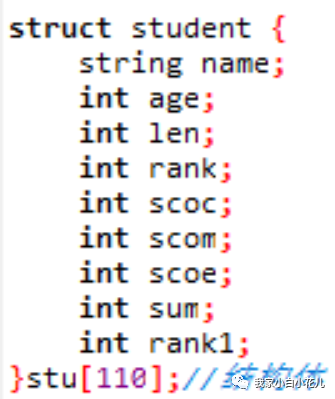
这是一个学生结构体,struct是一个关键字,她的意思就是要声明结构体了,在大括号里面是一堆变量,也就是一个结构体类型里包含的数据,stu[110]是说我创建了一个名为stu类型为student结构体类型长110的结构体数组。
注:补充一点就是:变量在结构体不能初始化,像以下的代码就是错误的!
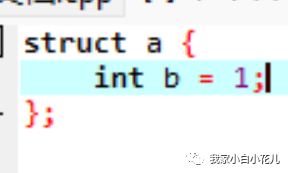
重要的事情说三遍:
变量在结构体不能初始化!!!
变量在结构体不能初始化!!!
变量在结构体不能初始化!!!
2.const
先看一下样例:

这里的const代表这个值不能改变,int是他的类型,maxn为名字,初始值:1005,const修饰符的变量必须初始化,否则会报以下错误

3.set
插入元素
C++ 中用insert()函数向集合中插入一个新的元素。注意如果集合中已经存在了某个元素,再次插入不会产生任何效果,集合中是不会出现重复元素的。
所以set就有一个很重要的应用了,它可以帮助我们完成去重。
删除元素
C++ 中通过erase()函数删除集合中的一个元素,如果集合中不存在这个元素,不进行任何操作。
获取元素个数
如果我们想知道元素个数,需要使用size函数,与看字符串长度,看vector中的元素数量一样。
如果我们有一个set,叫s,那么只需要调用s.size()就可以看到s中的元素个数了。
清空
C++ 中调用clear函数就可清空set,同时会清空set占用的内存。
如果我们有一个set,叫s,那么只需要调用s.clear()就可以清空这个set了。
遍历 set
C++ 通过迭代器可以访问集合中的每个元素,迭代器就好像一根手指指向set中的某个元素。通过操作这个手指,我们可以改变它指向的元素。通过* (解引用运算符,不是乘号的意思) 操作可以获取迭代器指向的元素。通过++操作让迭代器指向下一个元素,同理--操作让迭代器指向上一个元素。
迭代器的写法比较固定,set<T>::iterator it就定义了一个指向set<T>这种集合的迭代器it,T是任意的数据类型。其中::iterator是固定的写法。
比如你想看set<int>内部的元素,那声明迭代器的时候就是set<int>::iterator it
begin函数返回容器中起始元素的迭代器,end函数返回容器的尾后迭代器。

注:
集合内的不同的元素类型,需要使用不同的迭代器,例:
set <int> :: iterator it1; set <double> :: iterator it2;
*it 是获取迭代器(图中的手指位置)的具体元素数据。
4.map
加入头文件
在 C++ 中map的实现在一个<map>头文件中,在代码开头引入这个头文件,并且加上一句using namespace std。
声明 map
现在我们来构造一个映射,也就是声明一个map。
在 C++ 中,我们构造一个map的语句为:map<T1, T2> m;。这样我们定义了一个名为m的从T1类型到T2类型的映射。初始的时候m是空映射。比如map<string, int> m构建了一个字符串到整数的映射,这样我们可以把一个字符串和一个整数关联起来。
比如这里,我们就可以利用m这个map,把一个人的名字对应上他所在的班级了。
访问 map 中的一位
在 C++ 中访问映射和数组一样,直接用[]就能访问。比如dict["Tom"]就可以获取"Tom"的班级了。
所以我们也可以把map看成一种特殊的数组,下标可以不为整数的数组。
并且我们可以之后再给映射赋予新的值,比如dict["Tom"] = 3,这样为我们提供了一种方便的插入手段。
实际上,我们也常常通过下标访问的方式来插入映射。
判断关键字是否存在
不过如果用刚才的方法访问map会有一个神奇的事情。
如果我在访问dict["Tom"]的时候,map内部还没有"Tom"这个下标,也就是还没有对"Tom"做过映射的话,系统将会自动为"Tom"生成一个映射,其value为对应类型的默认值(比如int的默认值是 00,string的默认值是空字符串)。也就是它自动会完成dict[Tom] = "";这句话。
但是有些时候,我们不希望系统这么做,这时候我们需要检测"Tom"这个key是不是存在,如果存在再访问。这时可以借助count()函数进行判断。
如果这个key存在,返回
1,否则会返回0。
遍历 map
map的迭代器的定义和set差不多,map<T1, T2>::iterator it就定义了一个迭代器,其中T1、T2分别是key和value的类型。
C++ 通过迭代器可以访问集合中的每个元素。这里迭代器指向的元素是一个pair。
pair可以看作是一个有两个成员变量first和second的结构体,排序方法默认为先比较first,first小的算小,first一样就比较second,second小的算小。
struct pair { type first; type second; };
在map里每一个pair的first和second分别代表一个映射的key和value。
我们用->运算符来获取值,it->first和(*it).first的效果是一样的,就是获取迭代器it指向的pair里first成员的值
注意,在 C++ 中遍历map是按照关键字从小到大遍历的,这一点和set有些共性,并且关键字也不能直接修改。
所以如果map的key是结构体,就需要重载这个结构体的小于号。
map 使用方式的总结
map往往可以当作特殊的数组来使用,在数组开不下,或者数组下标不是整数的时候使用map就很方便,比如统计字符串的出现个数,统计int范围内的数的出现次数等等。
5.pair
基本操作
加入头文件
在 C++ 中 pair 的实现在一个<utility>头文件中,在代码开头引入这个头文件,并且加上一句using namespace std。
注:头文件里的内容现在和容器的名字不一样了,注意一下
声明 pair
现在我们来构造一个 pair,也就是声明一个 pair。
在 C++ 中,我们构造一个pair的语句为:pair<T1, T2> p;。这样我们定义了一个名为 p 的,第一关键字为 T1 类型,第二关键字为 T2 类型的 pair。
如果我们想要在构造 pair 同时,并给两个关键字赋值,那么我们可以这样写:pair <T1, T2> p(value1, value2);。这样我们在定义 pair 的同时获得第一个关键字的值为 value1,第二关键字的值为 value2。
生成新的 pair 对象
在 C++ 中,我们可以通过 make_pair 函数创建新的对象,创建的语句为:pair <T1, T2> p = make_pair(value1, value2)。
访问 pair 的关键字
pair 的底层实现是结构体,有两个成员变量:first,second。所以我们可以通过 变量名.first, 变量名.second访问。
6.auto
在声明时,编译器会根据赋值号右侧的表达式类型,推断出 it 变量的类型并声明它。这个保留字在任何声明变量的地方都可以使用,但需要注意的是,务必在声明变量的同时对它进行初始化,否则编译器将不知道变量实际应该被声明为何种类型。
注:
-
auto 类型也是可以进行引用的,例如:
int a = 10;
auto &b = a;
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错。例如下方代码是不合法的:
auto a = 1, b = 1.5;
auto 虽然可以自动识别类型,但是当它被定义时,类型就确定了,之后不会再改变类型了,例如下方的操作就是错误的:
set <int> st;
map <int, int> mp;
auto it = st.begin();
it = mp.begin(); // 一定要注意,这样是错误的
但是这样就是合法的:
set <int> s, t;
s.insert(1);
t.insert(2);
auto it = s.begin();
cout << *it << endl;
it = t.begin();
cout << *it << endl;
7.bitset
加入头文件
C++ 中bitset的实现在一个<bitset>头文件中,在代码开头引入这个头文件,并且同样加上一句using namespace std。
构造方法
直接构造一个bitset的语句为:bitset <16> vis;。这样我们定义了一个名为 vis的、储存长度为 16的 bitset。初始的时候 vis 的每一项均为 0。
这一步就相当于声明变量,声明了一个bitset,以后就可以用它了。
访问
可以通过 [] 访问元素(类似数组),注意最低位下标为 0,如下所示:
bitset <16> vis;
cout << vis[1] << endl;
修改
可以通过 set() 和 reset() 函数对 bitset 中某个元素进行修改。其中 set() 函数是将某个元素变为 1 或 0,reset() 函数是将某个元素变为 0。例如:
bitset <16> vis;
vis.set(); 没有参数时,是将 bitset 的每一位全部变为 1
vis.set(3); 只有一个参数时,是将对应下标位变为 1。这里处理后:
vis[3] = 1
vis.set(4,1) ;有两个参数时,是将第一个参数对应的下标位修改为第二个参数。这里处理后:vis[4] = 1
vis.reset(); 没有参数时,是将 bitset 的每一位全部变为 0
vis.reset(2);只有一个参数时,是将对应下标位变为 0。这里处理后: vis[2] = 0
思考
大家思考一下,除了 bitset 外,还有哪些数据结构可以实现标记呢?
其实 set 和 map 均可以实现。
-
set 实现标记:判断 x 是否在集合内,可以使用 count() 函数。
-
map 实现标记:判断 x 的第二关键字是否为 true。
8.unordered_map
C++ 中 unordered_map 的实现在一个 <unordered_map> 头文件中,在代码开头引入这个头文件,并且同样加上一句using namespace std。
在具体操作中 unordered_map 和 map 除了声明方式不同外,其他所有操作和 map 保持一致。

程序会输出: 4043
访问 unordred_map 中的一位
在 C++ 中访问映射和数组一样,直接用[]就能访问。比如dict["Tom"]就可以获取"Tom"的班级了。
所以我们也可以把unordred_map看成一种特殊的数组,下标可以不为整数的数组。
并且我们可以之后再给映射赋予新的值,比如dict["Tom"] = 3,这样为我们提供了一种方便的插入手段。
实际上,我们也常常通过下标访问的方式来插入映射。
判断关键字是否存在
不过如果用刚才的方法访问map会有一个神奇的事情。
如果我在访问dict["Tom"]的时候,map内部还没有"Tom"这个下标,也就是还没有对"Tom"做过映射的话,系统将会自动为"Tom"生成一个映射,其value为对应类型的默认值(比如int的默认值是 0,string的默认值是空字符串)。也就是它自动会完成dict[Tom] = "";这句话。
但是有些时候,我们不希望系统这么做,这时候我们需要检测"Tom"这个key是不是存在,如果存在再访问。这时可以借助count()函数进行判断。
如果存在这个值,返回true,否则false
遍历 unordred_map
map的迭代器的定义和set差不多,map<T1, T2>::iterator it就定义了一个迭代器,其中T1、T2分别是key和value的类型。
C++ 通过迭代器可以访问集合中的每个元素。这里迭代器指向的元素是一个pair。
pair可以看作是一个有两个成员变量first和second的结构体,排序方法默认为先比较first,first小的算小,first一样就比较second,second小的算小。
struct pair {
type first;
type second;
};
在unordred_map里每一个pair的first和second分别代表一个映射的key和value。
我们用->运算符来获取值,it->first和(*it).first的效果是一样的,就是获取迭代器it指向的pair里first成员的值
注意,在 C++ 中遍历map是按照关键字从小到大遍历的,这一点和set有些共性,并且关键字也不能直接修改。
所以如果unordred_map的key是结构体,就需要重载这个结构体的小于号。
unordred_map 使用方式的总结
unordred_map往往可以当作特殊的数组来使用,在数组开不下,或者数组下标不是整数的时候使用map就很方便,比如统计字符串的出现个数,统计int范围内的数的出现次数等等。
下面是我们学到的unordred_map的常用函数

9.自定义函数
先看看自定义代码怎么创建:

这里说的很详细就不说了
递归

你一定听过这个故事:
从前有座山, 山里有个庙, 庙里有个老和尚在讲故事,讲的什么故事呀?讲的是:从前有座山, 山里有个庙, 庙里有个老和尚在讲故事,讲的什么故事呀?...从前有座山, 山里有个庙, 庙里有个老和尚在讲故事,讲的什么故事呀?讲的是:故事 中讲 故事 ,这就产生了 递归。
在程序中,我们将故事用一个封装好的函数代替,在这个函数 内部再次 调用函数,就产生了 函数的递归调用
10.stable_sort
温故知新
在 C++ 中,我们借助 sort 函数,实现可以对 数组的所有元素 完成排序操作。但是 sort 排序为不稳定排序算法。
为了实现稳定排序,我们需要借助 结构体 和 cmp 函数 实现。
那么 C++ 里面有没有提供稳定的排序函数呢?
稳定排序
在 C++ 中,我们可以借助 stable_sort 函数实现 稳定 排序。stable_sort 函数与 sort 函数都在 algorithm 头文件下,并且用法完全一致。
而且它也是能够用cmp函数来实现降序以及实现结构体排序
![]()
11.插入排序
插入排序
插入排序是一种非常直观的排序算法,它的基本思想是将数组分为已排序的前半部分和待排序的后半部分,每次把待排序部分的第一个元素,插入到已排序部分的对应位置中,直到全部记录都插入到已排序部分中。
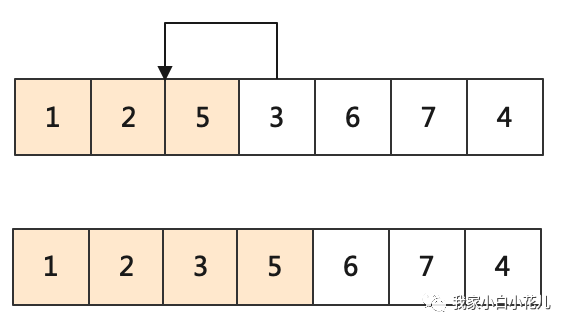
插入操作分为两个步骤:
在已排序的部分中查找插入的位置
插入时元素后移

上述代码中,内层循环是从大到小找第一个 a[i] ≥ a[j] ≥ a[i]的位置 j,然后把 a[i]放在j + 1这个位置。我们边寻找,边调整元素的位置,相当于提前了元素后移的操作。
显然,插入排序是一种稳定的排序方法。
12.冒泡排序介绍与实现代码
冒泡排序
冒泡排序的基本思想为:假如待排序数组的长度为
n,从前往后两两比较相邻元素的关键字,若 a[i - 1] > a[i],则交换它们,直到数组比较完成。每趟交换以后最后一个元素一定是最大的,不再参与下一趟交换。也就对 于第i 趟交换,只需要比较到a[n - i] 即可。直到一趟比较内没有进行交换,算法结束。
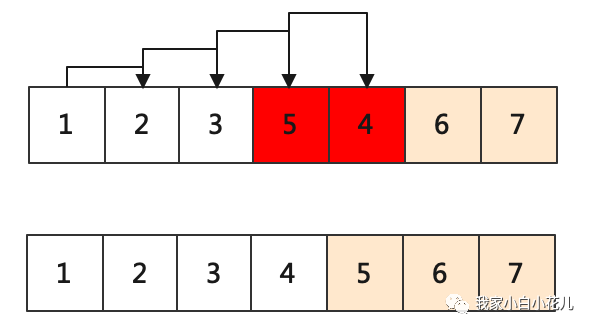
参考代码如下:

冒泡排序是一种稳定的排序算法。
13.选择排序介绍与实现代码
选择排序
选择排序的思想是,将数组分为已排序的前半部分和待排序的后半部分,每趟从待排序区域选取最小的元素,将其放到已排序区域的最后。因为每趟可以让待排序区域的元素数量减少一个,所以总共需要 n - 1 趟操作就可以将整个数组排序完成。
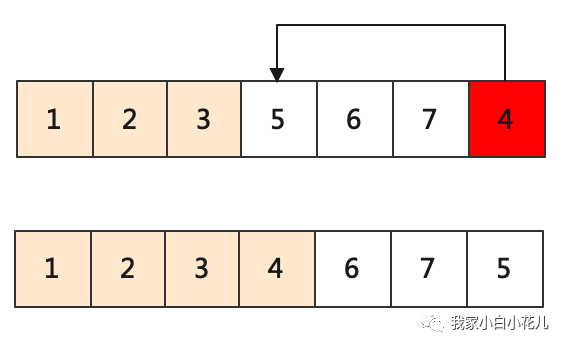
参考代码如下:

14.归并排序
归并排序的基本思想是分治,每次把待排序的区间分成两半,递归地处理。等到左右两部分都是有序后,再进行归并操作让整个数组有序。

参考代码如下:
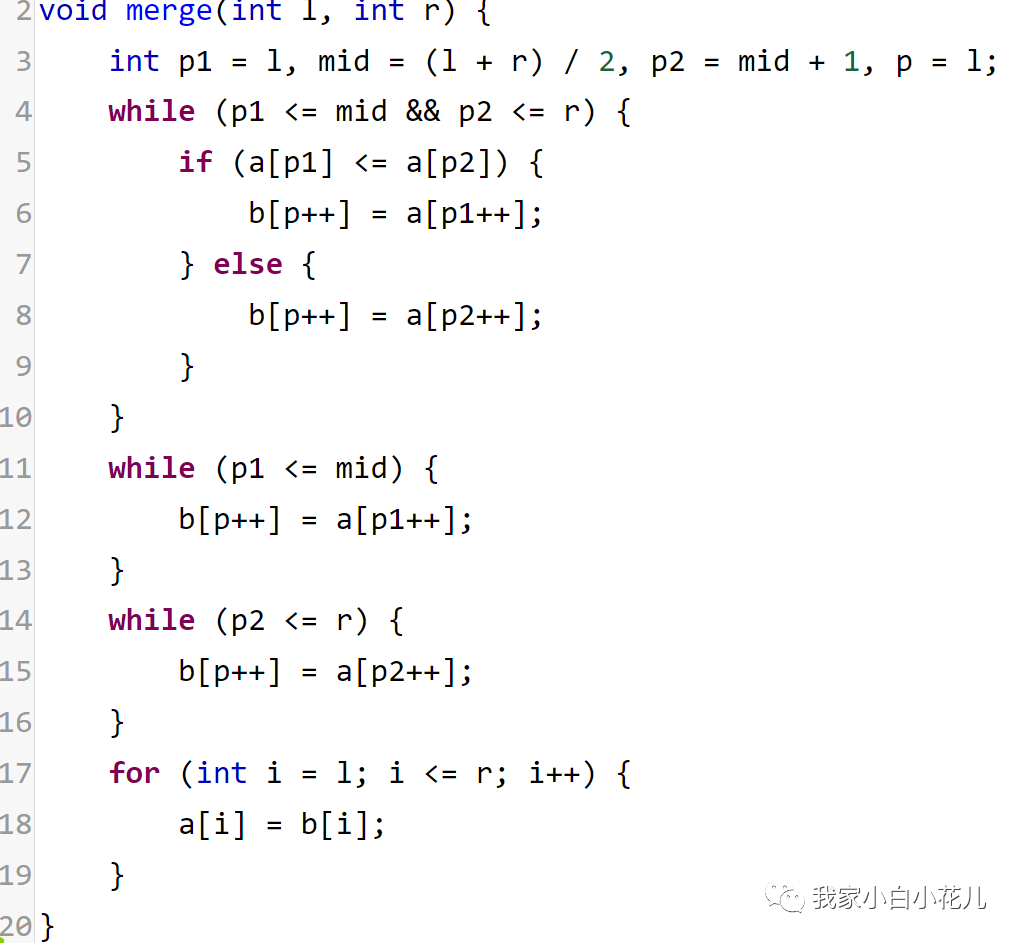

上面的merge_sort函数每次对[l, r]区间的元素进行归并排序。如果当前区间只有一个元素,就说明已经排序好了,直接返回。否则,把区间划分为[l, mid]和[mid + 1, r]两部分递归处理,其中mid = (l + r) / 2
执行归并操作时,先把两个有序的区间合并到一个新数组b中,最后再复制回原数组里。
15.快速排序(提高内容)
快速排序是目前应用最广泛的排序算法之一,它的基本思想与归并排序类似,也是基于分治的。每次从待排序区间选取一个元素(我们在后面的课程中都是选取第一个)作为基准,所有比基准小的元素都在基准的左边,而所有比基准大的元素都在基准的右边。之后分别对基准记录的左边和右边两个区间递归地进行快速排序。
参考代码如下:
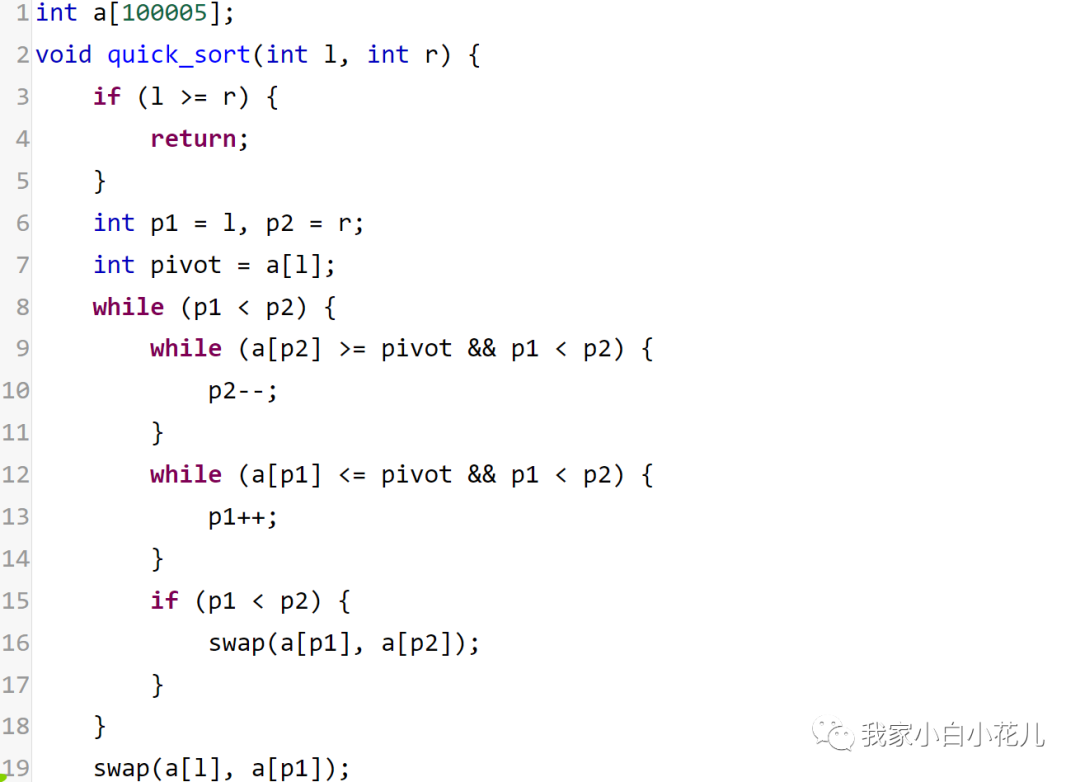

上述代码中,如果当前区间只有一个元素或为空,就直接返回。
p1和p2是两个用于扫描的指针,分别从左往右和从右往左扫,直到他们相遇为止。每一轮找到右边第一个小于基准的位置,和左边第一个大于基准的位置,把这两个位置的数交换。
最终循环结束时,,并且区间内元素都小于等
于基准,区间内的元素都大于等于基准。把基准元素和a[p1]交换,然后递归处理左边区间和右边区间。
下图是进行一轮快速排序的图示:
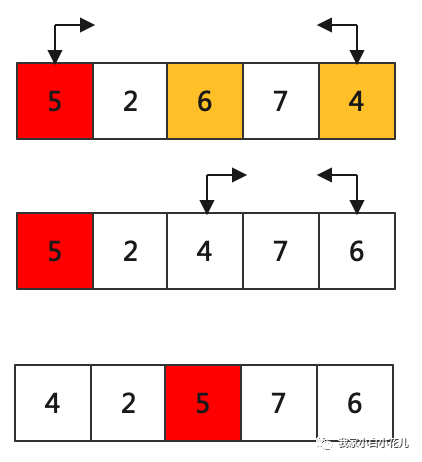
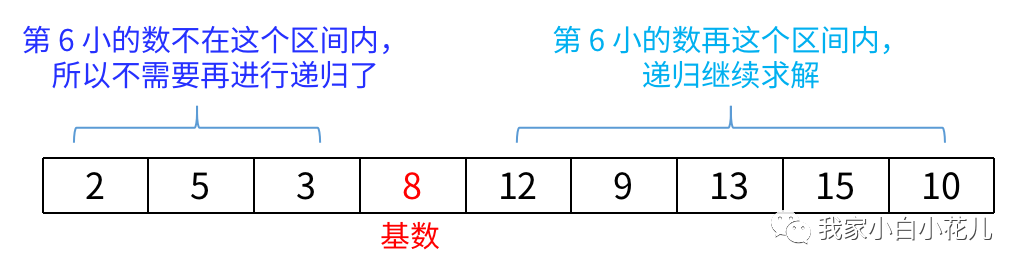
快速选择是基于快速排序算法查找第 k 小(大)数的问题。
原理: 每一轮快速排序的过程中:
-
左边所有数 < 基数;
-
右边所有数 >= 基数;
那么在每一轮排序的过程中基数的位置就是排序后该数的位置。

如果我们现在想要求解第 小的数,每次让 和排序后基数的位置id 进行比较,若:
k = id找到第 k 小的数;
k<id,在左区间内递归求解;
k>id,在右区间内递归求解。
例如k=6 时:
快速排序是不稳定的排序算法。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









