







文件与异常 这章中,遇到的关于出现 UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 4: illegal multibyte sequence 报错问题,程序运行后出现 \ufeff 问题都会有解释和处理办法
# 第七章
# 文件与异常
# 文件与文件类型
# 文件是一组相关数据的集合
# 组成文件的数据可以是ASCII编码,也可以是二进制编码
# 文件一定有一个文件名,文件名的长度和命名规则因不同的操作系统而异。但是无论是何种操作系统
# 文件名都包含两部分:主文件名和扩展名,两者之间用“.”隔开
# 全文件名 由用户根据操作系统的命名规则自行命名,用来与其他文件加以区别
# 扩展名 根据文件类型对应专属的缩写,用来指定打开和操作该文件的应用程序
# 例如,编写并保存的Python 语言源程序文件对应的扩展名就是.py
# 表示该文件需要用 Python 语言编辑器打开和处理
# 一般来说,文件都是按文件名访问的,一方面通过主文件名指明访问对象
# 另一方面通过扩展名指定访问和处理文件的应用程序
# 目录与文件路径
# 文件是用来组织和管理一组相关数据的,而目录是用来组织和管理一组相关文件的
# 目录又可称为文件夹,可以包含文件,也可以包含其他目录
# 文件保存的位置称为路径。
# 1.绝对路径
# 绝对路径是指从文件所在驱动器名称(又称“盘符“始描述文件的保存位置)
# 文件“5-1py”的对路径是“F盘根目下documents 目录下 python 目录下5-1.py文件”
# 具体可表示为:
# F:\documents\python\5-1.py
# 其中,反斜杠“\”是盘符、目录和文件之间在 Windows 换系统下的分隔符
# 如果要在Python 程序中描述一个文件的径,需要使用字符串
# 因为在字符串中,反斜杠“ ”是转义序列符,所以为了还原反斜杠分隔符的含义
# 在字符串中要连续写两个反斜杠如
# “F:\\documents\\python\\5-1.py”。
# 为了书写简便,Python 语言提供了另一种路径字符串的表示方法:
# r "F:\documents\python\5-1.py"
# 其中,r表示取消后续字符串中反斜杠“”的转义特性
# 在后续的代码中这两种路径字符写法会交替使用,请读者注意
# 2.相对路径
# 相对路径是指从当前工作目录开始描述文件的保存位置
# 每个运行的程序都有一个当前工作目录,又称为 cwd
# 一般来说,当前工作目录默认为应用程序的安装目录,可以通过Python语言自带的 os库函数 重新设置
# 下面的代码尝试将 cwd 从系统默认的设置修 documents 目录
import os
os.getcwd() #查看当前工作目录
print(os.getcwd())
# E:\Python\pythonProject
os.chdir('E:\\Python\\Ptest') #修改当前工作目录为 E盘根目录下 \Python\Ptest
print(os.getcwd())
# E:\Python\Ptest
# 一个特殊的标记“..”,它表示当前目录的上一级目录
# 文件操作
# 一般来说,文件的操作分以下三个步
# (1) 打开文件
# (2) 读文件或者写文件
# (3) 关闭文件
# 文件的打开与关闭
# 1.文件的打开
# 大多数文件都是长期保存在外部存储器的,需要操作时必须先调入内存,才能由 CPU进行处理
# 而“打开”操作就是将文件从外部存储器调入内存的过程,这个过程需要使用
# Python 语言内置的 open 命令,并生成一个 File 对象
# 具体的语法格式如下:
# file对象名 = open(文件路径字符串,模式字符)
# 其中,文件路径字符串可以采用绝对路径,也可以采用相对路径
# 打开文件的模式字符用于指定打开文件的类型和操作文件的方式
# 打开文件的模式字符: 'r','r+','w','w+','a','a+','rb','rb+','wb','wb+','ab','ab+'
# 2.文件的关闭
# 执行 open 命令打开文件后,这个文件就被 Python 程序占用并被调入内存。其后所有的读写操作都发生在内存
# 与此同时,其他任何应用程序都不能操作该文件
# 当读写操作结束后,必须将文件从内存保存回外存
# 这样做一方面为了将内存中文的变化同步至外存,以便长期保存;
# 另一方面是为了释放 Python 程序对文件的占用,让其他应用程序能够操作文件
# 这个将文件保存回外存的操作是由文件对象的close()方法实现的
# 具体的语法格式如下
# file 对象.close()
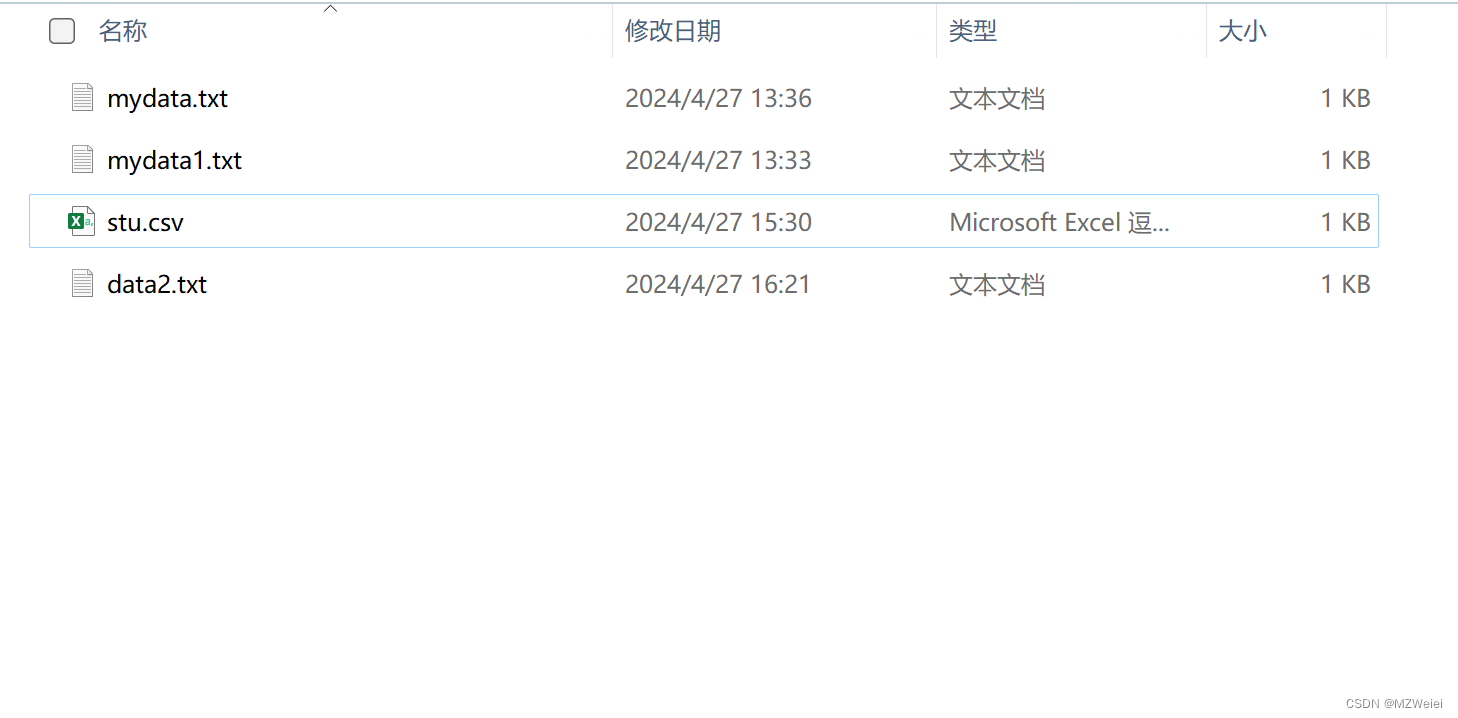
# 下面根据图7-1对应的目录结构尝试一些文件的打开操作。
# 下列代码中首先将当前工作目录设置为“python”;然后尝试用读模式打开当前目录下名
# 为“mydata.txt”的文本文件,如图 7-3 所示,该文件不存在,因此系统报错;再次尝试用写
# 模式扩开这个不存在的文件时,命令顺利执行,如图7-4 所示,系统会在“python”目录下新
# 建一个大小为“0字节”名称为“mydata.txt”的文件,并将其与文件对象 file进行关联
import os
print(os.getcwd())
# E:\Python\Ptest
'''filePractice = open('mydate.txt','r')'''
# 因为当前 E:\Python\Ptest 下没有mydate.txt这个文本文件,用 只读模式打开 会报错
# Traceback (most recent call last):
# File "E:\Python\pythonProject\mzw.py", line 4532, in <module>
# filePractice = open('mydate.txt','r')
# ^^^^^^^^^^^^^^^^^^^^^^
# FileNotFoundError: [Errno 2] No such file or directory: 'mydate.txt'
filePractice = open('mydate.txt','w')
# 用 只可写模式打开 不存在的文件,会新建
# 此时 在对应的 你的电脑里 "此电脑" 对应的 E:\Python\Ptest 下就会出现 mydate.txt 文本文件
print(filePractice)
# <_io.TextIOWrapper name='mydate.txt' mode='w' encoding='cp936'>
# 接下来关闭打开的 mydate.txt 文本文件
filePractice.close()
print(filePractice)
# <_io.TextIOWrapper name='mydate.txt' mode='w' encoding='cp936'>
# 调用了 close() 方法后,文件对象filePractice 依然与“mydata.txt”相关联
'''filePractice.write('文件已关闭')'''
# ValueError: I/O operation on closed file.
# 但是执行写操作时系统报错,不允许对关闭的文件执行任何读写操作
# 调用了 close() 方法关闭文件,文件是关闭的,但是依然与对应的文件对象相关联
# 在 Python 程序中,文件一旦打开都会和一个file对象相关联
# 随后的文件操作都通过调用file对象的方法来实现
# 写文件
# 内置命令 open 以写模式在“Ptest”目录下新建了一个新文件“mydata.txt”
# 从图看到该文件目前大小为 0,是个空文件
# 下面开始给这个文件写上内容
# 后续所有的文件操作都假设当前目录为“Ptest”
# 1.用file对象的 write()方法写文件
# write()方法将指定的字符串写入文件当前插入点位置
# 其具体的语法格式如下:
# file对象.write(写入字符串)
import os
print(os.getcwd()) # E:\Python\Ptest
'''filePractice = open('mydata.txt','w')'''
'''filePractice.write('飞雪连天射白鹿')'''
# print(filePractice.write('飞雪连天射白鹿'))
# 7
'''filePractice.write('笑书神侠倚碧鸳')'''
# print(filePractice.write('笑书神侠倚碧鸳'))
# 7
'''filePractice.close()'''
# 上面的示例代码将文件以写模式打开后,连续调用了两次 wtite() 方法,
# 写入了两个符串,每一次调用 write() 系统都会返回这次写入文件的字符数
# 从文本文件“mydata.txt”的内容中可以看出:
# (1)打开文件执行写入操作时连的 rte0方法按照顺序依次写入字符
# (2)文件的 write() 方法将指定的学符里参数原样写入文件,连续写入的不同字符间不会添加任何分隔符
# 2.用 file 对象的 writelines()方法写文件
# 与 write() 方法相比,
# writelines()方法可以以 序列 的形式接受多个字符串作为参数
# 一次性写入多个字符串
# 具体的语法格式如下:
# file 对象.writelines(字符串序列)
# 用的原文件,'w'只可写模式,会在原来的基础上是 重新覆盖写入的
filePractice=open("mydata.txt",'w')
filePractice.writelines(["飞雪连天射白鹿\t","笑书神侠倚碧鸳\n"])
filePractice.writelines (["横批:越女剑\n"])
filePractice.close()
# 下面我是新建了一个 mydata1.txt 文本文件
filePractice1=open("mydata1.txt",'w')
filePractice1.writelines(["飞雪连天射白鹿\t","笑书神侠倚碧鸳\n"])
filePractice1.writelines (["横批:越女剑\n"])
filePractice1.close()
# writelines()方法和 write()方法一样,都是字符串原样写入文件,不添加任何分隔符
# 所以只有在列表参数的每个字符串末尾加上分隔符,才能得到图所示带制表符和换行文件内容
# write()方法和 writelines()方法也可以用于追加模式('a'或者'a+'),
# 唯一的区别是追加模式写入的字符串都是从文件原来的 结尾处 开始写入,不是覆盖写入
# write()方法和 writelines()方法也可以用于追加模式('a'或者'a+'),
# 唯一的区别是追加模式写入的字符串都是从文件原来的 结尾处 开始写入,不是覆盖写入
# writelines()方法的参数除了列表之外,也可以是集合、元组,甚至是字典,但是元素一定要是字符串
# 读文件
# 1.用file对象的 read()方法读文件
# read()方法读出文件所有内容并作为一个字符串返回
# 具体的语法格式如下:
# 字符串变量 = file 对象.read()
file = open("mydata.txt",'r')
text = file.read()
print(text)
# 飞雪连天射白鹿 笑书神侠倚碧鸳
# 横批:越女剑
file.close()
# 从这里来看,同一个文件 所对应的文件对象的名字不必须是一样的,但指代的都是同一个文件
# 上述示例中,read()方法读取了“mydata.txt”文件中包括分隔符在内的所有内容,
# 并将其作为一个字符串返回赋值给了“text”变量
# 2.用 file 对象的 readline()方法读文件
# readline()方法将读出文件中 当前行 ,并以字符串的形式返回
# 具体的语法格式如下:
# 字符串变量 = file 对象.readline()
file = open("mydata.txt",'r')
text = file.readline()
print(text)
# 飞雪连天射白鹿 笑书神侠倚碧鸳
text=file.readline()
print(text)
# 横批:越女剑
file.close()
# 用读模式打开文件后,连续调用了两次readline()方法, 依次 读出了文件中的两行
# 可见,如果文件包含更多行,只需配合恰当的 for 循环也能顺利按行读出文件内容
# 3,用file 对象的readlines()方法读文件
# readlines()方法以 列表的形式 返回整个文件的内容,其中一行对应一个列表元素
# 具体的语法格式如下:
# 列表变量 = file 对象.readlines()
file = open("mydata.txt",'r')
ls = file.readlines()
print(ls)
# ['飞雪连天射白鹿\t笑书神侠倚碧鸳\n', '横批:越女剑\n']
file.close()
# 与readline()方法相比,readlines()方法以更简洁的方式按行读出了整个文件的内容
# 后续只要通过简单的列表遍历就可以取出任意一行进行处理
# CSV 文件操作
# CSV(Comma-SeparatedValues)是指号分隔值)CSV 文件可以理解为用带号分隔
# (可以是其他简单字符分割)的纯文本形式存储表格数据的文件
# CSV文件可以用记事本、写字板和 Excel打开
# 因为不带任何格式信息,所以 CSV 文件广泛应用于在不同程序之间转移表格数据
# CSV 文件的分隔符不限定为逗号,但是作为 CSV 文件,一般需要具有以下特征:
# (1)纯文本,使用某个字符集,如 ASCII、Unicode、EBCDIC或GB2312
# (2)由记录组成,一行对应一条记录,每行开头不留空格
# (3)每条记录被 英文半角分隔符 (可以是逗号、分号、制表符等)分割为多个字段
# (4)每条记录都有同样的字段序列
# (5)如果文件包含字段名,字段名写在文件第一行
# (6)不包含特殊字符,文件中均为字符串
# 针对CSV文件,Python 语言提供了内置同名模块进行读写操作
# 使用时需要定义 reader对象 和 writer对象
# CSV文件的打开
# CSV 文件可以使用 open 命令直接打开,用法和前面介绍的一样
# 但是使用 open 命令打开的文件一定要通过调用 close()方法进行关闭
# 因此,当需要频繁进行文件操作时,使用 open 命令会显得有些烦琐
# 所以,Python 语言引入了 with 语句用来打开文件,并在文件操作结束后 自动关闭文件
# 除了语法书写上有变化,其他的与前面的的类似
# 其具体的语法格式如下:
# with open(文件路径字符串,模式字符) as 文件对象名:
# 文件操作语句
with open("mydata.txt",'r') as file:
print(file.readline())
# 飞雪连天射白鹿 笑书神侠倚碧鸳
print(file.readline())
# 横批:越女剑
# 使用 with 语句用读模式打开了“mydata.txt”文件后,两次调用readline()方法读出了文件中两行的内容
# 当文件读操作结束后,系统自动调用了 close()方法关闭了文件
# 从结构上来看,with 语句更清晰地描述了文件从打开到操作完毕的整个过程,使用起来也更为方便简洁
# 在后续 CSV 文件的操作中,都将使用 with 语来打开和处理文件
# reader 对象
# 使用csv模块读取CSV文件数据时需要先创建一个reader对象
# 然后通过选代遍历reader对象来遍历文件中的每一行
# 下面以读 stu.csv 文件为例来讲解reader 对象的具体使用
# import csv
# with open("stu.csv",'r') as stucsv:
# reader = csv.reader(stucsv)
# for row in reader:
# print(row)
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 4: illegal multibyte sequence
# UnicodeDecodeError:“gbk”编解码器无法解码位置 4 中的字节0xa7:非法多字节序列
# 下面分析报错的原因
# UnicodeDecodeError 通常表示你试图使用某种编码(如 'gbk')来解码
# 一个实际上是用另一种编码(如 'utf-8')编码的字节序列,而这种编码之间无法正确转换
# 在我的这种情况下,错误信息表明,尽管文件是用 'utf-8' 编码的,但是 Python 却试图用 'gbk' 编码来解码它,导致解码失败
# 这个错误通常发生在以下几种情况:
# 文件实际上是使用 'gbk' 编码的,但是你告诉 Python 用 'utf-8' 来解码它
# 文件包含一些 'utf-8' 编码无法处理的字符,但是你试图用 'utf-8' 来解码整个文件。
# 系统的默认编码不是 'utf-8',而是 'gbk' 或者其他,因此当你尝试读取文件时,它会尝试使用系统的默认编码
# 下面是改正过后的做法
import csv
with open("stu.csv", 'r', encoding='utf-8-sig') as stucsv:
reader = csv.reader(stucsv)
for row in reader:
print(row)
# 关键是加了 encoding='utf-8-sig',这个操作是以utf-8的编码方式解读文件
# 如果没有后面的 -sig 导致程序运行后出现\ufeff
# 是因为文件中存在一个不可见的字节顺序标记(BOM),它表示文件是以UTF-8编码格式存储的
# 在读取CSV文件时,这个BOM可能会导致输出结果中出现\ufeff字符
# 为了避免这个问题,可以在打开文件时添加`utf-8-sig`编码参数,这样Python会自动处理BOM
# ['姓名', '性别', '年龄']
# ['李明', '男', '19']
# ['杨柳', '女', '18']
# ['张一凡', '男', '18']
# ['许可', '女', '20']
# ['王小小', '女', '19']
# ['陈心', '女', '19']
# 上述代码中,用 with 语句以读模式打开 stu.csv 文件后
# 针对该文件创建了一个 CSV的reader对象 reader,然后通过 for 循环遍历了对象 reader
# 最后按行输出了文件中的数据
# 从输出形式来看,每一行都以列表的形式输出,且文件中所有的数据都是字符串
# writer 对象
# 用csv模块将数据写入CSV文件时就需要创建 writer对象
# 因为 CSV 文件都是 按行 存储的,所以写文件时需要调用 writer 对象的 writerow()方法
# 将用列表存储的一行数据写入文件
# 下面,依然以 stu.csv 文件为例,通过 csv 模块的 writer 对象向文件中 追加 两条新的记录:
# " '张芳','女',20 "和" '王虎','男',18 "
import csv
with open("stu.csv",'a',encoding='utf-8') as stucsv:
writer = csv.writer(stucsv)
writer.writerow(['张芳','女',20])
writer.writerow(['王虎','男',18])
# 这样写会有空行出现,对于 CSV文件,如果在记录之间出现了空行,在读文件的时候会出现错误
# 因此需修改代码段,在打开文件时增加一个参数“ newline='' ”,指明在写入新的记录后不插入空行
# 这里我手动进入了csv文件将刚刚写入的删除了
# 然后重新在敲一遍,这次加上 newline=''
import csv
with open("stu.csv",'a',encoding='utf-8',newline='') as stucsv:
writer = csv.writer(stucsv)
writer.writerow(['张芳','女',20])
writer.writerow(['王虎','男',18])

# import csv
# with open("stu.csv",'a',encoding='utf-8',newline='') as stucsv:
# writer = csv.writer(stucsv)
# writer.writerow(['张芳','女',20])
# writer.writerow(['王虎','男',18])
# csv 的 writer 对象也提供一次写入多行的方法 writerows()
# writerows()方法将参数列表中的每一个元素列表作为一行写入 CSV 文件
# 下列代码示范了如何调用 writerows()方法一次写入两行记录
import csv
with open("stu.csv",'a',encoding='utf-8',newline='') as stucsv:
writer = csv.writer(stucsv)
writer.writerows([['张三','男',20],['李四','男',18]])
# writer 对象的 writerows()方法只接受一个序列作为参数,可以是列表,也可以是元组

# 异常和异常处理
# 什么是异常
# 在学习 Python 语言的过程中,碰到过程序出错的情况,
# 有可能是引用了未定义的变量,有可能是访问了字典中不存在的键,也有可能是用读模式打开了一个不存在的文件
# 不管出现什么样的错误,都会导致程序终止运行,并输出错误信息
# 这些错误影响了程序的正常执行,被称为异常
# 在 Python 语言中,不同的异常被定义为不同的对象,对应不同的错误
# Python 语言中几种常见的异常及其描述
# Exception
# 常规异常的基类
# ZeroDivisionError
# 除数为零
# IOError
# 输入/输出操作失败
# IndexError
# 序列中没有此索引(index)
# KeyError
# 映射中没有这个键
# NameError
# 未声明/初始化对象 (没有属性)
# 异常会立刻终止程序的执行,无法实现原定的功能
# 但是,如果在异常发生时能及时捕获并做出处理,就能控制异常、纠正错误、保证程序的顺利执行
# 异常处理
# Python 语言中专门提供了 try 子句来进行异常的捕获与处理
# 最简单的 try 子句格式如下:
# try:
# 语句
# except 异常名称:
# 捕获异常时处理
# else:
# 未发生异常时处理
# 程序执行时,如果 try 子句中发生了指定的异常,则执行 except 子句部分进行异常的处理
# 如果 try 子句执行未发生异常则执行 else 子句部分
# 例7-1 从键盘输入a和 b,求a 除以的结果并输出
# 从键盘输入除数,就有可能会输入 0,而除数为 0是个很严重的错误
# 应该进行 ZeroDivisionError 异常的捕获和处理
try:
a = eval(input("a = "))
b = eval(input("b = "))
c = a / b
except ZeroDivisionError:
print('除数不能为0!')
else:
print("c = ",c)
# a = 10
# b = 2
# c = 5.0
# a = 4
# b = 0
# 除数不能为0!
# 例7-2
# 读取并输出 E:\Python\Ptest 目录下 data2.txt 文件中的内容,如果文件不存在则提醒用户先创建文件
# 题目要求读出文件内容,需要用读模式打开
# 但是如果文件不存在系统会报错,所以需要进行IOError 异常的捕获和处理
try:
file = open('data2.txt','r')
except IOError:
print('文件不存在,请先创建!')
else:
text = file.read()
print('data2.txt文件的内容是:',text)
file.close()
# 文件不存在,请先创建!
# 所以我们先创建文件并在里面写入内容
# 创建
file = open('data2.txt','w')
# 写入内容
file.write('我是文件data2.txt')
# 关闭文件 file.close()
# 再次执行
# try:
# file = open('data2.txt','r')
# except IOError:
# print('文件不存在,请先创建!')
# else:
# text = file.read()
# print('data2.txt文件的内容是:',text)
# file.close()
# data2.txt文件的内容是: 我是文件data2.txt
# 根据提示信息创建了 data2.txt 文件并输入内容后
# 再次执行程序,没有触发任何异常,程序执行了 else 部分,输出了文件中保存的文本信息
# 异常处理不能“消灭”异常本身,但是却可以让原本不可控的异常及时被发现,并按照设计好的方式被处理
# 异常处理让程序不会被意外地终止,而是按照设计以不同的方式结束运行
# 在这个设计中,except后的异常类型至关重要,需要根据 try 子句的具体操作进行恰当的选择
# 如果实在不确定异常的类型,可以用通用的异常对象 Exception 来捕获
# 删除文件
# import os
# os.remove(文件路径)
# 或者
# import os
# file文件对象 = 要删除的文件路径
# os.remove(file文件对象)
# 例如:
# os.remove('E:\\Python\\Ptest\\mydata.txt')















 8031
8031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









