






首先进入后发现是控制流平坦化,所以先用D-810去混淆,然后发现它有个main函数,我们进去看。
从上往下一步步分析,

s是我们的输入,v16和v3都是长度。
然后进入第一个函数sub_401980。发现像是一段加密函数,用插件查找加密特征,发现base64的编码,可以确定这是base64加密函数,但是现在只能确定的是表是变的。找到base表,
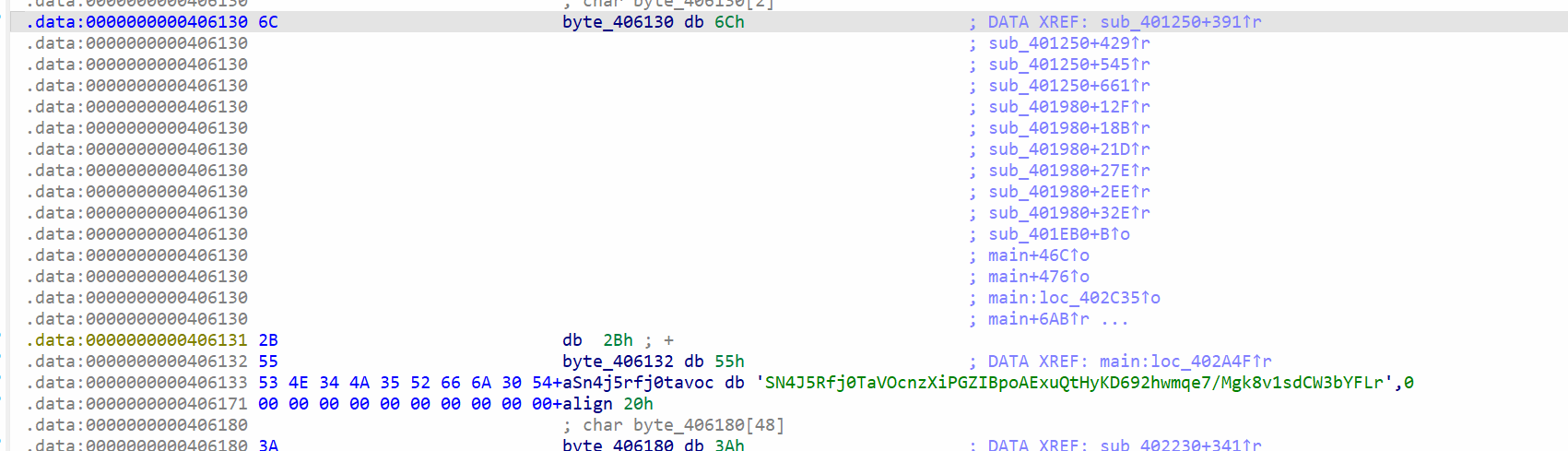
IDA分析不准确,选中按A。

现在的base表十分清晰可观。
回去接着分析,那么v11就是加密后的input,然后下面有一个4次的for循环

看见srand函数,然后进入sub_401D10查看
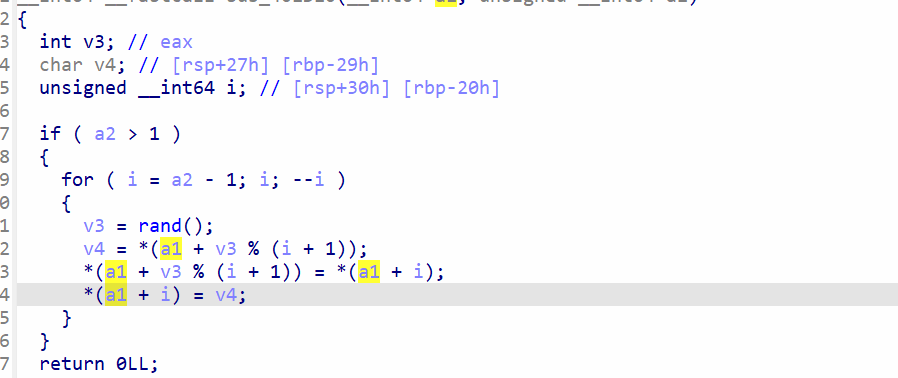
简单分析发现是对base表的变表操作。
再往下是一个if判断,和1进行与运算,就是判断奇偶,奇数进入if,偶数进入else。
if是之前的base加密,然后进入else的函数看一下。
简单看了下发现是根据索引再根据base表赋值,大概就可以看出是个base的解码函数,但是由于base表一直在变,所以这一步解密也是加密操作。
最下面有个很奇怪的判断。

查看if里变量的调用,找到在这个函数赋值
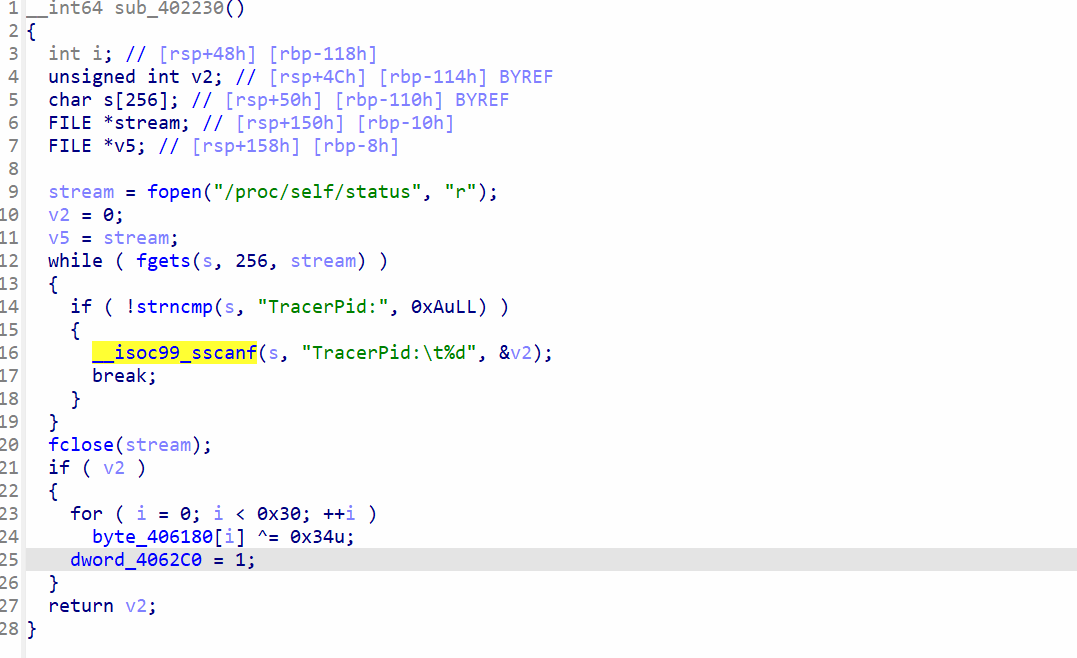
这个函数的作用是根据是否处于动调进行操作,很明显,如果我们动调,dword_4062c0就会被赋值1,那么就会进入这个if判断。
所以正常情况下运行我们因该进入的是else段。
再往下又是一个函数sub_401EB0
进入查看

因为是根据%来进行操作,所以我们最好的选择是用z3进行求解。
出来再往下看,发现已经到字符判断,也就是最后了。
总结一下来看,我们需要再静态下拿到最后的对照字符表来作为密文解密,第一步是根据密文运用z3来暴力破解最后的一个加密,然后再根据4次循环的奇数偶数来进行base解加密,最后再来一次base解密即可。
z3暴力求解脚本
from z3.z3 import *
s=Solver()
table=[0x3A, 0x2C, 0x4B, 0x51, 0x68, 0x46, 0x59, 0x63, 0x24, 0x04, 0x5E, 0x5F, 0x00, 0x0C, 0x2B, 0x03, 0x29, 0x5C, 0x74, 0x70, 0x6A, 0x62, 0x7F, 0x3D, 0x2C, 0x4E, 0x6F, 0x13, 0x06, 0x0D, 0x06, 0x0C, 0x4D, 0x56, 0x0F, 0x28, 0x4D, 0x51, 0x76, 0x70, 0x2B, 0x05, 0x51, 0x68, 0x48, 0x55, 0x24, 0x19]
key=[0x53, 0x46, 0x4E, 0x72, 0x49, 0x42, 0x6D, 0x6E, 0x4F, 0x4C, 0x10, 0x56, 0x74, 0x7E, 0x62, 0x4D,
0x63, 0x16, 0x6C, 0x4A, 0x1E]
cmp=[BitVec('%d' % i, 8) for i in range(48)]
j=2023
i=0
for i in range(47):
if i%3==1:
j = (j + 5) % 20;
ckey = key[j + 1];
elif i%3==2:
j = (j + 7) % 19;
ckey = key[j + 2];
else:
j = (j + 3) % 17;
ckey = key[j + 3];
cmp[i]^=ckey
cmp[i+1]^=cmp[i];
for i in range(48):
s.add(cmp[i]==table[i])
if s.check():
m=s.model()
cmp = [BitVec("%d" % i, 8) for i in range(48)]
res=[]
for i in range(48):
print(m[i])
res.append(m[cmp[i]])
print(res)
print("".join([chr(i)for i in res]))然后是因为动调干扰的是最后的对照表,所以我们还是可以通过动调来拿到五张base表。
"l+USN4J5Rfj0TaVOcnzXiPGZIBpoAExuQtHyKD692hwmqe7/Mgk8v1sdCW3bYFLr";
"FGseVD3ibtHWR1czhLnUfJK6SEZ2OyPAIpQoqgY0w49u+7rad5CxljMXvNTBkm/8";
"Hc0xwuZmy3DpQnSgj2LhUtrlVvNYks+BX/MOoETaKqR4eb9WF8ICGzf6id1P75JA";
"pnHQwlAveo4DhGg1jE3SsIqJ2mrzxCiNb+Mf0YVd5L8c97/WkOTtuKFZyRBUPX6a";
"plxXOZtaiUneJIhk7qSYEjD1Km94o0FTu52VQgNL3vCBH8zsA/b+dycGPRMwWfr6";
这里是用的网上的C语言base64脚本修改来写,我一般不喜欢用库,因为怕魔改加密。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
unsigned char* base64_encode(const char* str0, unsigned char base64_map[64])
{
unsigned char* str = (unsigned char*)str0; //转为unsigned char无符号,移位操作时可以防止错误
//数组形式,方便修改
long len; //base64处理后的字符串长度
long str_len; //源字符串长度
long flag; //用于标识模3后的余数
unsigned char* res; //返回的字符串
str_len = strlen((const char*)str);
switch (str_len % 3) //判断模3的余数
{
case 0:flag = 0; len = str_len / 3 * 4; break;
case 1:flag = 1; len = (str_len / 3 + 1) * 4; break;
case 2:flag = 2; len = (str_len / 3 + 1) * 4; break;
}
res = (unsigned char*)malloc(sizeof(unsigned char) * len + 1);
for (int i = 0, j = 0; j < str_len - flag; j += 3, i += 4)//先处理整除部分
{
//注意&运算和位移运算的优先级,是先位移后与或非
res[i] = base64_map[str[j] >> 2];
res[i + 1] = base64_map[(str[j] & 0x3) << 4 | str[j + 1] >> 4];
res[i + 2] = base64_map[(str[j + 1] & 0xf) << 2 | (str[j + 2] >> 6)];
res[i + 3] = base64_map[str[j + 2] & 0x3f];
}
//不满足被三整除时,要矫正
switch (flag)
{
case 0:break; //满足时直接退出
case 1:res[len - 4] = base64_map[str[str_len - 1] >> 2]; //只剩一个字符时,右移两位得到高六位
res[len - 3] = base64_map[(str[str_len - 1] & 0x3) << 4];//获得低二位再右移四位,自动补0
res[len - 2] = res[len - 1] = '='; break; //最后两个补=
case 2:
res[len - 4] = base64_map[str[str_len - 2] >> 2]; //剩两个字符时,右移两位得高六位
res[len - 3] = base64_map[(str[str_len - 2] & 0x3) << 4 | str[str_len - 1] >> 4]; //第一个字符低二位和第二个字符高四位
res[len - 2] = base64_map[(str[str_len - 1] & 0xf) << 2]; //第二个字符低四位,左移两位自动补0
res[len - 1] = '='; //最后一个补=
break;
}
res[len] = '\0'; //补上字符串结束标识
return res;
}
unsigned char findPos(const unsigned char* base64_map, unsigned char c)//查找下标所在位置
{
for (int i = 0; i < strlen((const char*)base64_map); i++)
{
if (base64_map[i] == c)
return i;
}
}
unsigned char* base64_decode(const char* code0, unsigned char base64_map[64])
{
unsigned char* code = (unsigned char*)code0;
long len, str_len, flag = 0;
unsigned char* res;
len = strlen((const char*)code);
if (code[len - 1] == '=')
{
if (code[len - 2] == '=')
{
flag = 1;
str_len = len / 4 * 3 - 2;
}
else
{
flag = 2;
str_len = len / 4 * 3 - 1;
}
}
else
str_len = len / 4 * 3;
res = (unsigned char*)malloc(sizeof(unsigned char) * str_len + 1);
for (int i = 0, j = 0; j < str_len - flag; j += 3, i += 4)
{
unsigned char a[4];
a[0] = findPos(base64_map, code[i]); //code[]每一个字符对应base64表中的位置,用位置值反推原始数据值
a[1] = findPos(base64_map, code[i + 1]);
a[2] = findPos(base64_map, code[i + 2]);
a[3] = findPos(base64_map, code[i + 3]);
res[j] = a[0] << 2 | a[1] >> 4; //取出第一个字符对应base64表的十进制数的前6位与第二个字符对应base64表的十进制数的后2位进行组合
res[j + 1] = a[1] << 4 | a[2] >> 2; //取出第二个字符对应base64表的十进制数的后4位与第三个字符对应bas464表的十进制数的后4位进行组合
res[j + 2] = a[2] << 6 | a[3]; //取出第三个字符对应base64表的十进制数的后2位与第4个字符进行组合
}
switch (flag)
{
char a[1024];
case 0:break;
case 1:
{
a[0] = findPos(base64_map, code[len - 4]);
a[1] = findPos(base64_map, code[len - 3]);
res[str_len - 1] = a[0] << 2 | a[1] >> 4;
break;
}
case 2: {
a[0] = findPos(base64_map, code[len - 4]);
a[1] = findPos(base64_map, code[len - 3]);
a[2] = findPos(base64_map, code[len - 2]);
res[str_len - 2] = a[0] << 2 | a[1] >> 4;
res[str_len - 1] = a[1] << 4 | a[2] >> 2;
break;
}
}
res[str_len] = '\0';
return res;
}
int main()
{
int i;
//测试数据 hello
//aGVsbG8=
//aGVsbG82
//aGVsbG==
/*char str[100];
int flag;
printf("请选择功能:\n");
printf("1.base64加密\n");
printf("2.base64解密\n");
scanf("%d", &flag);
printf("请输入字符串:\n");
scanf("%s", str);
if (flag == 1)
printf("加密后的字符串是:%s", base64_encode(str));
else
printf("解密后的字符串是:%s", base64_decode(str));*/
char str[] = { 0x3A, 0x2C, 0x4B, 0x51, 0x68, 0x46, 0x59, 0x63, 0x24, 0x04, 0x5E, 0x5F, 0x00, 0x0C, 0x2B, 0x03,
0x29, 0x5C, 0x74, 0x70, 0x6A, 0x62, 0x7F, 0x3D, 0x2C, 0x4E, 0x6F, 0x13, 0x06, 0x0D, 0x06, 0x0C,
0x4D, 0x56, 0x0F, 0x28, 0x4D, 0x51, 0x76, 0x70, 0x2B, 0x05, 0x51, 0x68, 0x48, 0x55, 0x24, 0x19 };
char str2[] = "WZqSWcUtWBLlOriEfcajWBSRstLlkEfFWR7j/R7dMCDGnp==";
char base1[] = "l+USN4J5Rfj0TaVOcnzXiPGZIBpoAExuQtHyKD692hwmqe7/Mgk8v1sdCW3bYFLr";
char base2[] = "FGseVD3ibtHWR1czhLnUfJK6SEZ2OyPAIpQoqgY0w49u+7rad5CxljMXvNTBkm/8";
char base3[] = "Hc0xwuZmy3DpQnSgj2LhUtrlVvNYks+BX/MOoETaKqR4eb9WF8ICGzf6id1P75JA";
char base4[] = "pnHQwlAveo4DhGg1jE3SsIqJ2mrzxCiNb+Mf0YVd5L8c97/WkOTtuKFZyRBUPX6a";
char base5[] = "plxXOZtaiUneJIhk7qSYEjD1Km94o0FTu52VQgNL3vCBH8zsA/b+dycGPRMwWfr6";
char base6[21] = {0};
int j = 0;
/*for (i =6; i <27; i++)
{
base6[j] = base5[i] ^ 0x27;
printf("0x%x,", base6[j]);
j++;
}*///char key[] = { 0x53,0x46,0x4e,0x72,0x49,0x42,0x6d,0x6e,0x4f,0x4c,0x10,0x56,0x74,0x7e,0x62,0x4d,0x63,0x16,0x6c,0x4a,0x1e };
char* stt = base64_decode(str2,base5);;
char* srr = base64_encode(stt, base4);
stt = base64_decode(srr, base3);
srr = base64_encode(stt, base2);
stt = base64_decode(srr, base1);
printf("%s", stt);
return 0;
}最后,不知道为什么我的flag少一个括号,可能脚本还有点缺陷,但也已经大差不差了。















 43
43











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









