






一、列表的特点与创建
1.列表的特点
•列表的数据类型为list,定界符是方括号[ ]
•列表的元素用逗号隔开,元素的类型可以不同
•
列表可以
嵌套
2.列表的创建
list1=["郑阿奇", "齐大伟", "小甲鱼"]
print(list1)
list2=[82,67,75]
print(list2)
list3=["郑阿奇",82,"齐大伟",67]
print(list3)
list4=[["郑阿奇", "齐大伟", "小甲鱼"], [82,67,75]]
print(list4)
list5=[ ] #等价于list5=list()
list5.append(82)
list5.append(67)
list5.append(75)
print(list5)
二、列表的基本操作
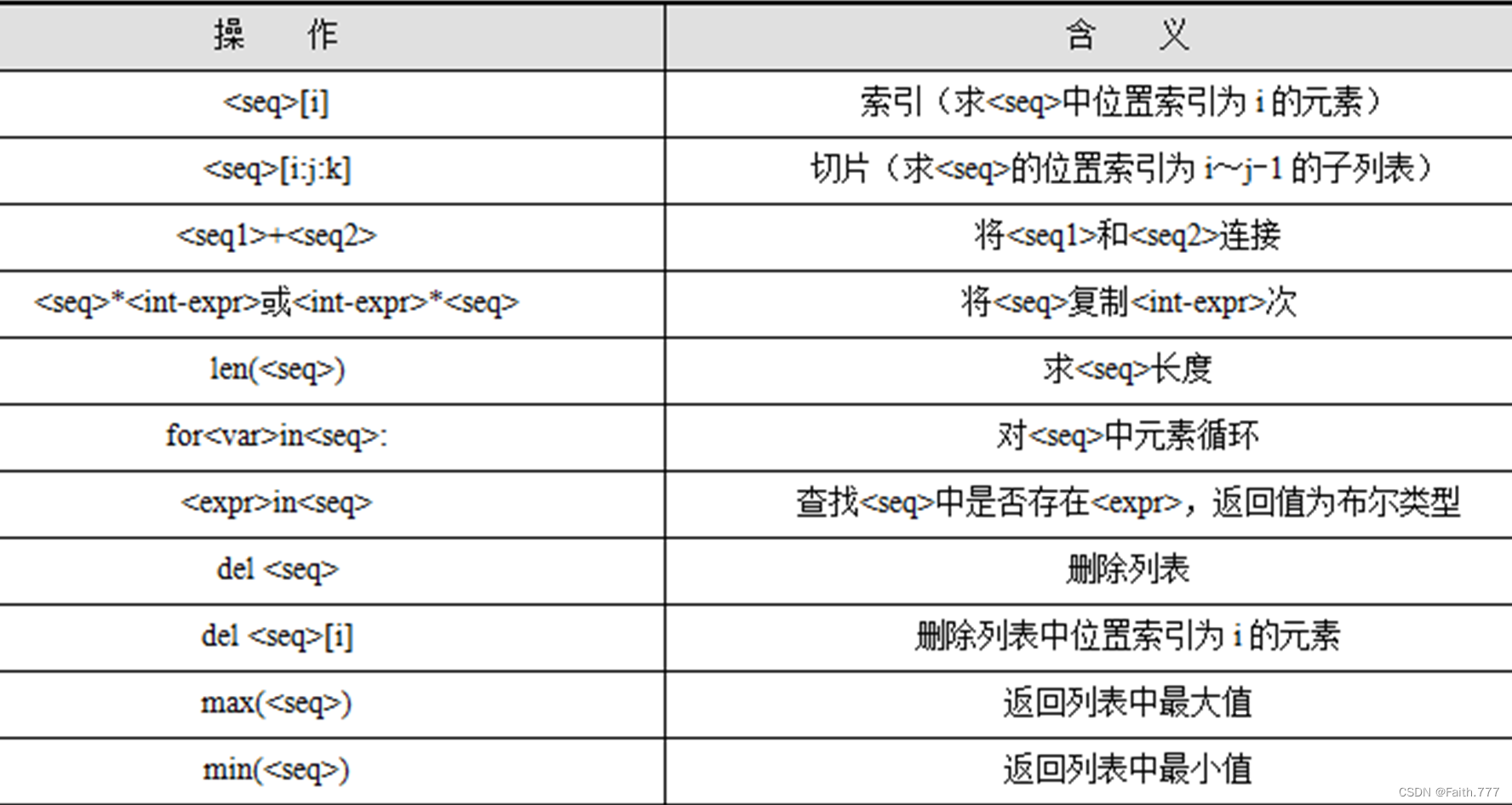
1.索引
【例题】利用索引来检索Python成绩
| 姓名 | Python |
| 郑阿奇 | 82 |
| 齐大伟 | 67 |
| 小甲鱼 | 75 |
| 董付国 | 84 |
| 何晗 | 73 |
| 李小刚 | 88 |
| 周远泽 | 97 |
| 嵩天 | 86 |
问题1:显示Python成绩的最低分
问题2:显示Python成绩的最高分
问题3:求Python成绩的平均值
import pandas
data=pandas.read_excel("dataFile/score.xls")
print(data)
listx=list(data["Python"])
print(listx)
listx=sorted(listx) #升序排列
print(listx)
#问题1:显示Python成绩的最低分
print(listx[0])
#问题2:显示Python成绩的最高分
print(listx[-1])
#问题3:求Python成绩的平均值
sumy=0
for i in range(len(listx)): #range(0,8,1)
sumy=sumy+listx[i]
print(sumy/len(listx))
2.切片
#问题1:求分数最低的3位学生的Python成绩平均分
#问题2:求分数最高的3位学生的Python成绩平均分
3问题3:抽样奇数位的Python成绩
print(sum(listy[:3])/3)
print(sum(listy[-3:])/3)
print(listx[0::2]) #还可以简化吗?
3.运算符
+:连接两个列表
*:重复列表元素
in / not in :列表元素检测
lst=[ 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
lst+[1,2,3]: ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 1, 2, 3]
lst*2:['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
"A" in lst:True
"K" not in lst:True
4.内置函数
max():返回列表元素的最大值
min():返回列表元素的最小值
sum():返回列表中元素之和
len():返回列表中元素的个数
import pandas
data=pandas.read_excel("dataFile/score.xls")
print(data)
listx=list(data["Python"])
print(listx)
print(min(listx))
print(max(listx))
print(sum(listx)/len(listx))
三、列表的更多操作
1.列表元素的添加
lst.append(元素 ):在末尾追加单个元素
import pandas
data=pandas.read_excel("dataFile/score.xlsx")
print(data)
listx=list(data["Python"])
print(listx)
listx[0]=65
print(listx)
listx[1:4]=[60,70,80]
print(listx)
lst.insert( 索引,元素):在指定位置插入单个元素
lst.extend(序列):在末尾追加另一个序列中的全部元素
2. 列表元素的修改
修改单个元素:lst[索引]=值
修改多个元素:lst[切片]=列表
import pandas
data=pandas.read_excel("dataFile/score.xlsx")
listx=list(data["Python"])
print(listx)
listx.append(11)
rint(listx)
listx.extend([22,33])
print(listx)
listx.insert(1,44)
print(listx)
3.列表元素的删除
lst.pop(索引):移除并返回指定位置的元素(默认是最后一个)
lst.remove(元素):移除列表中某个值的第一个匹配项
lst.clear():清除列表中的所有元素
score=[89.5,92.18,91.66,87.85,90.33,90.50,90.50,89.50]
print(score)
highest=max(score)
lowest=min(score)
score.remove(highest)
score.remove(lowest)
print(score)
avg=sum(score)/len(score)
print("最高分:",highest)
print("最低分:",lowest)
print("平均分:",avg)
其它删除列表元素的方法:
•
del lst[
索引
]
:删除某一个元素
•
del lst[
切片
]
:删除某一些元素
•
del lst
:删除整个列表
•
lst
[
切片
]=[ ]
:删除某一些元素
•
lst
[:]=[ ]
:清空列表元素
lst=[1,2,3,4,5,6,7,8,9,10]
del lst[1]
print(lst)
del lst[1:3]
print(lst)
lst[1:3]=[ ]
print(lst)
del lst
print(lst)
4. 列表元素的判断
lst.count(元素):统计元素在列表中出现的次数
lst.index(元素):找出某元素第一次出现的位置
5. 列表元素的翻转
lst.reverse():将列表中元素顺序全部反向
import pandas
data=pandas.read_excel("dataFile/score.xls")
print(data)
listx=list(data["Python"])
print(listx)
listx.reverse()
print(listx)
6. 列表元素的排序
lst.sort(key,reverse):对列表进行排序
•
reverse
:
False
(升序,默认)
/ True
(降序)
•
key
:排序的依据
#升序/降序排列Python成绩
import pandas
data=pandas.read_excel("dataFile/score.xls")
print(data)
listx=list(data["Python"])
print(listx)
listx.sort()
print(listx)
listx.sort(reverse=True)
print(listx)
#按字数排列学生姓名
import pandas
data=pandas.read_excel("dataFile/score.xls")
print(data)
listx=list(data["姓名"])
print(listx)
listx.sort(key=len)
print(listx)
listx.sort(key=len,reverse=True)
print(listx)
如果列表中是数字就按大小排序,如果是字符串则按第一个字母的ASCII码值大小排序
四、列表解析式
1.列表解析式的基本语法
列表解析式(列表推导式)可以快速生成/创建满足特定需求的一个列表。它在逻辑上等价于一个循环语句,只是形式上更加简洁。
[ <表达式> for <变量> in <序列> if <条件> ]
•
在
for
循环过程中,如果
<
条件
>
成立,将
<
表达式
>
的值添加到列表中
•
一般来说表达式
=f(
变量
)
,表达式也可以与变量无关
•
if <
条件
>
是可选的
lst=[ ]
for x in range(1,101,1):
if x%3==0:
lst.append(x)
print(lst)
lst=[x for x in range(1,101,1) if x%3==0]
print(lst)
找出两个字的名字
listx=list(data["姓名"])
print(listx)
shortName=[name for name in listx if len(name)==2]
print(shortName)2.复杂的列表解析式
用列表解析式实现嵌套列表的平铺
lst=[[1,2,3],[4,5,6],[7,8,9]]
list2=[]
for elem in lst
for exp in elem:
list2.append(exp)
print(list2)
lst=[[1,2,3],[4,5,6],[7,8,9]]
lst3=[exp for elem in lst for exp in elem]
print(lst3)
#结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









