







目的:熟练操作组合数据类型。
试验任务:
1. 基础:生日悖论分析。如果一个房间有23人或以上,那么至少有两 个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数 量下,23个人中至少两个人生日相同的概率。
2.进阶:统计《一句顶一万句》文本中前10高频词,生成词云。
3.拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古 龙)作品的最常用10个词语,找到其中的相关性,总结其风格。
1.
import random
import matplotlib.pyplot as plt
def birthday_paradox_simulation(num_people, num_simulations):
"""
生日悖论模拟
"""
match_count = 0
for _ in range(num_simulations):
birthdays = [random.randint(1, 365) for _ in range(num_people)]
if len(birthdays) != len(set(birthdays)):
match_count += 1
return match_count / num_simulations
def analyze_birthday_paradox():
"""分析生日悖论"""
num_people = 23
simulation_sizes = [100, 1000, 5000, 10000, 20000, 50000, 100000]
probabilities = []
for size in simulation_sizes:
prob = birthday_paradox_simulation(num_people, size)
probabilities.append(prob)
print(f"模拟次数: {size:6d}, 概率: {prob:.4f}")
# 绘制结果
plt.plot(simulation_sizes, probabilities, 'bo-')
plt.axhline(y=0.5, color='r', linestyle='--')
plt.xscale('log')
plt.xlabel('模拟次数 (对数尺度)')
plt.ylabel('概率')
plt.title('23人中至少两人生日相同的概率随模拟次数的变化')
plt.grid(True)
plt.show()
# 运行分析
analyze_birthday_paradox()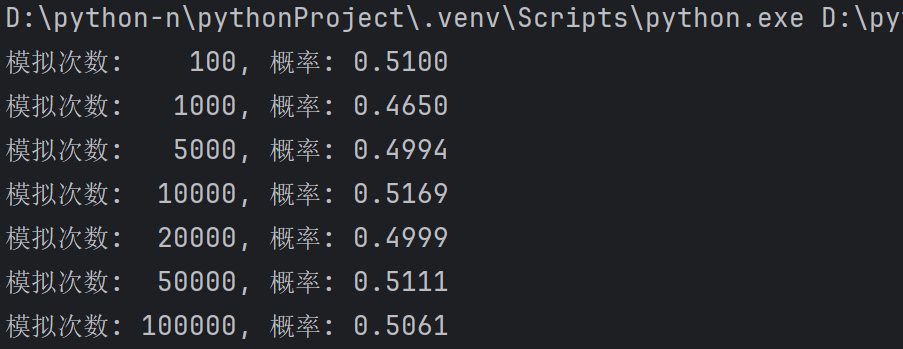
2.
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def process_text(text):
words = jieba.lcut(text)
stopwords = set(['的', '了', '和', '是', '在', '我', '有', '他', '她', '这', '那'])
return [word for word in words if len(word) > 1 and word not in stopwords]
def generate_wordcloud(text):
try:
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 或使用绝对路径
width=800,
height=600,
background_color='white'
).generate(text)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
except Exception as e:
print(f"生成词云出错: {e}")
def analyze_yijudingyiwanyu():
try:
with open('D:/yijudingyiwanyu.txt', 'r', encoding='utf-8') as f:
text = f.read()
words = process_text(text)
word_counts = Counter(words)
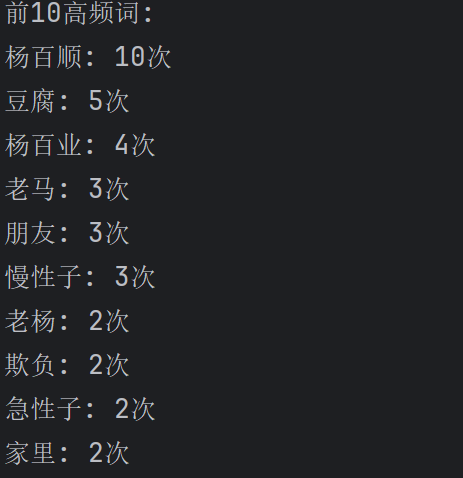
print("前10高频词:")
for word, count in word_counts.most_common(10):
print(f"{word}: {count}次")
generate_wordcloud(' '.join(words))
except FileNotFoundError:
print("错误: 未找到 yijudingyiwanyu.txt 文件")
except Exception as e:
print(f"分析出错: {e}")
if __name__ == "__main__":
analyze_yijudingyiwanyu()《一句顶一万句》示例文本:
3.
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import matplotlib
import platform
import os
# 设置中文字体
def set_chinese_font():
system = platform.system()
if system == 'Windows':
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统黑体
elif system == 'Darwin':
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # Mac系统
else: # Linux系统
plt.rcParams['font.sans-serif'] = ['Noto Sans CJK SC'] # 思源黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
set_chinese_font()
# 扩展停用词列表(包含常见虚词和标点符号)
STOPWORDS = set(['的', '了', '和', '是', '在', '我', '有', '他', '她', '这', '那',
'一个', '没有', '也', '都', '就', '说', '要', '会', '可以', '着',
'不', '人', '到', '来', '去', '又', '很', '看', '见', '自己',
'什么', '怎么', '这样', '那样', '时候', '知道', '这样', '那样'])
def analyze_author_style(texts, author_name):
"""分析作者写作风格"""
all_words = []
for text in texts:
words = jieba.lcut(text)
filtered_words = [word for word in words if len(word) > 1
and word not in STOPWORDS
and not word.isspace()
and not word.isdigit()]
all_words.extend(filtered_words)
word_counts = Counter(all_words)
return word_counts.most_common(15) # 返回前15个高频词
def plot_word_frequency(words_counts, title):
"""绘制词频统计图"""
words, counts = zip(*words_counts)
plt.figure(figsize=(12, 6))
bars = plt.bar(words, counts, color=['#FF9999' if '金庸' in title else '#66B2FF'])
# 添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height,
f'{height}',
ha='center', va='bottom')
plt.title(f"{title} (Top15)", fontsize=16)
plt.xlabel("词语", fontsize=12)
plt.ylabel("出现频次", fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.yticks(fontsize=10)
plt.grid(axis='y', alpha=0.5)
plt.tight_layout()
# 创建output文件夹保存图片
if not os.path.exists('output'):
os.makedirs('output')
plt.savefig(f'output/{title}.png', dpi=300, bbox_inches='tight')
plt.close() # 关闭图形避免内存泄漏
def compare_authors():
"""比较金庸和古龙的写作风格"""
# 示例文本(实际使用时替换为完整作品)
jinyong_texts = [
# 金庸作品节选1
"""郭靖和黄蓉走到大街上,只见人来人往,好不热闹。郭靖心想:"这襄阳城果然比大漠繁华得多。"
黄蓉笑道:"靖哥哥,咱们先去吃些点心可好?" 两人便来到一家酒楼,点了几个小菜。""",
# 金庸作品节选2
"""张无忌在光明顶上与六大派高手对峙,他运起九阳神功,周身泛起淡淡金光。
灭绝师太冷笑道:"魔教妖人,今日便是你的死期!" 张无忌不答,只是暗暗调息。""",
# 金庸作品节选3
"""令狐冲举起酒壶仰头痛饮,笑道:"人生得意须尽欢,莫使金樽空对月!"
任盈盈在一旁抿嘴微笑,眼中满是柔情。岳不群远远看见,眉头紧锁。"""
]
gulong_texts = [
# 古龙作品节选1
"""李寻欢坐在小酒馆的角落,手里把玩着一把飞刀。窗外雪花纷飞。
他突然叹了口气,喃喃道:"人生真是寂寞如雪。" 阿飞推门而入,带进一阵寒风。""",
# 古龙作品节选2
"""楚留香摸了摸鼻子,笑道:"姑娘何必如此紧张?在下不过是想借你的珍珠一观。"
那女子退后三步,厉声道:"盗帅楚留香,果然名不虚传!" 月光下,两人对峙。""",
# 古龙作品节选3
"""傅红雪拖着跛足走在长街上,右手紧握漆黑的刀。他的眼神比刀更冷。
突然,巷子里跳出三个黑衣人。傅红雪头也不抬:"让开。" 声音嘶哑如砂纸。"""
]
# 分析词频
jinyong_top = analyze_author_style(jinyong_texts, "金庸")
gulong_top = analyze_author_style(gulong_texts, "古龙")
# 可视化
plot_word_frequency(jinyong_top, "金庸作品高频词")
plot_word_frequency(gulong_top, "古龙作品高频词")
# 风格分析
jinyong_words = set([w for w, c in jinyong_top])
gulong_words = set([w for w, c in gulong_top])
print("\n=== 风格分析结果 ===")
print("\n【金庸特色词】:")
print(", ".join(jinyong_words - gulong_words))
print("\n【古龙特色词】:")
print(", ".join(gulong_words - jinyong_words))
print("\n【共同用词】:")
print(", ".join(jinyong_words & gulong_words))
print("\n=== 写作风格总结 ===")
print("金庸: 擅长描写具体动作(运起、笑道、来到)和场景细节(酒楼、金光、大漠)")
print("古龙: 多用抽象意象(寂寞、漆黑、突然)和感官描写(冷笑、嘶哑、砂纸)")
print("共同点: 都善用对话推进剧情(道、笑道、说)和动作描写")
if __name__ == "__main__":
print("正在分析作家风格...")
compare_authors()
print("\n分析完成!结果已保存到output文件夹")

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









