






今天给大家推荐一个能高效涨点、轻松发1区TOP的利器:即插即用多模态融合模块!
该模块能够无缝整合并即时应用多种模态(图像、文本、语音等)信息,使不同模态的数据,可以在无复杂配置或微调的情况下,被高效地融合和利用。克服了传统多模态融合方法需要大量参数调整和特征工程的缺陷,在提升模型的性能和适应性方面,举足轻重!比如模型IFM,性能直接飙升了42%;模型PMF在训练数据减少97%的同时,性能还远超SOTA!
此外,其由于特殊的内部设计,还能直接集成到现有的深度学习模型中,拿来即用,帮助我们快速验证,提高效率。
为方便大家把该方法落地到自己的文章里,早点发出顶会,我给大家准备了8个必备模块以及源码,一起来看!
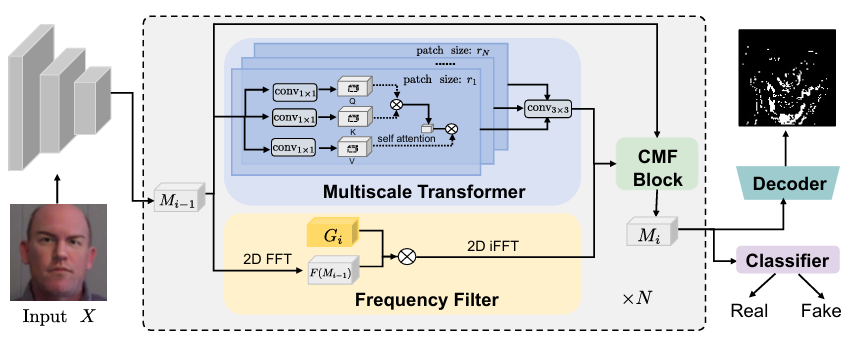
M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection
内容:文章介绍了一种名为M2TR的新型深度伪造(Deepfake)检测方法。M2TR通过在不同尺寸的图像块上操作,利用多模态多尺度来检测图像中不同空间层次的局部不一致性。此外,M2TR还通过精心设计的跨模态融合块在频率域中学习检测伪造痕迹,以补充RGB信息。
Efficient Multimodal Fusion via Interactive Prompting
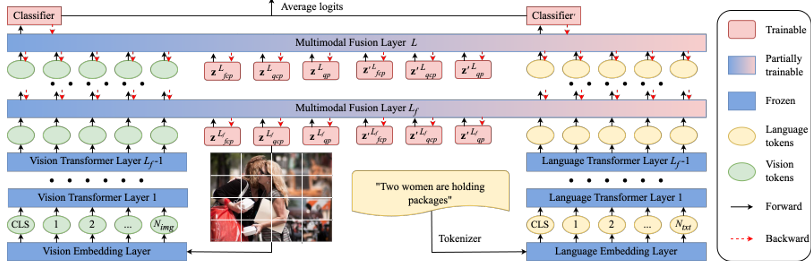
内容:文章提出了一种名为PMF的高效多模态融合方法,该方法专为融合单模态预训练而设计。PMF采用模块化的多模态融合框架,具有高度的灵活性,并促进不同模态之间的相互作用。
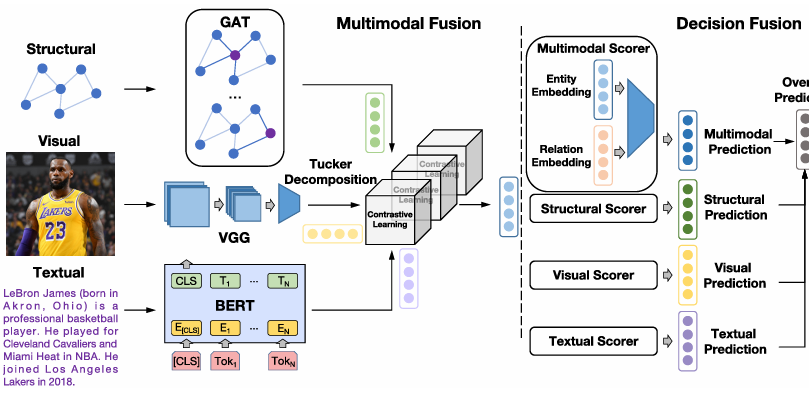
IMF: Interactive Multimodal Fusion Model for Link Prediction
内容:文章介绍了一种名为IMF的新型模型,用于知识图谱中的链接预测。IMF模型通过两阶段融合框架有效整合了不同模态的信息,包括结构化、视觉和文本特征,以提高预测潜在缺失三元组的准确性。该模型利用双线性融合机制和对比学习来充分捕获多模态特征之间的复杂交互,并在最终决策融合阶段综合考虑所有模态的预测结果。
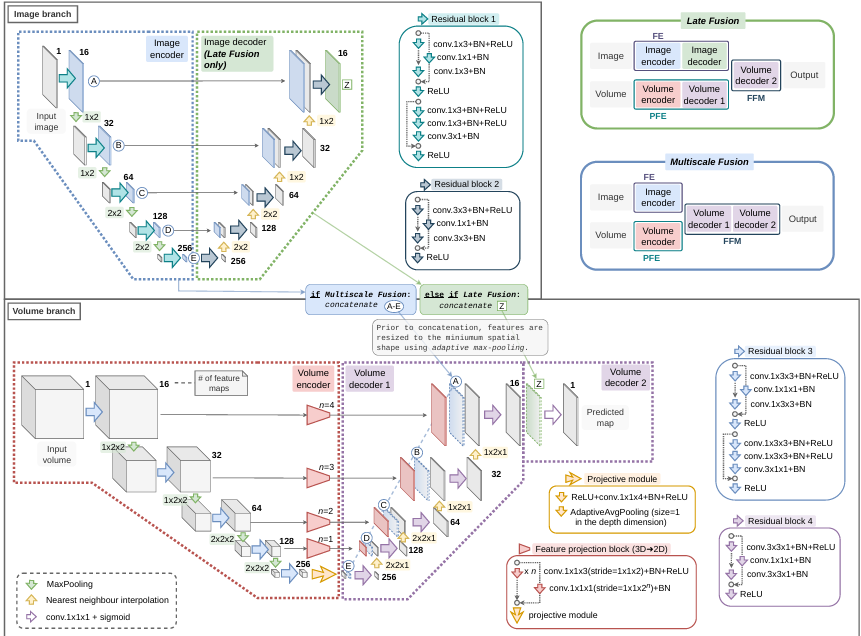
Deep Multimodal Fusion of Data with Heterogeneous Dimensionality via Projective Networks
内容:文章提出了一种新的深度学习框架,用于融合具有异构维度的多模态数据,特别是在医学成像领域。该框架通过将不同模态的特征投影到共同的特征子空间中,使得它们可以被融合并用于定位任务,如地理萎缩(GA)和视网膜血管(RBV)的分割。研究结果表明,与现有的单模态方法相比,所提出的方法在多模态视网膜成像的GA和RBV分割任务上表现出了显著的性能提升。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【即插多模】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









