






均值偏移
均值偏移是另一种基于质心的算法。在某些情况下,您会发现它的行为很像 k-means,但也存在一些显着差异。这些平均移位差异包括:
-
不需要预定数量的簇
-
为集群中心寻找密集区域
-
将稀疏区域视为噪声或异常值
均值偏移客户聚类器
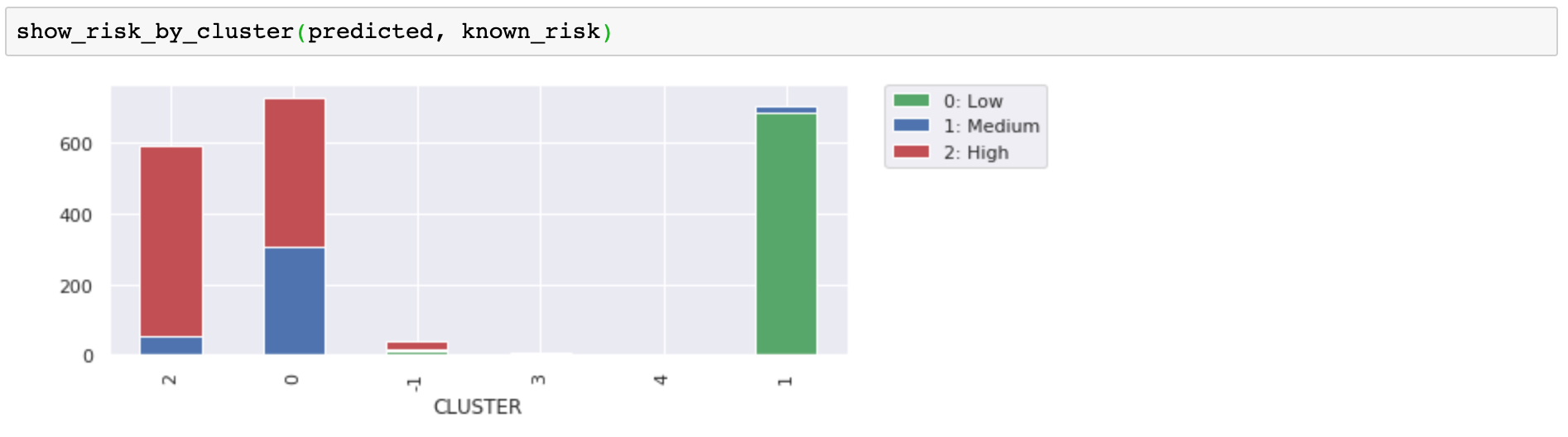
让我们看一下用均值偏移预测的客户集群。首先,请注意,我们不需要指定聚类的数量,算法选择了五个聚类。你不需要预先确定这一点,这真是太好了。没有强制数据进入 k 个集群,而是选择集群数量来匹配数据。
接下来,请注意,我们使用了非默认参数设置。这允许算法在稀疏区域中获取数据点,并将它们标记为孤立点(聚类-1)。在图表中,左侧和右侧的稀疏绿点是孤儿。动画 matplotlib 图表显示了分离孤立项如何使其余聚类更加清晰,并识别可能被视为异常的数据点。cluster_all=False
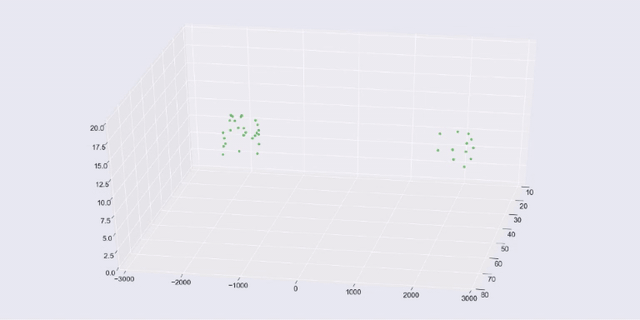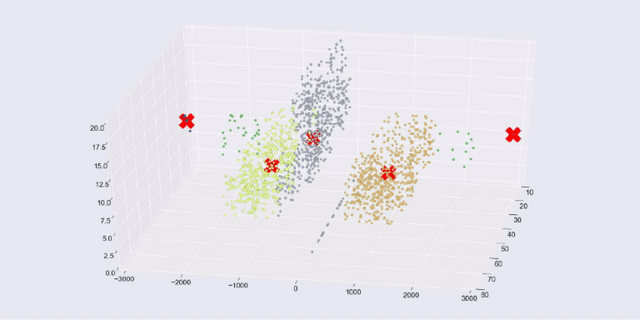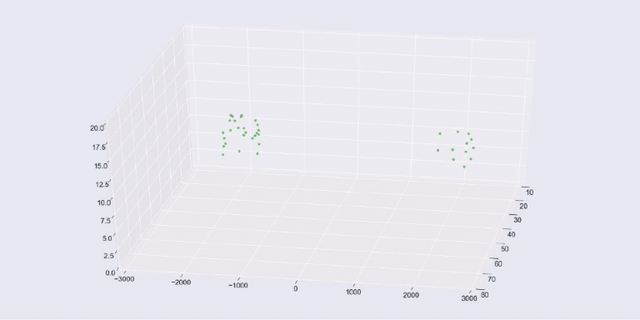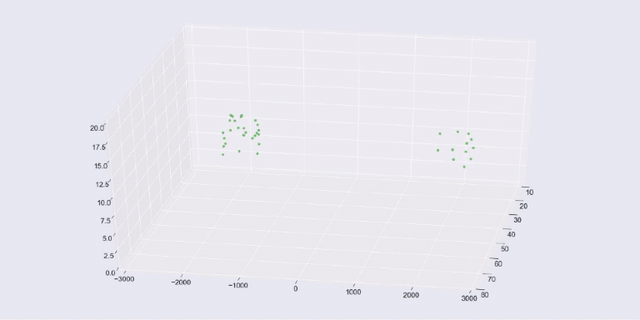
与风险标签相比,这些分组是否比我们原来的三个(来自 k 均值)更有用尚不清楚,但边缘上的孤立集群和迷你集群不太可能与更密集的集群客户保持一致,这是有道理的。将它们分开有助于澄清我们的分组。
平均位移卫星
因为均值偏移至少考虑了密度,你可能会认为它会比 k 均值更好地处理卫星数据集,但实际上,我们必须在它识别两个聚类之前对参数进行相当多的自定义。即便如此,你也会发现基于质心的方法并不能很好地将微笑与皱眉分开。请注意我们在设置中得到的孤儿的长尾巴。cluster_all=False
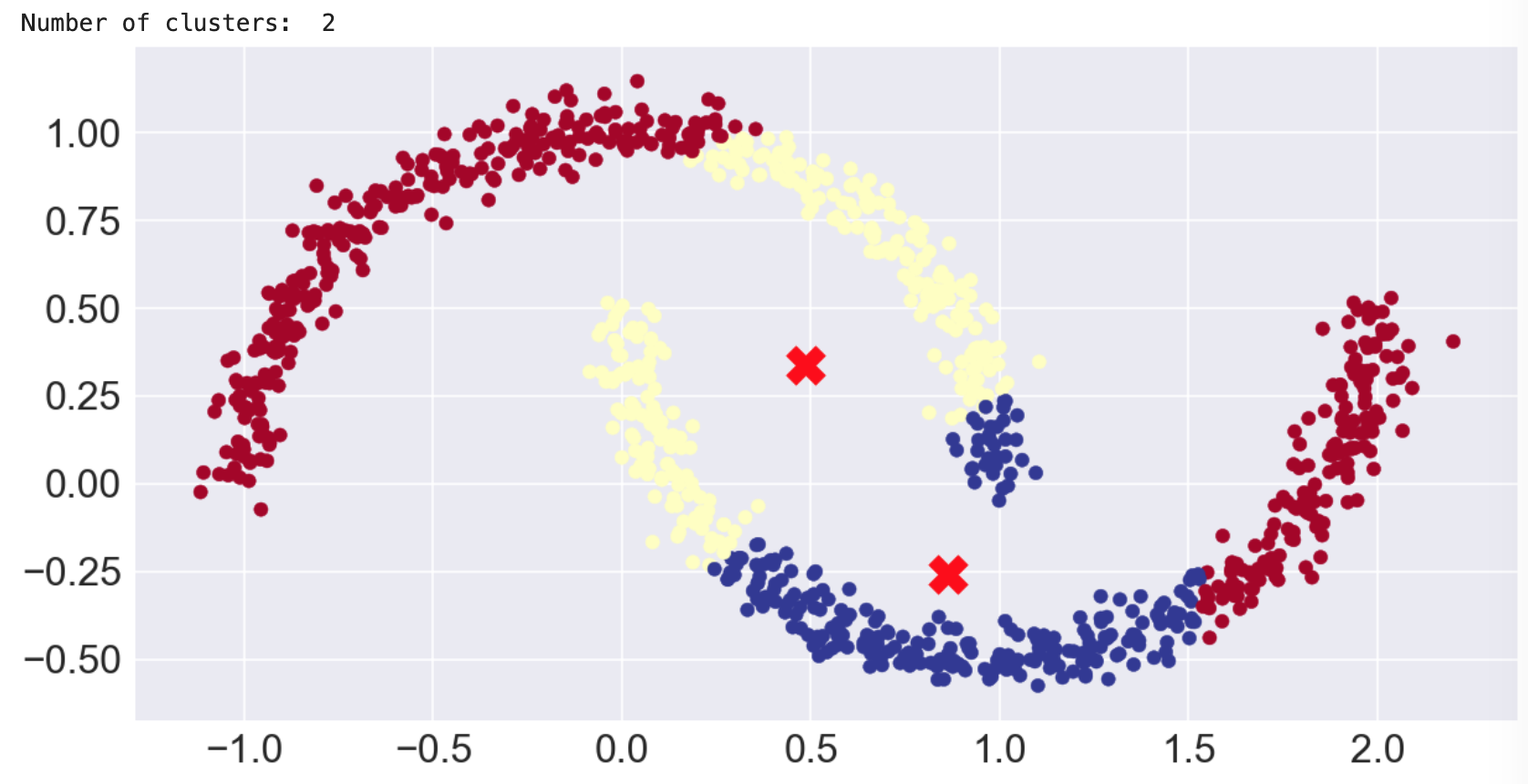
幸运的是,有基于密度的算法可以解决此类问题。
DBSCAN扫描
DBSCAN代表“基于密度的噪声应用空间聚类”。是的,这是一个很长的名字,谢天谢地,首字母缩略词。显然,DBSCAN是一种基于密度的算法。
DBSCAN卫星
让我们直接了解DBSCAN可以做些什么,而我们基于质心的算法无法做到。下图显示了DBSCAN如何将微笑与皱眉分开,并找到三个点标记为异常值。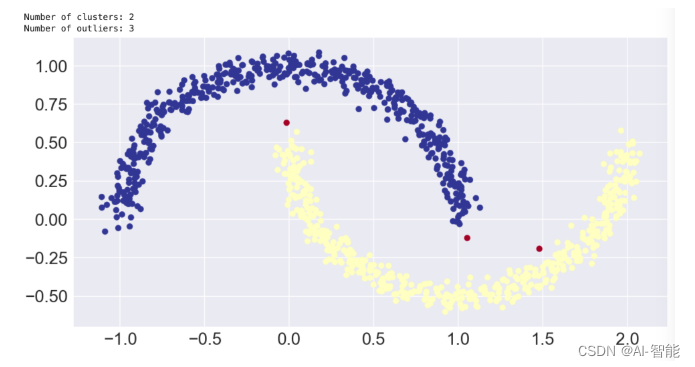
这个结果正是我们想要的!但是,需要注意的是,我们必须自定义参数才能获得所需的结果。DBSCAN使用密度来自动确定集群,但用于告诉它我们认为的“密集”。eps``eps
DBSCAN是如何工作的?
DBSCAN 的工作原理是将聚类定义为最大密度连接点集。考虑了两个参数,(epsilon) 和 。Epsilon 是邻域的最大半径,最小样本是 epsilon 邻域中用于定义聚类的最小点数。eps``minimum_samples
点分为三种分类:核心点、边界点和异常值。核心点在其 epsilon 邻域(包括其自身)内至少有最少的样本。这些是位于聚类内部的点。边界点在其 epsilon 邻域内的点数少于最小点,但聚类可以到达该边界点。也就是说,它位于核心点的附近。最后,异常值或噪声点是聚类无法到达的点。
DBSCAN的优势
DBSCAN的优点包括:
-
自动确定簇数
-
识别异常值(噪声)
-
不限于球形团簇
DBSCAN客户集群器无噪音
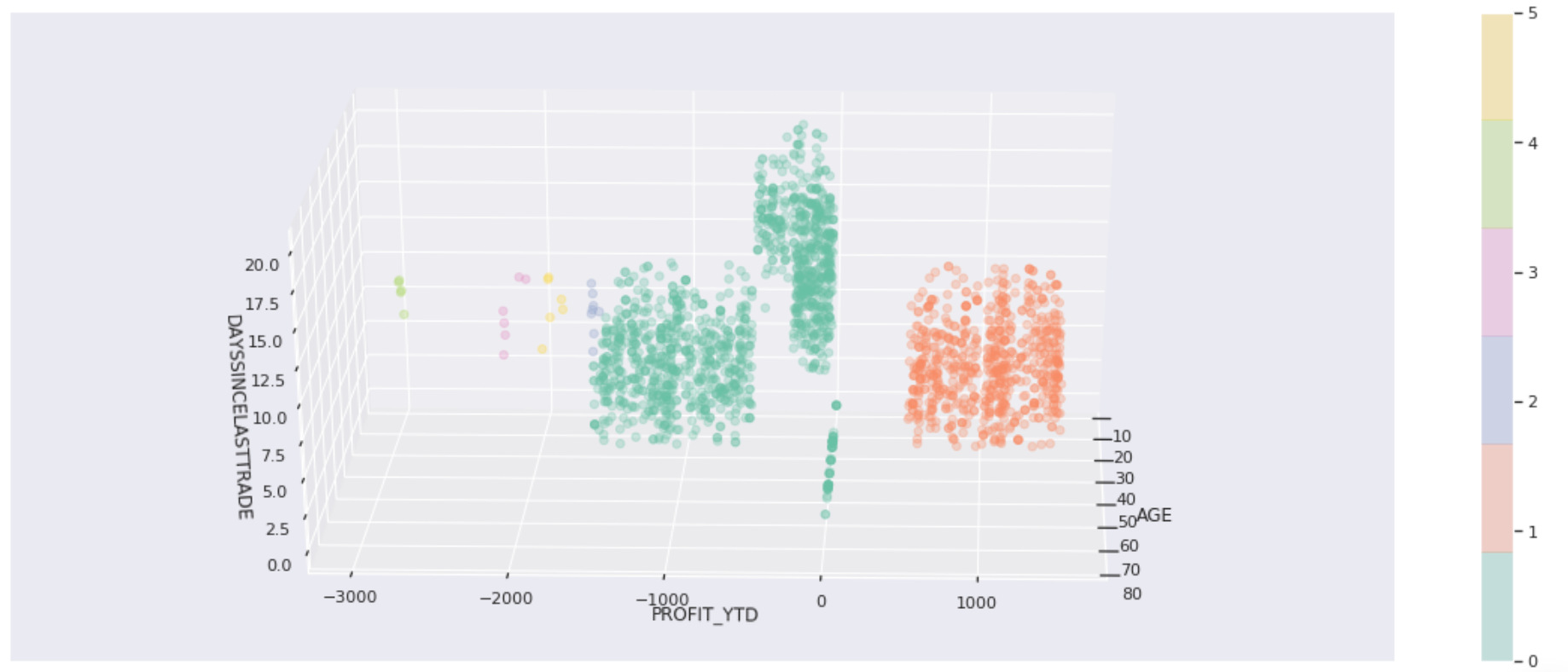
在我们的笔记本中,我们还使用 DBSCAN 来消除噪音并获得客户数据集的不同聚类。
分层聚类
分层聚类知道两个方向或两种方法。一种是自下而上的,另一种是自上而下的。对于自下而上,每个点都从单个聚类开始。接下来,将两个最近的聚类连接起来,形成一个两点聚类。该过程将继续合并最近的聚类,直到您拥有包含所有点的单个聚类。自上而下恰恰相反。它从包含所有点的单个聚类开始,然后划分,直到每个聚类都是一个单独的点。
无论哪种方式,分层聚类都会为 n 个数据点生成聚类可能性树。获得树后,您可以选择一个级别来获取集群。
团聚聚类
在我们的笔记本中,我们使用 scikit-learn 的集聚聚类实现。集聚聚类是一种自下而上的分层聚类算法。要选择将成为“答案”的级别,请使用 or 参数。我们想避免选择(因为我们不喜欢在 k-means 中这样做),但后来我们不得不调整,直到我们得到一些我们喜欢的集群。您可以通过调整参数来显着更改结果。n_clusters``distance_threshold``n_clusters``distance_threshold
关于聚集聚类的一个有趣的事情是,你可以得到不同的聚类大小。我们使用团聚聚类的客户数据演示很有趣,因为我们最终得到了 14 个不同形状和大小的聚类。
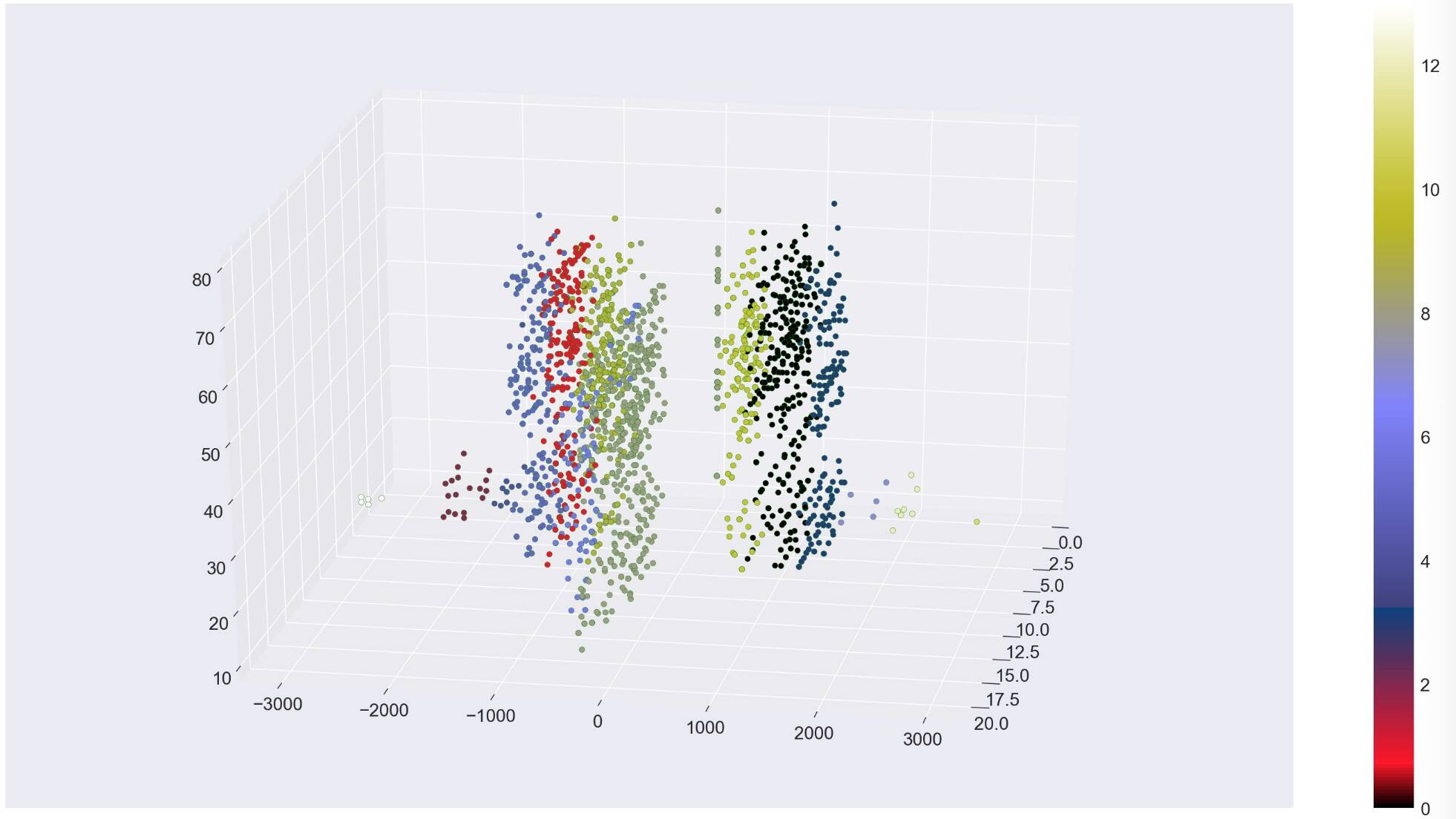
再一次,我们看到这很好地将我们的低风险客户与高风险客户区分开来。更多的集群数量似乎是不必要的,但确实有助于在我们的客户分组中进行更精细的区分。最小的集群看起来不那么重要,但它们有助于阐明其他客户分组。

使用案例
本节为您提供一些无监督学习的用例。
推荐人
聚类客户可用于构建推荐器,这些推荐器可以:
-
提供客户可能喜欢的优惠券
-
推荐客户应该喜欢的电影
-
将客户识别为高风险
发现隐藏的特征
在分析并发现聚类表现出特定行为后,可以使用它们来标注数据,就像您具有其他属性或要素一样。我们有一些带有流失风险标签的数据,但在我们选择最佳算法后,我们可以开始将所有客户标记为:低风险、高风险或中/高风险。
另一个很好的例子是使用电影推荐集群,然后继续将某人标记为浪漫喜剧迷。
隐藏的特征思想是,在你了解了群体的行为之后,你就有了新的属性来推断个人。它们不是观察到的属性,而是预测或推断的。它们仍然可以以大致相同的方式使用(即,输入到监督学习中),但只有一定的准确性概率。
请注意,我们不是在谈论给人贴标签。我们正在分析数据点。有时,它们恰好是关于人的。接下来的例子更好。
异常检测
我们试图指出识别异常值的好处,因为去除噪声有助于澄清聚类,而异常检测是一个很好的用例
正如我们所演示的,您可以使用聚类来识别异常值或异常。此策略可用于识别应进一步调查的异常行为,例如:
-
不寻常的购买(信用卡欺诈)
-
异常网络流量(拒绝服务攻击)
计算机视觉
聚类算法用于图像分割、对象跟踪和图像分类。聚类算法使用像素属性作为数据点,有助于识别形状和纹理,并将图像转换为可以通过计算机视觉识别的对象。
总结
赔钱的客户比盈利的客户更有可能离开。当然,每个人都已经知道了。这只是一个例子。那么,我们真正学到了什么?希望您尝试了代码并获得了以下方面的实践经验:
-
Watson 工作室
-
Jupyter 笔记本
-
蟒
-
scikit-learn 聚类
-
scikit-learn 数据集
-
绘图交互式图表
-
带有 seaborn 的 matplotlib
-
动画 matplotlib
-
pandas 数据帧
更具体地说,关于聚类分析,您了解了三种不同的方法:
-
基于质心的聚类
-
基于密度的聚类
-
分层聚类
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓

















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









