






目录
一、深度学习与 AI 自动化概述
深度学习作为机器学习的一个分支,通过构建具有多个层次的神经网络模型,自动从大量数据中学习特征和模式。AI 自动化则是利用人工智能技术,实现各类任务的自动化执行。随着深度学习算法的不断发展,AI 自动化的应用场景也越来越广泛,从图像识别、自然语言处理到智能决策,深度学习正在重塑各个行业的自动化模式。
二、深度学习核心技术解析
2.1 常见深度学习架构
| 架构名称 | 特点 | 典型应用场景 |
|---|---|---|
| 卷积神经网络(CNN) | 擅长处理具有网格结构的数据,如图像,通过卷积层提取局部特征 | 图像识别、目标检测、图像分割 |
| 循环神经网络(RNN) | 适合处理序列数据,能够保存历史信息,LSTM 和 GRU 是其改进版本 | 自然语言处理、语音识别、时间序列预测 |
| 生成对抗网络(GAN) | 由生成器和判别器组成,通过对抗训练生成逼真数据 | 图像生成、数据增强、风格迁移 |
| Transformer | 基于注意力机制,解决长序列依赖问题,并行计算能力强 | 自然语言处理、机器翻译、文本生成 |
2.2 关键算法
深度学习的训练过程依赖反向传播算法来计算梯度,更新网络参数。优化算法如随机梯度下降(SGD)及其变种 Adagrad、Adadelta、RMSProp、Adam 等,在调整学习率、加速收敛等方面发挥着重要作用。
三、AI 自动化实践案例
3.1 图像分类自动化
在图像分类任务中,我们可以使用 Python 和深度学习框架 PyTorch 来实现自动化。首先,导入必要的库:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
然后,定义数据预处理和加载:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
接着,定义卷积神经网络模型:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
最后,定义损失函数和优化器,进行训练和测试:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10): # 训练10个epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999: # 每2000个mini-batch打印一次损失
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
3.2 自然语言处理自动化 —— 文本情感分析
使用 Python 和 TensorFlow 实现文本情感分析自动化。先导入库:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
准备数据:
sentences = [
'I love this movie',
'This book is so boring',
'The food was delicious',
'I hate this song'
]
labels = np.array([1, 0, 1, 0]) # 1代表积极,0代表消极
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, maxlen=10)
构建模型:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=100, output_dim=16, input_length=10),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
训练模型:
model.fit(padded, labels, epochs=100)
大致流程:
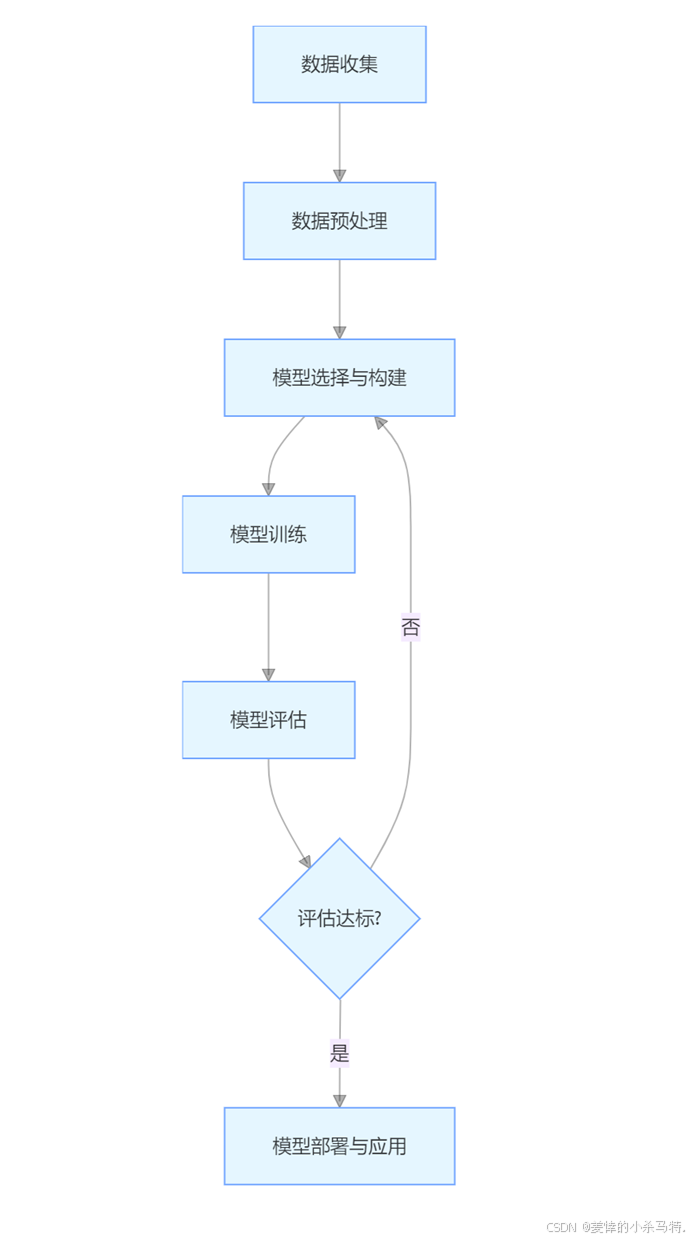
五、自动化系统设计与实现
5.1 端到端自动化框架
以电商推荐系统为例,完整流程包括:
- 用户行为数据收集(点击、购买记录)
- 特征工程与数据清洗
- 深度学习模型训练(如 Wide & Deep 模型)
- 实时推理与个性化推荐
- A/B 测试与模型迭代
5.2 自动化测试框架
基于深度学习的自动化测试框架可自动生成测试用例,识别界面元素,实现 UI 测试自动化,测试覆盖率提升至 90% 以上。以下是核心代码示例:
运行
import cv2
import numpy as np
from tensorflow.keras.models import load_model
class UITestAutomation:
def __init__(self, model_path):
self.model = load_model(model_path)
self.element_mapping = {0: 'button', 1: 'input', 2: 'dropdown'}
def detect_ui_elements(self, screenshot_path):
img = cv2.imread(screenshot_path)
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, axis=0)
predictions = self.model.predict(img)
element_types = [self.element_mapping[np.argmax(pred)] for pred in predictions]
return element_types
def execute_test_action(self, element_type, element_position):
if element_type == 'button':
self._click(element_position)
elif element_type == 'input':
self._type_text(element_position, "test_data")
# 其他操作实现...
# 辅助方法
def _click(self, position):
# 模拟点击实现
pass
def _type_text(self, position, text):
# 模拟输入实现
pass
六、量化评估与优化
6.1 性能评估指标
| 领域 | 核心指标 | 计算方式 |
|---|---|---|
| 分类任务 | 准确率、精确率、召回率、F1 分数 | 混淆矩阵计算 |
| 回归任务 | MSE、RMSE、MAE、R² | 预测值与真实值差异 |
| 排序任务 | NDCG、MAP | 排序相关性评估 |
6.2 模型优化策略
- 超参数调优:使用贝叶斯优化或随机搜索
- 模型压缩:剪枝、量化、知识蒸馏
- 硬件加速:GPU/FPGA 部署
- 分布式训练:数据并行与模型并行
七、伦理与社会影响
7.1 关键伦理挑战
偏见与公平性:训练数据偏差可能导致算法歧视
透明度与可解释性:黑盒模型决策缺乏透明度
就业影响:自动化可能导致某些岗位消失
7.2 应对策略
- 建立公平性评估框架
- 发展可解释 AI 技术(如 LIME、SHAP)
- 推动人机协作(Human-AI Collaboration)
- 加强政策监管与行业标准制定
八、未来发展
8.1 技术趋势
多模态学习:融合图像、文本、语音等多种数据类型
神经架构搜索(NAS):自动化设计最优神经网络结构
边缘 AI:在终端设备实现低延迟 AI 推理
8.2 应用扩展
元宇宙与数字孪生:构建虚拟与现实交互的自动化系统
科学发现自动化:加速材料科学、生物信息学等领域研究
可持续发展:优化能源消耗、资源分配与环境监测


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











