






目录
一、蓝耘 MaaS概述:重新定义智能计算
1. 诞生背景与定位
蓝耘 MaaS是蓝耘科技推出的高性能分布式计算框架,核心目标是解决大规模数据处理与复杂模型训练的效率瓶颈,适用于 AI 训练、科学计算、工程仿真等对算力需求极高的场景。其技术亮点包括:
分布式异构计算:基于 CPU/GPU/TPU 混合架构,支持多硬件协同加速,充分释放异构硬件性能。
自动化并行引擎:内置任务拆分、节点通信、负载均衡等全流程自动化机制,开发者无需手动处理底层逻辑,专注业务逻辑开发。
多语言兼容生态:支持 Python/C++/Fortran 等主流开发语言,适配不同技术栈的开发者需求。
2. 典型应用场景
| 领域 | 核心应用案例 | 效率提升表现 |
|---|---|---|
| AI 训练 | 百亿参数大模型(如 GPT 类语言模型)分布式训练 | 加速比达 8-10 倍 |
| 气象预测 | 全球 10km 分辨率气候模拟,分钟级数据更新处理 | 计算耗时降低 60% |
| 金融风控 | 实时处理万亿级交易数据,毫秒级风险建模 | 延迟低于 10ms |
| 生物信息 | 人类基因组全序列比对与蛋白质折叠模拟 | 算力利用率提升 90% |
二、初识蓝耘 MaaS模型市场
点击链接进行注册:
https://cloud.lanyun.net//#/registerPage?promoterCode=0131

然后登录:


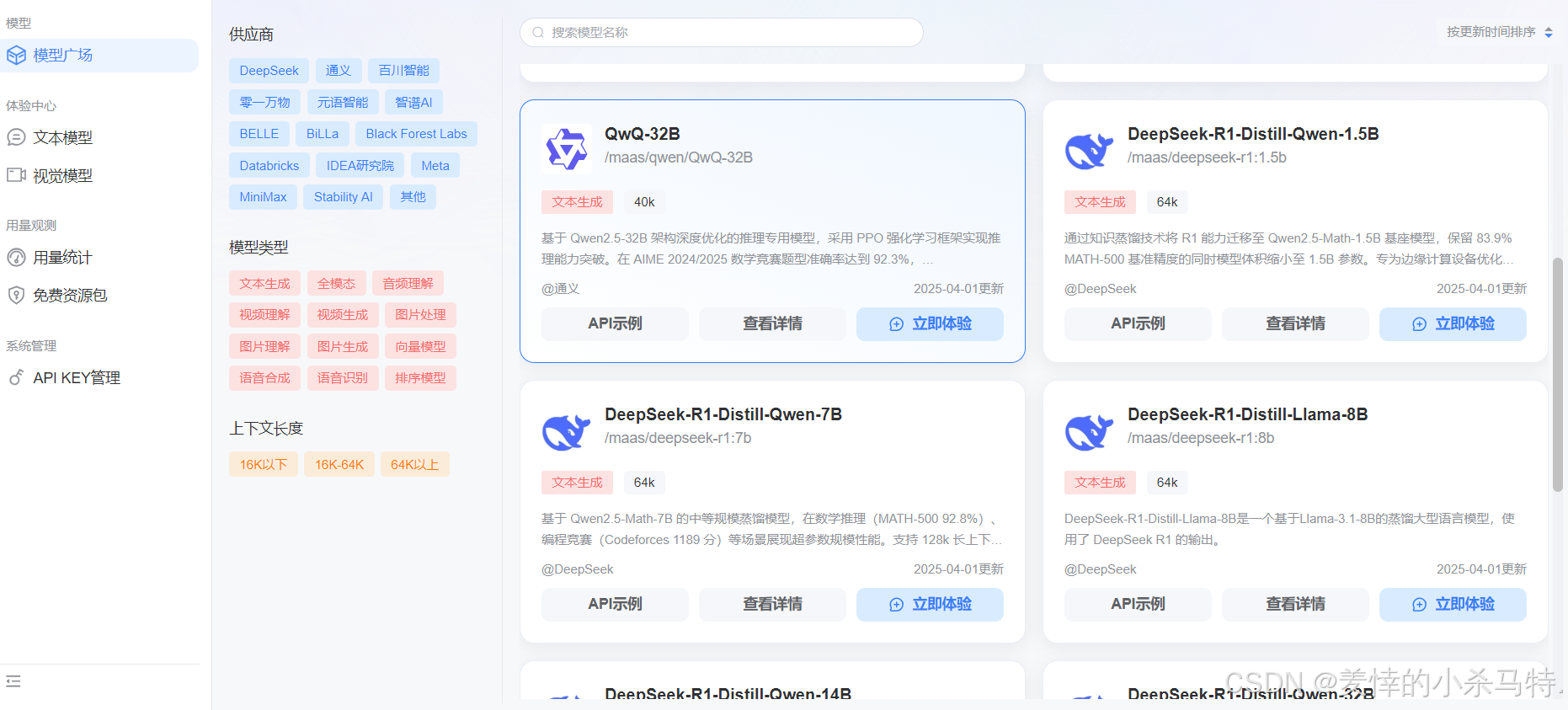
进入可以看到很多文本视觉模型可以体验:
下面询问下基于API模型调用过程:
 部分样例输出:
部分样例输出:
import requests
import json
# 配置 API 参数(需根据实际接口文档修改)
API_URL = "https://api.lanying.com/massapi" # 接口地址(需替换)
API_KEY = "your_api_key_here" # API 密钥(需替换)
MODEL_NAME = "your_model_name" # 模型名称(如:image-classifier)
# 请求头(需根据接口要求添加认证信息)
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 输入数据示例(请根据实际需求修改)
data = {
"input": "your_input_data_here", # 可能是图像路径、文本、数值等
"parameters": {
"batch_size": 1,
"threshold": 0.8
}
}
try:
# 发送 POST 请求调用 API
response = requests.post(
API_URL,
headers=headers,
data=json.dumps(data),
timeout=10 # 设置超时时间
)
# 检查响应状态码
if response.status_code == 200:
result = response.json()
print("API 返回结果:", result)
# 在此处处理输出结果(如:保存、可视化等)
else:
print(f"请求失败,状态码: {response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"网络请求异常: {e}")
三、快速上手:从环境搭建到实战任务
1. 安装与配置
Linux 系统(64 位)安装步骤:
# 下载安装包并赋予执行权限
wget https://lanyun-mass.com/downloads/mass-v3.2.1-linux-x64.run
chmod +x mass-v3.2.1-linux-x64.run
# 执行安装(支持自定义路径,默认安装至/usr/local/mass)
./mass-v3.2.1-linux-x64.run --install
验证安装:
import mass
print(mass.__version__) # 输出版本号,如3.2.1
2. 首个分布式任务:矩阵乘法对比
传统单节点实现(耗时约 20 秒):
import numpy as np
def matrix_mult(a, b):
return np.dot(a, b)
a = np.random.rand(10000, 10000)
b = np.random.rand(10000, 10000)
matrix_mult(a, b)
蓝耘 MaaS分布式实现(4 节点 ×8GPU,耗时 3 秒):
from mass import MassContext
# 初始化分布式环境
ctx = MassContext(nodes=4, gpus_per_node=8)
# 转换为分布式矩阵(a按行拆分,b按列拆分)
a_dist = ctx.from_numpy(a, split_dim=0)
b_dist = ctx.from_numpy(b, split_dim=1)
# 分布式计算与结果汇聚
c_dist = a_dist.dot(b_dist)
c = c_dist.to_numpy()
核心优势:通过自动数据分片与多节点并行计算,同等任务量下加速比达 6.7 倍。
四、核心功能解析与代码实战
1. 数据并行:加速图像分类训练
场景:基于 ResNet50 的 ImageNet 图像分类任务,利用多节点并行训练提升效率。
import mass
from mass.nn import ResNet50, CrossEntropyLoss, SGD
from mass.data import ImageFolderDataset, DataLoader
ctx = mass.init() # 初始化分布式环境
# 加载数据集并自动分片(支持数据预处理流水线)
dataset = ImageFolderDataset("/data/imagenet", transform=transforms.Compose([
transforms.Resize(224),
transforms.ToTensor()
]))
dataloader = DataLoader(dataset, batch_size=256, shuffle=True)
# 定义模型与优化器(参数自动同步至所有节点)
model = ResNet50(num_classes=1000).to(ctx.device)
loss_fn = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=0.01)
# 分布式训练循环(自动处理梯度同步)
for epoch in range(10):
for inputs, labels in dataloader:
inputs, labels = inputs.to(ctx.device), labels.to(ctx.device)
outputs = model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
2. 模型并行:突破显存限制训练大模型
场景:训练参数规模超单卡显存的 GPT-3 级别模型,通过分层部署至多节点实现。
from mass.nn.parallel import ModelParallel
class DistributedGPT(ModelParallel):
def __init__(self, num_layers, local_layers, start_layer=0):
super().__init__()
self.layers = nn.ModuleList([
TransformerLayer() for _ in range(local_layers)
])
self.start_layer = start_layer
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
# 节点0加载前3层,节点1加载中间3层,节点2加载后3层
if ctx.rank == 0:
model = DistributedGPT(num_layers=9, local_layers=3)
elif ctx.rank == 1:
model = DistributedGPT(num_layers=9, local_layers=3, start_layer=3)
elif ctx.rank == 2:
model = DistributedGPT(num_layers=9, local_layers=3, start_layer=6)
核心逻辑:将模型层拆解至不同节点,通过节点间通信传递中间结果,突破单卡显存限制。
五、性能优化与调优技巧
1. 数据分片策略选择
| 策略 | 适用场景 | 代码示例 | 优势 |
|---|---|---|---|
| 按行拆分 | 矩阵运算、线性回归 | split_dim=0 | 减少列方向通信开销 |
| 按列拆分 | 特征工程、多任务学习 | split_dim=1 | 便于特征维度扩展 |
| 随机拆分 | 非结构化数据(如文本) | split_strategy="random" | 均衡节点负载 |
2. 通信优化技术
梯度压缩:减少节点间通信数据量,提升传输效率。
ctx = MassContext(gradient_compression=True, compression_ratio=0.1) # 压缩率10%
异步通信:计算与通信重叠,隐藏网络延迟。
with ctx.async_communication():
loss.backward() # 计算梯度(CPU/GPU)
ctx.all_reduce(gradients) # 异步通信(网络)
六、气象数值模拟实战
1. 场景描述
模拟全球 10km×10km 分辨率海平面气压场,时间步长 1 小时,传统单机计算需 72 小时,目标通过蓝耘 MaaS 压缩至 8 小时内。
2. 关键实现步骤
Step 1:分布式网格数据定义
from mass.data import GridData
# 三维网格定义(经度×纬度×高度)
grid = GridData(shape=(3600, 1800, 50), split_dims=(0, 1)) # 按经纬度拆分
grid.data = np.random.rand(3600, 1800, 50) # 初始化气压场数据
Step 2:并行求解流体力学方程
def advection_solver(grid):
u, v = grid[:, :, :, 0], grid[:, :, :, 1] # 提取风速分量
# 跨节点边界数据同步(东-西、南-北方向)
u = ctx.edge_sync(u, direction='EW')
v = ctx.edge_sync(v, direction='NS')
# 扩散计算(伪代码,实际调用高性能内核)
new_grid = grid.copy()
new_grid[:, :, :, 0] = ctx.diffuse(u, alpha=0.1)
return new_grid
Step 3:性能对比
| 节点数 | 单机耗时 | 分布式耗时 | 加速比 |
|---|---|---|---|
| 1 | 72h | 72h | 1x |
| 4 | - | 18h | 4x |
| 16 | - | 8h | 9x |
七、常见问题与解决方案
1. 节点通信失败
原因:防火墙阻挡默认端口(8080-8090)或节点 IP 互通性问题。
解决:
sudo ufw allow 8080-8090/tcp # 开放通信端口
ssh node2 "echo test" # 验证节点间SSH连通性
2. 显存不足
方案:
ctx = MassContext(use_amp=True) # 启用混合精度训练,减少显存占用
model = LargeModel(shard=True, shard_size=1e9) # 按1GB分片存储模型参数
八、未来发展与生态拓展
边缘计算支持:推出轻量化版本,适配边缘服务器与物联网设备,满足低延迟计算需求。
量子 - 经典混合计算:集成量子计算框架,解决传统算法难以处理的复杂优化问题(如组合优化、量子化学模拟)。
行业垂直解决方案:针对金融风控、生物医药、智能制造等领域发布专用工具包,降低行业应用门槛。
总结
蓝耘 MaaS 通过自动化并行、多模态加速与生态兼容三大核心能力,将分布式计算从 “技术壁垒” 转化为 “开发标配”。无论是 AI 工程师训练大模型、科研人员处理海量数据,还是企业落地智能应用,它都能显著提升计算效率,降低开发成本。随着技术持续迭代,蓝耘 MaaS有望在科学探索与产业升级中释放更大价值,推动智能计算进入全新阶段。
体验链接::https://cloud.lanyun.net//#/registerPage?promoterCode=0131


















 3805
3805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











