






自注意力机制
一、注意力机制 参考文章注意力机制综述
自注意力机制总的来说就是Q、K、V三个矩阵(共享)。Q计算当前单词与其他单词间的关联。K和Q进行匹配,是单词的关键信息。V是单词重要特征。(x是输入)
算x1与x2,x3,x4的关联:
q1与k2,k3,k4匹配计算。
𝑑 表示 𝑞 和 𝑘 的矩阵维度,在 Self-Attention 中, 𝑞 和 𝑘 的维度是一样的。这里除以 𝑑 的原因是防𝑞 和 𝑘的点乘结果较大。
再经过softmax得到。
最后将 𝑞,𝑘 操作后得到的 ,
,
,
和 𝑣1,𝑣2,𝑣3,𝑣4 分别相乘。
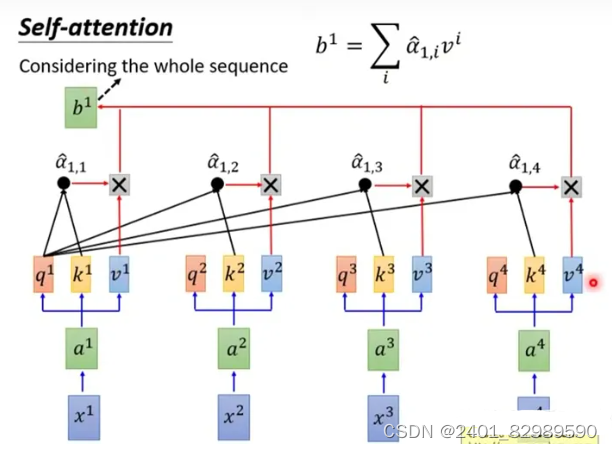
对应的,
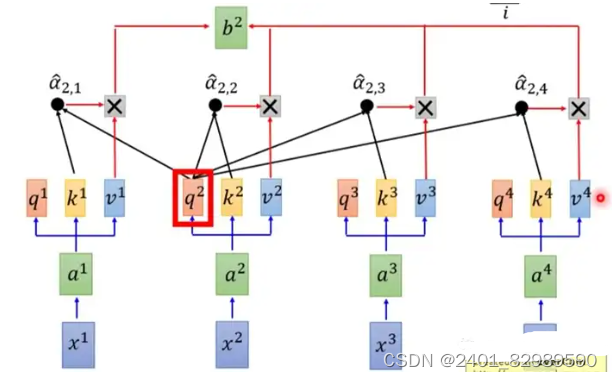
所以,自注意力机制通过计算序列中不同位置之间的相关性( 𝑞,𝑘 操作),为每个位置分配一个权重,然后对序列进行加权求和( 𝑣 操作)。
二、多头自注意力机制通过使用多个独立的注意力头,分别计算注意力权重,并将它们的结果进行拼接或加权求和。
在乘以一个 𝑞,𝑘,𝑣 后,会再分配多个 𝑞,𝑘,𝑣
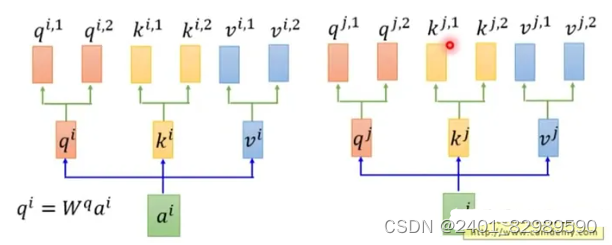
就是x1先乘q矩阵,。然后多分配两个头
,
。K,V同样操作。
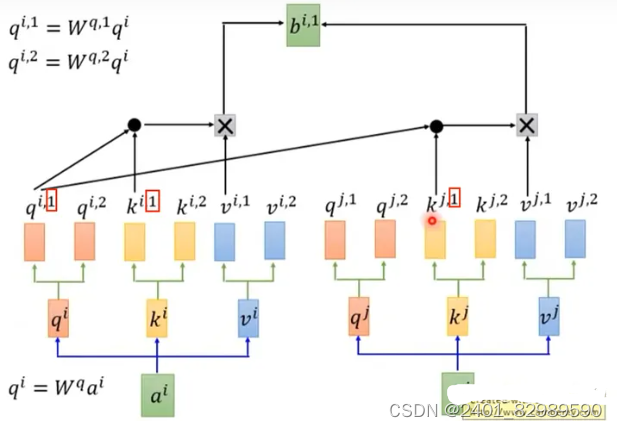
接着 𝑞 和 𝑘 的点乘操作,在多头注意力机制中,有多个𝑞 和 𝑘。 𝑞𝑖,1 会和 𝑘𝑖,1 和 𝑘𝑗,1 进行点乘,再进行 softmax 操作。
三、通道注意力机制(SENet模型),对每个维度(通道)进行全局平均池化,缩成一个标量值。H*W*C的隐藏层(C是维度)就变成了1*1*C,再经过激活函数就得到了每层的权重,最后将权重与原本隐藏层点乘,得到加权后的隐藏层。
resnet残差神经网络
深的神经网络非常难以训练,太深会导致梯度消失或者梯度爆炸,解决方法可以是最初的参数就设置的较好(权重随机初始化时不要太大也不要太小),还有就是中间加入一些正则化,比如batch normalization。虽然这样做使得深的网络可以训练收敛了,但效果不好。但效果不好并不是因为层数过多而导致,而是误差累积。这不是overfitting过拟合,overfitting是训练误差低但测试误差高,这里隐藏层过深是训练误差和测试误差都很差。
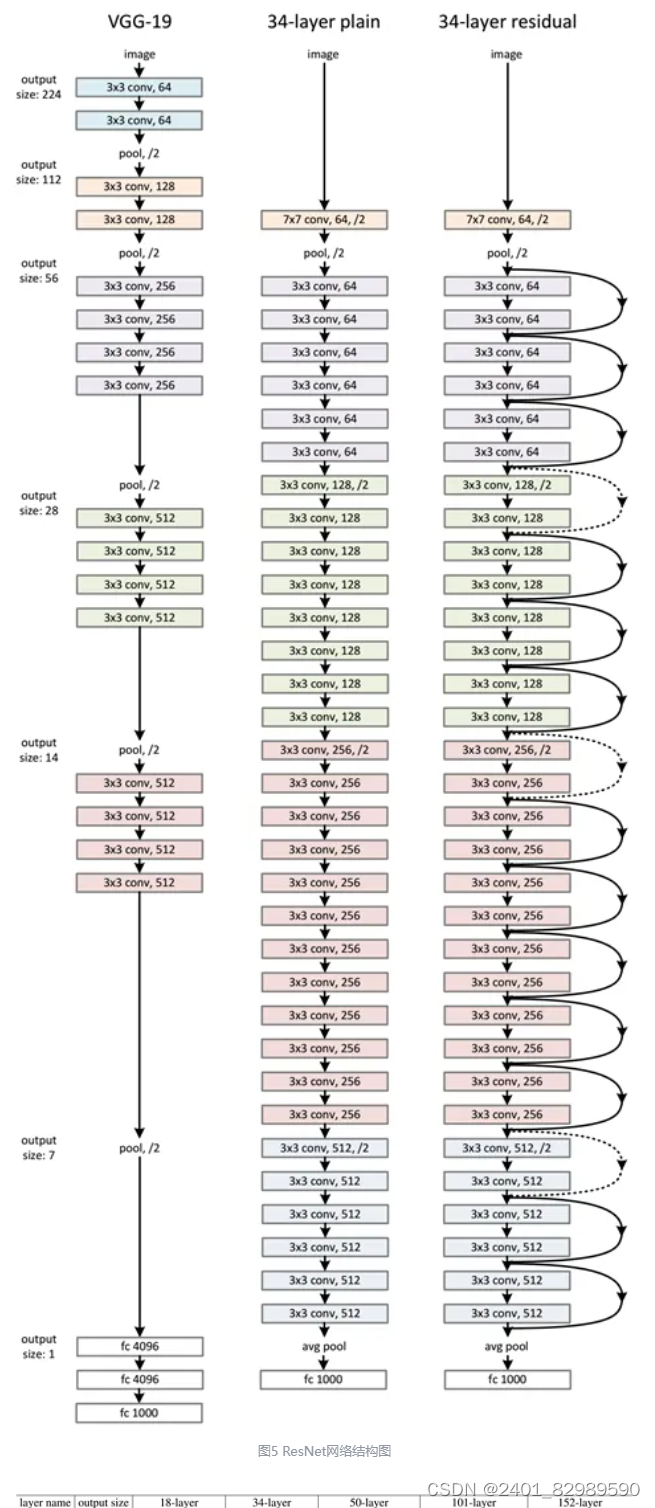
若较浅的网络就有好的结果,那加深网络后应该效果更好(设置权重使输入和输出一一对应),但实际做不到。所以提出了残差,某隐藏层a输出为H(x),其接着的下一个隐藏层b的输入并不是a的输出H(x),而是H(x)-x (学到的东西和真实的东西的残差)。最后b的输出为F(x)=F(H(x)-x ),还要再加上原来的x,F(x)+x。
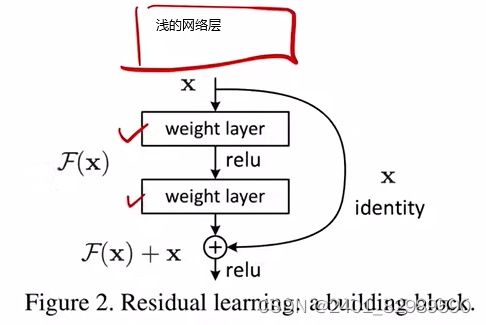
不同深度resnet
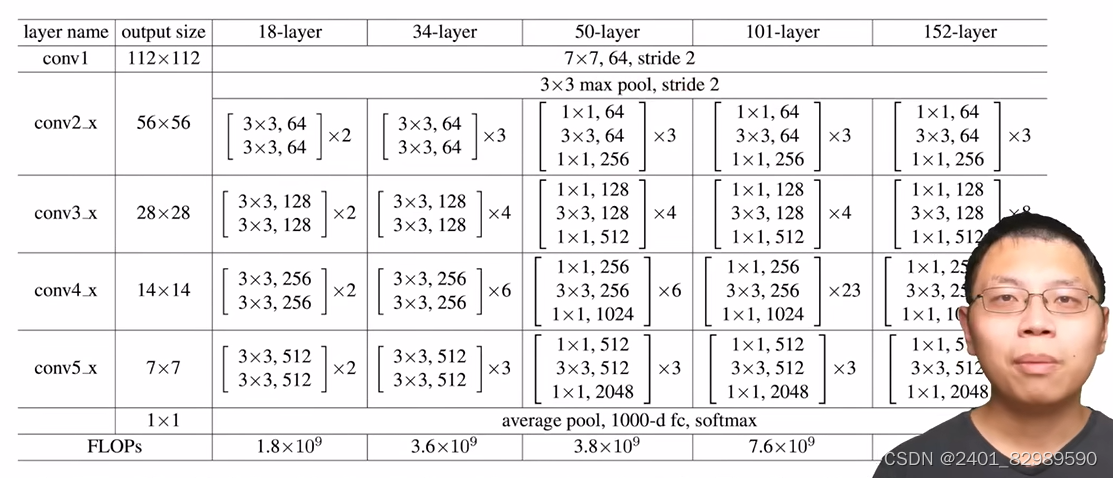
不同残差单元:
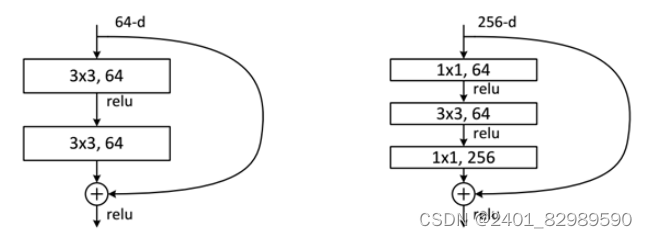
对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。
batch norm 和 layer norm
在神经网络的每一层中对输入进行归一化处理。BN批量标准化通过对每个小批次的数据进行均值和方差的归一化处理,使得网络中的每一层都有类似的数据分布。这有助于避免由于不同层数据分布不一致而导致的梯度消失或梯度爆炸问题。BN还引入了可学习的参数(缩放因子和偏移量),这些参数可以调整归一化后的数据分布,从而进一步降低梯度消失或梯度爆炸的风险。这些参数的存在使得网络可以自适应地调整数据的范围,有助于更稳定地训练模型。
mini-batch:将数据集分成若干个小的批次,每次从数据集中随机选择一个批次用于训练。这样,我们可以将整个数据集分成多个小批次依次进行训练。
迭代(Iteration)指的是一次参数更新的过程。在训练过程中,每次将一个批次(batch)的数据输入到模型中进行前向传播和反向传播,然后根据计算得到的梯度更新模型的参数,这个过程称为一次迭代。
周期(Epoch)指的是将整个训练数据集完整地通过模型进行一次训练的过程。即,将所有训练样本都输入到模型中进行了一次前向传播和反向传播,然后更新模型参数的过程称为一个周期。
LN 层标准化是对每一层的所有特征(神经元)进行归一化处理,计算每个特征在每个样本上的均值和方差,然后对该层的所有特征进行归一化。
- BN 是对每一层的每个特征进行归一化,依赖于batch的统计信息,因此在训练时需要考虑mini-batch的大小,而 LN 则是对每一层的所有特征进行归一化,不依赖于batch的统计信息,因此在训练和推断时的行为保持一致。
- BN 在处理卷积神经网络(CNN)时更常用,而 LN 在处理递归神经网络(RNN)时更常用。
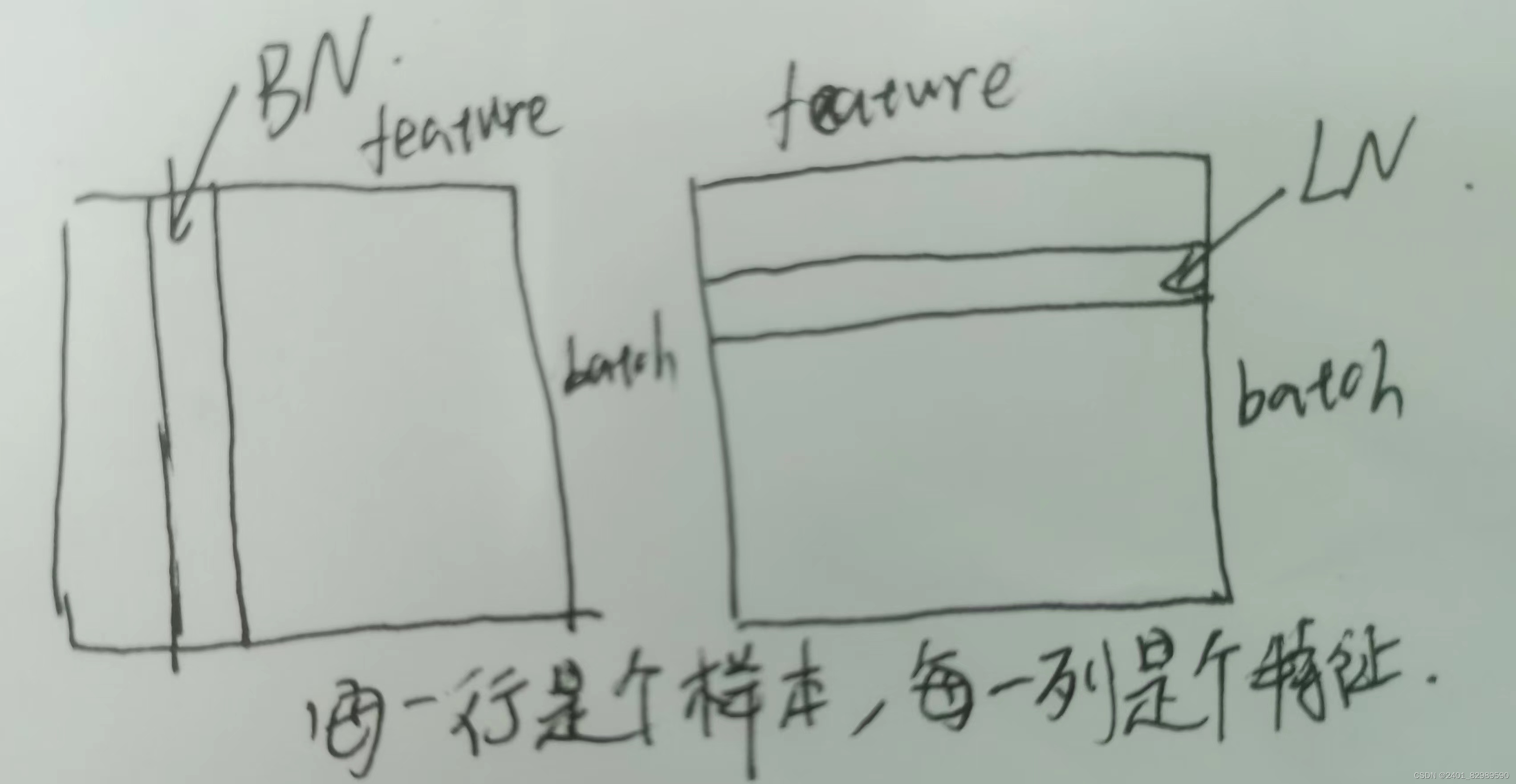
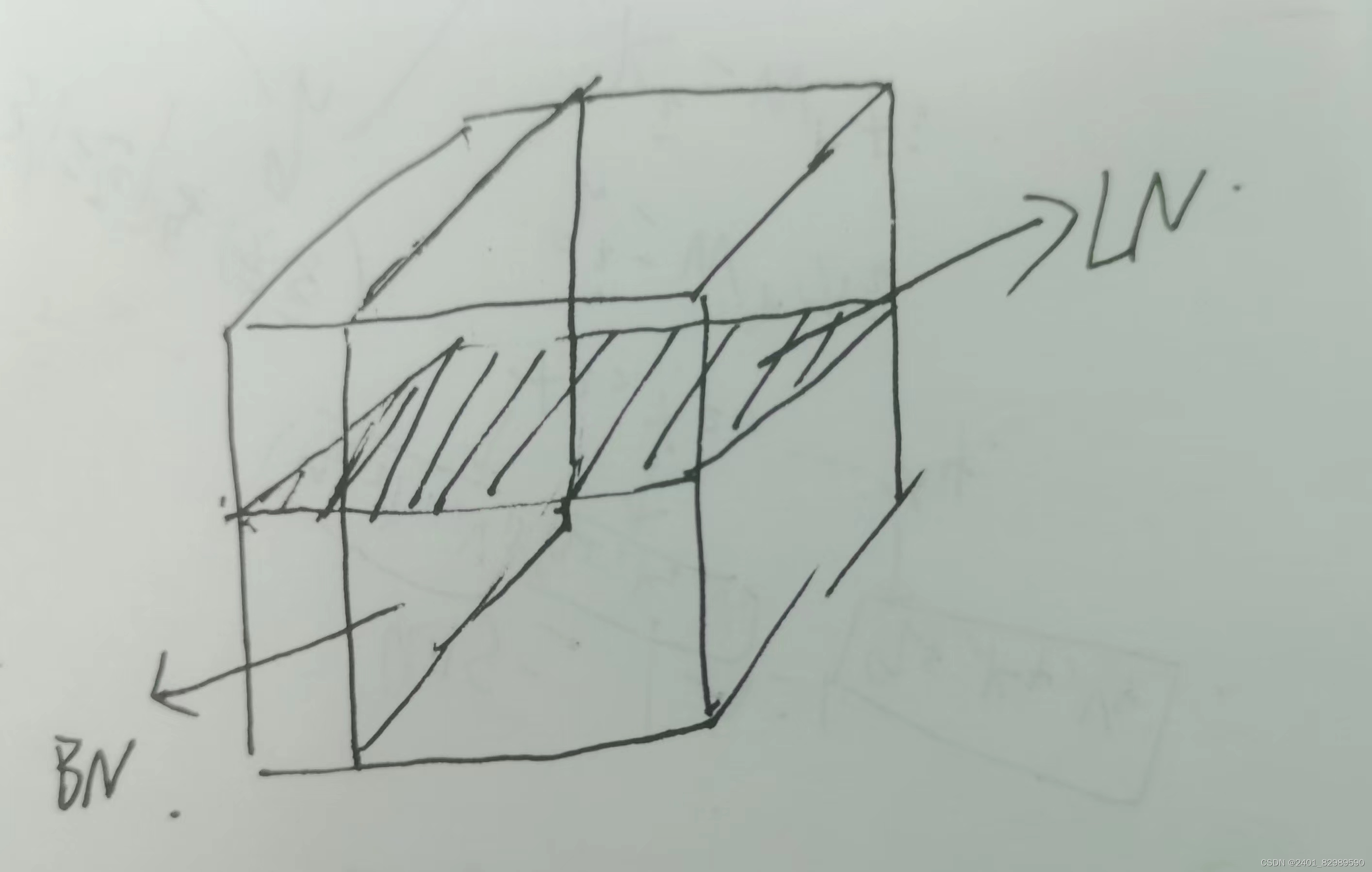
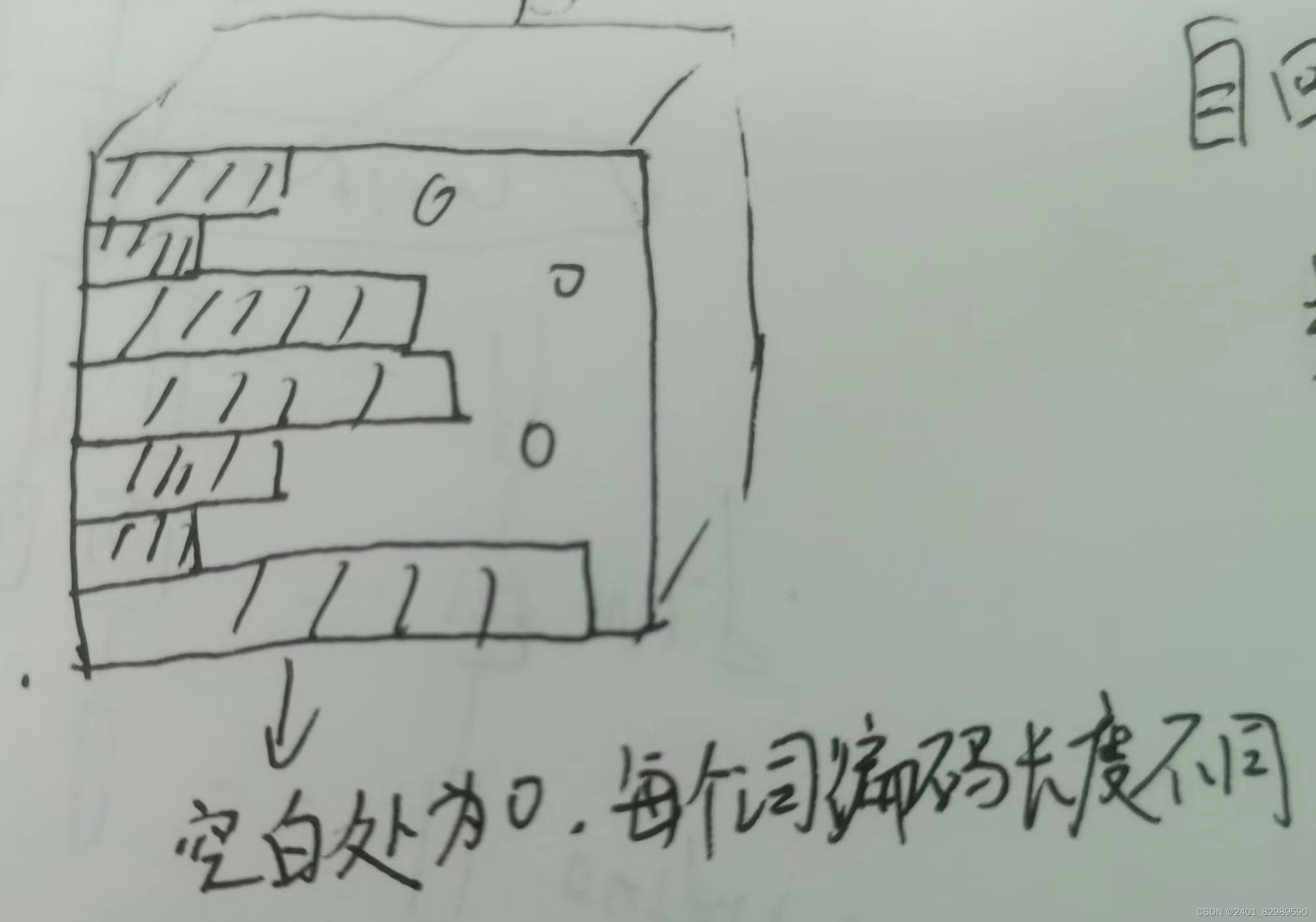
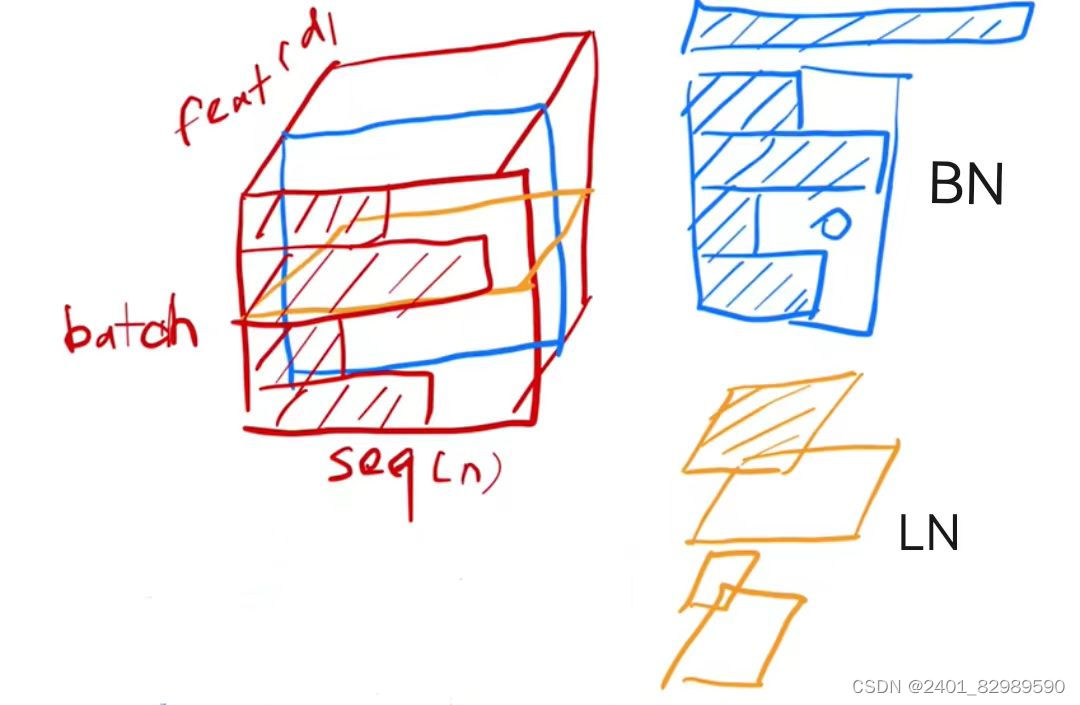
如上图,若使用BN会使结果不均衡,样本长度变化比较大时,小批量算出的均值和方差抖动比较大。而LN是在每个样本自己里面算的,相对稳定。
transformer
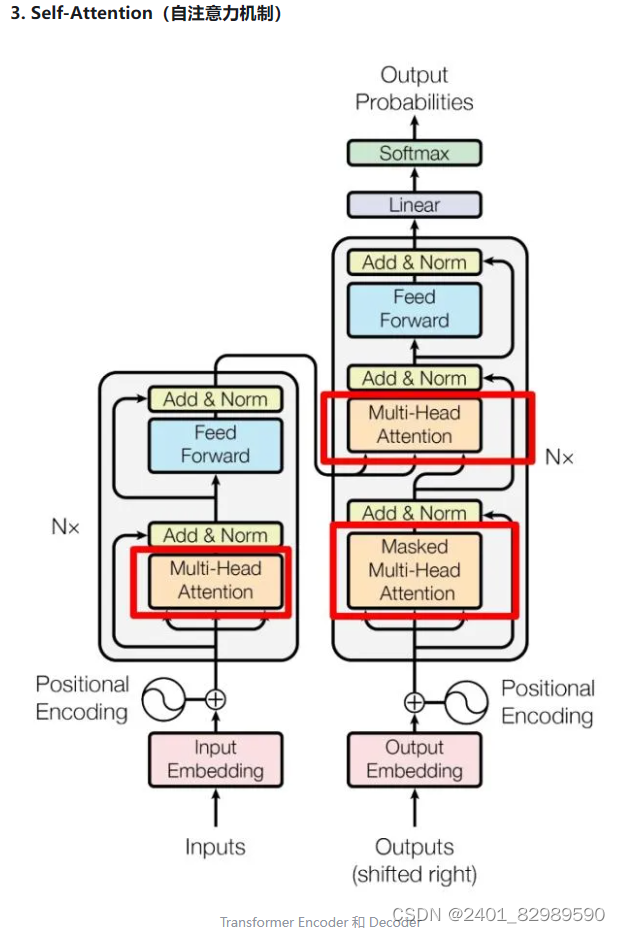
attention将整个序列中感兴趣部分抓取出来,并汇聚。输出的是values加权和,没有时序信息,若打乱单词顺序,attention的输出一样。所以transformer将时序信息通过positional encoding添加在输入中。decoder是一个自回归,即当前输出是之后输入。所以decoder用了多头掩码自注意力,将要预测的时刻后的
等权重都设为0。decoder的第二个多头自注意力的输入K、V来自encoder的输出。Q来自上面的多头掩码自注意力的输出。
transformer和RNN的区别:
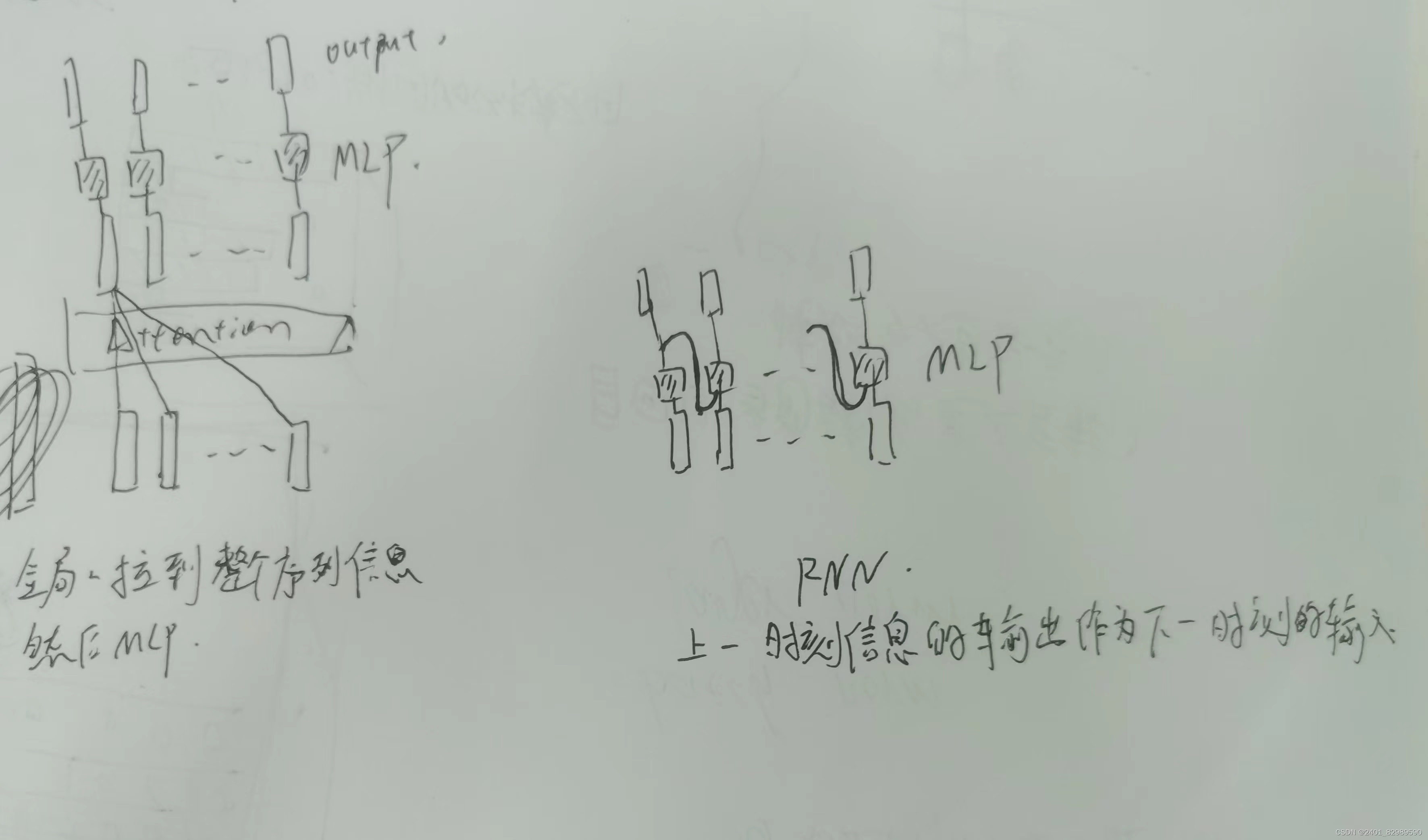
单层的注意力其中输入和通过注意力层的输出大小一样。其中每个MLP权重一样。
RNN是根据上一刻的信息传递到下一刻,transformer是全局的拉到整个序列的信息然后再MLP语义转换。
ELMO(Embeddings from Language Models)
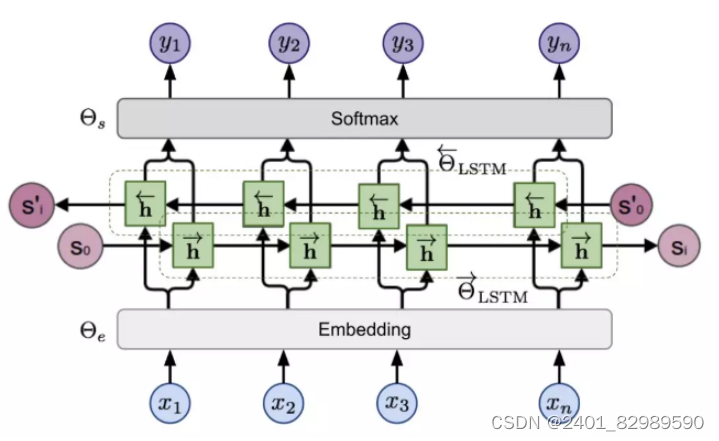
是基于RNN的双向模型(多层的双向LSTM),结合了从左到右和从右到左两个方向的上下文信息,能够为每个单词提供丰富的语义表示。传统的词向量表示方法(如Word2Vec、GloVe等)是上下文无关的,每个词对应一个vector,对于多义词无能为力。相比之下,ELMo生成的词向量是上下文相关的,因为它考虑了该单词在句子中的上下文环境,可以根据上下文动态调整单词的表示。
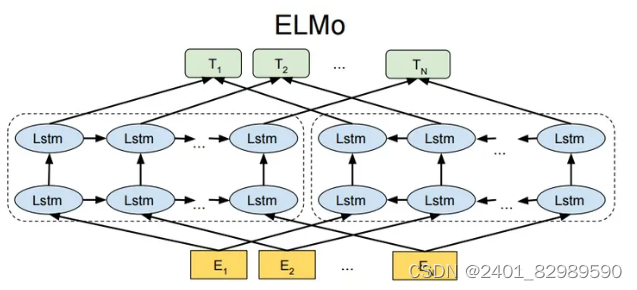
模型分为三层,第一层字符嵌入层Character Embedding Layer即E。
第二层是两层双向LSTM。前向LSTM根据历史之前的序列(x1.....xi-1)预测第i个token xi的概率。
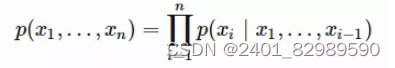
反向LSTM根据历史之后的序列(xi+1......xn)预测第i个token xi的概率。
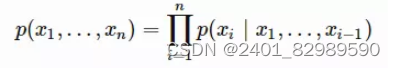
第三层是词向量表示层 (Word Vector Layer)。通过将从双向语言模型中得到的特征进行线性组合,生成每个单词的上下文相关的词向量表示。
双向LSTM:
给定输入token xi得到隐状态为前向的h→i,ℓ和后向的h←i,ℓ。
总的来说,elmo事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,然后通过双向LSTM根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。
预训练好模型后,通过基于特征的方式应用于下游任务。为每个下游任务构建一个相关的神经网络,将输入X先输入到与训练好的elmo,获得elmo每层的embedding,将3个embedding根据权重加起来作为下游任务的输入。
Bert
预训练模型的下游任务特征表示可分为两种,一种是基于特征(ELMO):输入通过预训练学到的特征作为下游任务输入,需为每个下游任务构造相关神经网络。一种是基于微调(GPT):预训练好的模型放在下游任务不需改变太多。Bert是第一个在基于微调的在一系列nlp任务上(句子层面,词元层面)取得最好成绩。
(未完)















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









