






随着深度学习技术的蓬勃发展,生成对抗网络(GANs)特别是Stable Diffusion(简称SD)在图像生成领域取得了令人瞩目的成果。本教程旨在为广大对SDAI文生图技术感兴趣的学习者提供一个入门级的指南,帮助大家快速上手并掌握这一前沿技术。
#01
/模型选择
AI绘画最重要的是需要清楚自己的创作需求,即自己希望出来的图片是什么风格、什么场景、什么人物等等。
那么我根据需求将模型分为五种类型:
-
官方模型:由Stable Diffusion团队官方出的大模型,也叫底模;
-
二次元模型:模型训练的数据以二次元的素材为主,对于二次元的场景和人物有着针对性的优化,出图效果好;
-
真实系模型:模型训练的数据以实际照片素材为主,对于真实感和人物细节的还原会比其他模型好非常多;
-
2.5D模型:多为混合模型,出来的效果图在二次元的基础上带有真实效果,类似于3D建模;
-
其他模型:其他一些垂直领域的模型,如平面设计、魔幻场景、建筑风格等等;
选择需要使用的模型(底模),这是对生成结果影响最大的因素,主要体现在画面风格上。
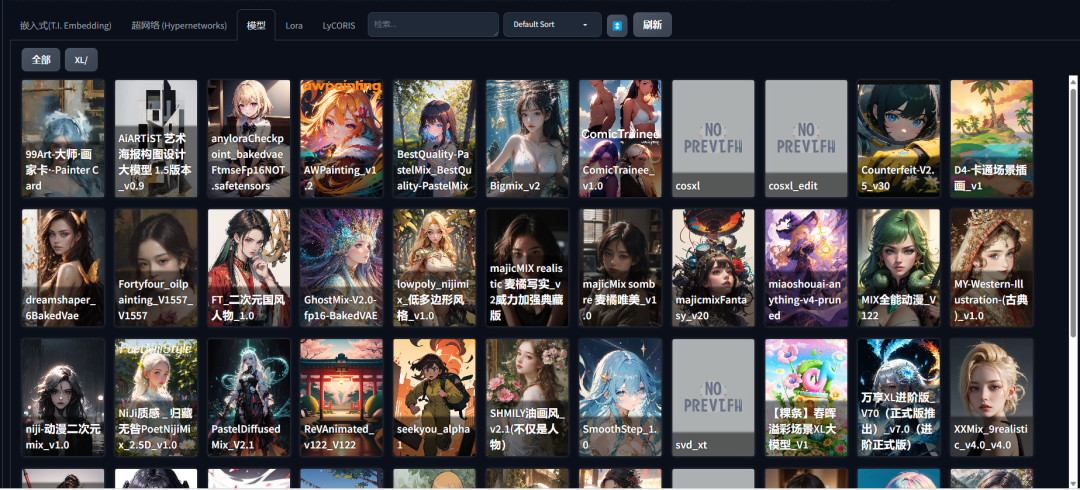
** **
#02
/写关键词
在中,关键词(或称为提示词)可以分为正向(Prompt)和反向(Negative prompt)两种,它们分别用于指导和限制模型生成图像的方向。
1、SD关键词基本规则:
A:关键词之间必须用英文状态下的逗号分割;
B:关键词是可以分行写的,特别是不同性质的关键词:
C:每个关键词的默认权重都是一样的为1,但越靠前的关键词,系统会自动分配更高一级的权重。所以我们在写关键词的时候,应当尽可能将需要突出的特征关键词放在前面位置;
D:关键词的数量并非越多越好。我们在SD中可以看到,关键词框后面有个75的数字,即表明系统默认为最多写75个单词,多出的关键词并不能对系统生成的结果起到明显的作用。
2、关键词中符号的用法:
A:在SD关键词中我们经常用()、[]、<>来设置某个关键词在整体中的权重。
( ):将关键词放在小括号中,表示这个关键词的权重要提升10%即为1.1,小括号最多可以叠加三层((( ))),即表示这个关键词权重提升到1.331。当然更多的时候我们是只用一层小括号,然后在关键词后面加:和权重数字。比如(blue eyes:1.4)这样。
[ ] :将关键词放在中括号内,表示这个关键词的权重要降低10%即为0.9,中括号同样最多叠加三层[[[ ]]]表示这个关键词权重降低到0.729.
{ }:将关键词放在大括号中,也是表示这个关键词的权重会增加,但它的提升幅度要比小括号( )小。一层{ }只能提升5%。
B:< >尖括号的作用主要是在关键词中引入Lora。格式为<Lora名称:Lora文件的触发词:Lora权重>
C:_ 英文状态下的下划线。它通常用在两个关键词之间,表示这两个关键词是紧密联系的。比如 milk,cake两个关键词分开写SD系统会认为是表示牛奶、蛋糕两个品种,而 milk_cake表示牛奶蛋糕,一个品种。
3、控制关键词的生效时间:
在SD的关键词中,有时我们会需要控制某个关键词的生效时间,以控制该关键词特征在整体图片中的比例或权重,这时我们可以将此关键词放入中括号[ ],加:生效时间段比例。比如:forest,tree,stone,bird,[flowers:0.8]
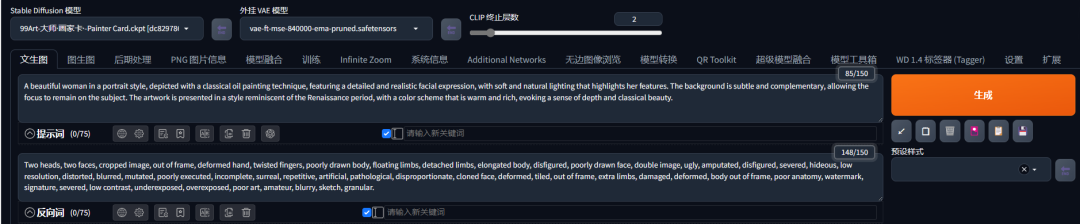
在第上面的框中填入提示词(Prompt),对想要生成的东西进行文字描述在第下面框中填入负面提示词(Negative prompt),你不想要生成的东西进行文字描述。
#03
/参数调整
选择采样方法、采样次数、图片尺寸等参数。
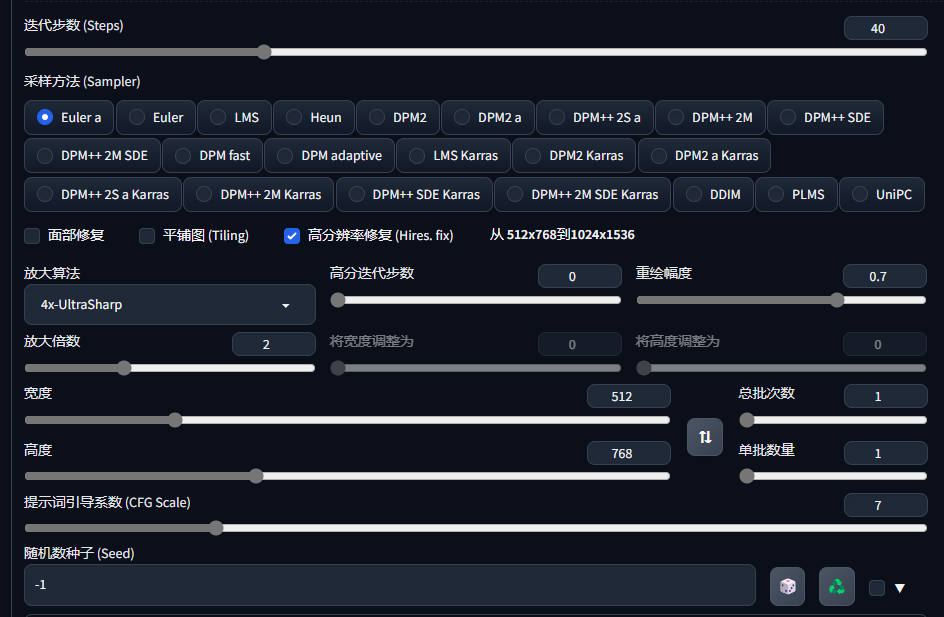
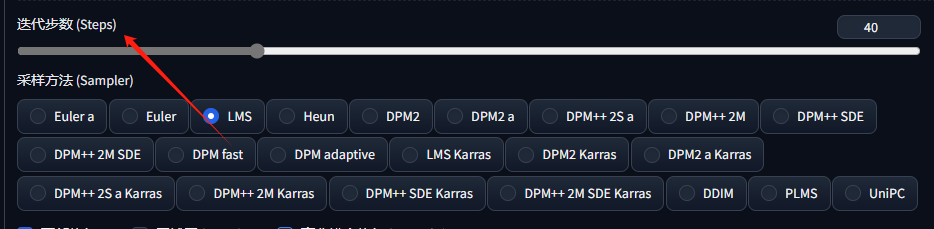
1、采样方法:

•Sampler(采样器/采样方法) 选择使用哪种采样器。Euler a(Eular ancestral)可以以较少的步数产生很大的多样性,不同的步数可能有不同的结果。而非 ancestral 采样器都会产生基本相同的图像。DPM 相关的采样器通常具有不错的效果,但耗时也会相应增加。
◦Euler 是最简单、最快的
◦Euler a 更多样,不同步数可以生产出不同的图片。但是太高步数 (>30) 效果不会更好。
◦DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用。
◦LMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概 30 step 可以得到稳定结果
◦PLMS 是 Euler 的衍生,可以更好地处理神经网络结构中的奇异性。
◦DPM2 是一种神奇的方法,它旨在改进 DDIM,减少步骤以获得良好的结果。它需要每一步运行两次去噪,它的速度大约是 DDIM 的两倍,生图效果也非常好。但是如果你在进行调试提示词的实验,这个采样器可能会有点慢了。
◦UniPC 效果较好且速度非常快,对平面、卡通的表现较好,推荐使用。
2、迭代步数:
•Sampling Steps(迭代步数) Stable Diffusion 的工作方式是从以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到 20~30。
•不同采样步数与采样器之间的关系:

3、CFG:
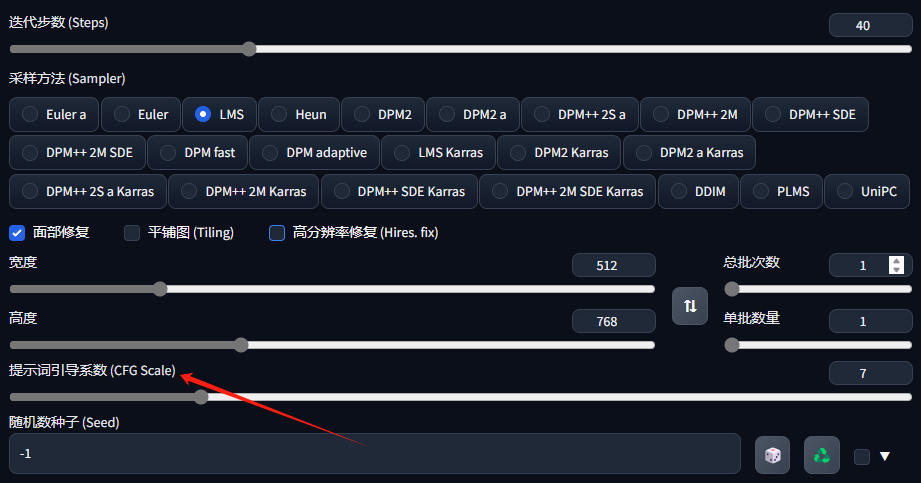
•CFG Scale(提示词相关性) 图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。CFG Scale 与采样器之间的关系:

4、批次:

•总批次数 每次生成图像的组数。一次运行生成图像的数量为“批次* 批次数量”。
•单批数量 同时生成多少个图像。增加这个值可以提高性能,但也需要更多的显存。大的 Batch Size 需要消耗巨量显存。若没有超过 12G 的显存,请保持为 1。
5、尺寸:
•尺寸 指定图像的长宽。出图尺寸太宽时,图中可能会出现多个主体。1024 之上的尺寸可能会出现不理想的结果,推荐使用小尺寸分辨率+高清修复(Hires fix)。
6、种子:
•种子 种子决定模型在生成图片时涉及的所有随机性,它初始化了 Diffusion 算法起点的初始值。理论上,在应用完全相同参数(如 Step、CFG、Seed、prompts)的情况下,生产的图片应当完全相同。
7、高清修复:
•高清修复

通过勾选 "Hires. fix" 来启用。默认情况下,文生图在高分辨率下会生成非常混沌的图像。如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果。最终尺寸为(原分辨率*缩放系数 Upscale by)。
•放大算法中,Latent 在许多情况下效果不错,但重绘幅度小于 0.5 后就不甚理想。ESRGAN_4x、SwinR 4x 对 0.5 以下的重绘幅度有较好支持。
•高分迭代步数 表示在进行这一步时计算的步数。
•重绘幅度,表现为最后生成图片对原始输入图像内容的变化程度。该值越高,放大后图像就比放大前图像差别越大。低,意味着修正原图,高 , 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。
8、面部修复:
•面部修复 修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。
9、生成:
•点击“生成”
往期回顾
BREAK AWAY
** **
** **
AI绘画关键词|语言大模型辅助关键词技巧,提率曾效 2024-05-17 编辑
ComfyUI|进阶教程 字节最强换脸插件PuLID 2024-05-16 编辑
Stable Diffusion|进阶篇图片复现AnimateDiff动画插件基础教程 2024-05-15 编辑
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
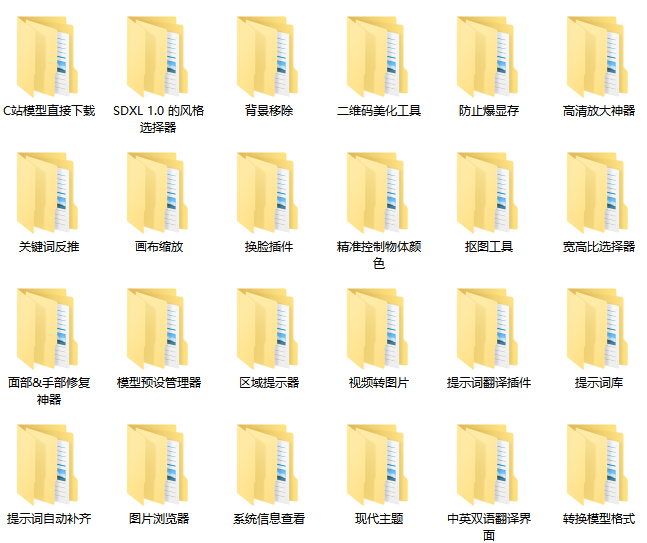
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
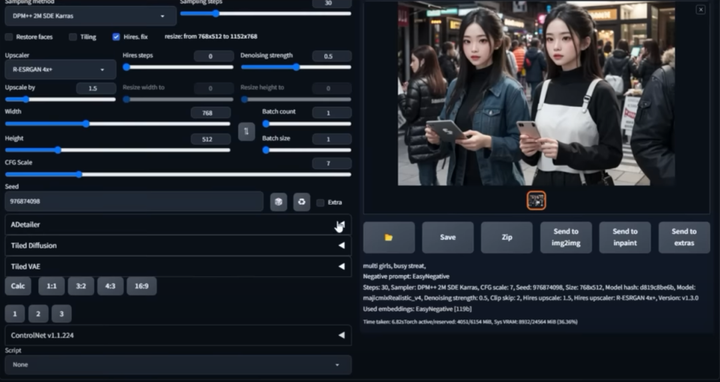
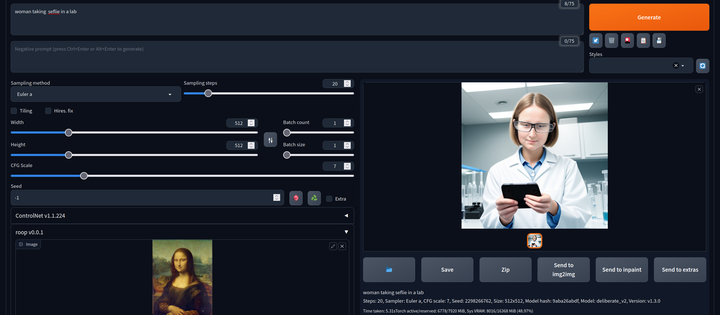
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
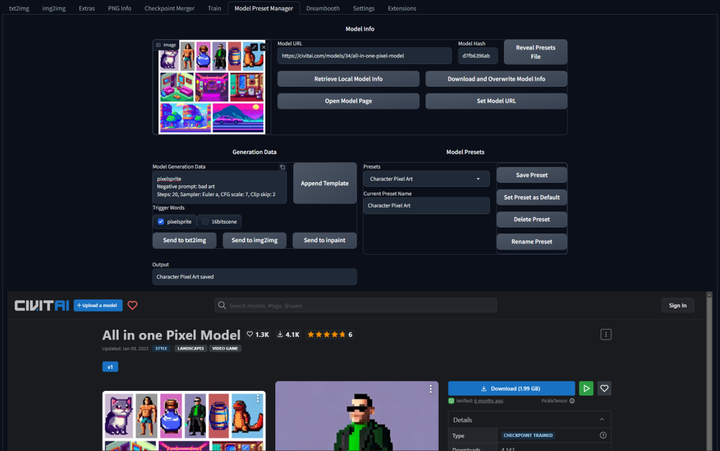
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
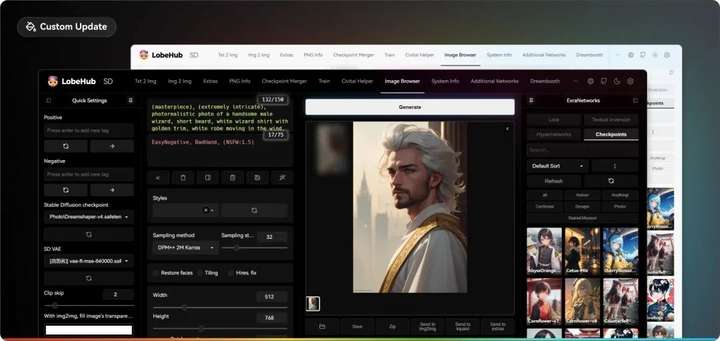
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
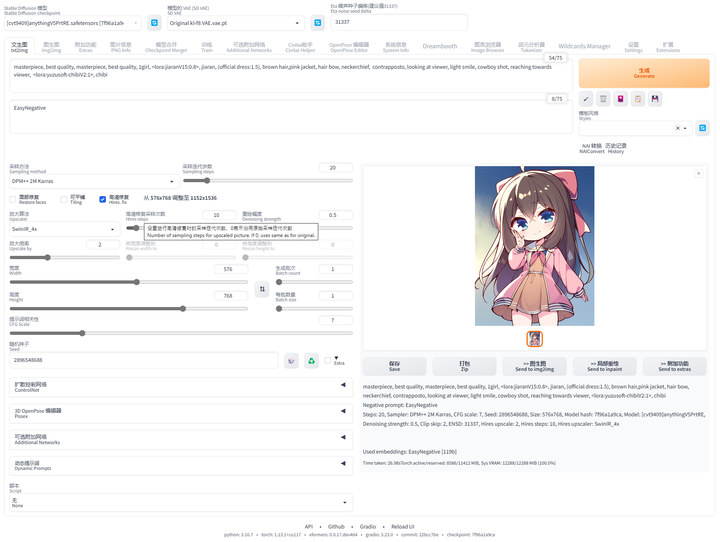
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
由于篇幅原因,有需要完整版Stable Diffusion插件库的小伙伴,点击下方插件即可免费领取


















 6955
6955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









