







 本文对比了StableDiffusion3和MidjourneyV6在不同场景下的表现,强调了StableDiffusion3在理解提示词、英文处理和品牌图标呈现方面的优势,但人体细节和审美上稍逊于Midjourney。作者认为StableDiffusion3有巨大潜力,尤其是在本地部署和开放原则的支持下。
本文对比了StableDiffusion3和MidjourneyV6在不同场景下的表现,强调了StableDiffusion3在理解提示词、英文处理和品牌图标呈现方面的优势,但人体细节和审美上稍逊于Midjourney。作者认为StableDiffusion3有巨大潜力,尤其是在本地部署和开放原则的支持下。
文末扫🐎免费获取资源
最近文生图领域最重要的消息,就是Stable Diffusion 3的推出。
目前,有两种使用Stable Diffusion 3的方法,一种是通过API调用,这需要在Stability AI开发者平台申请API Keys:
Stability AI开发者平台
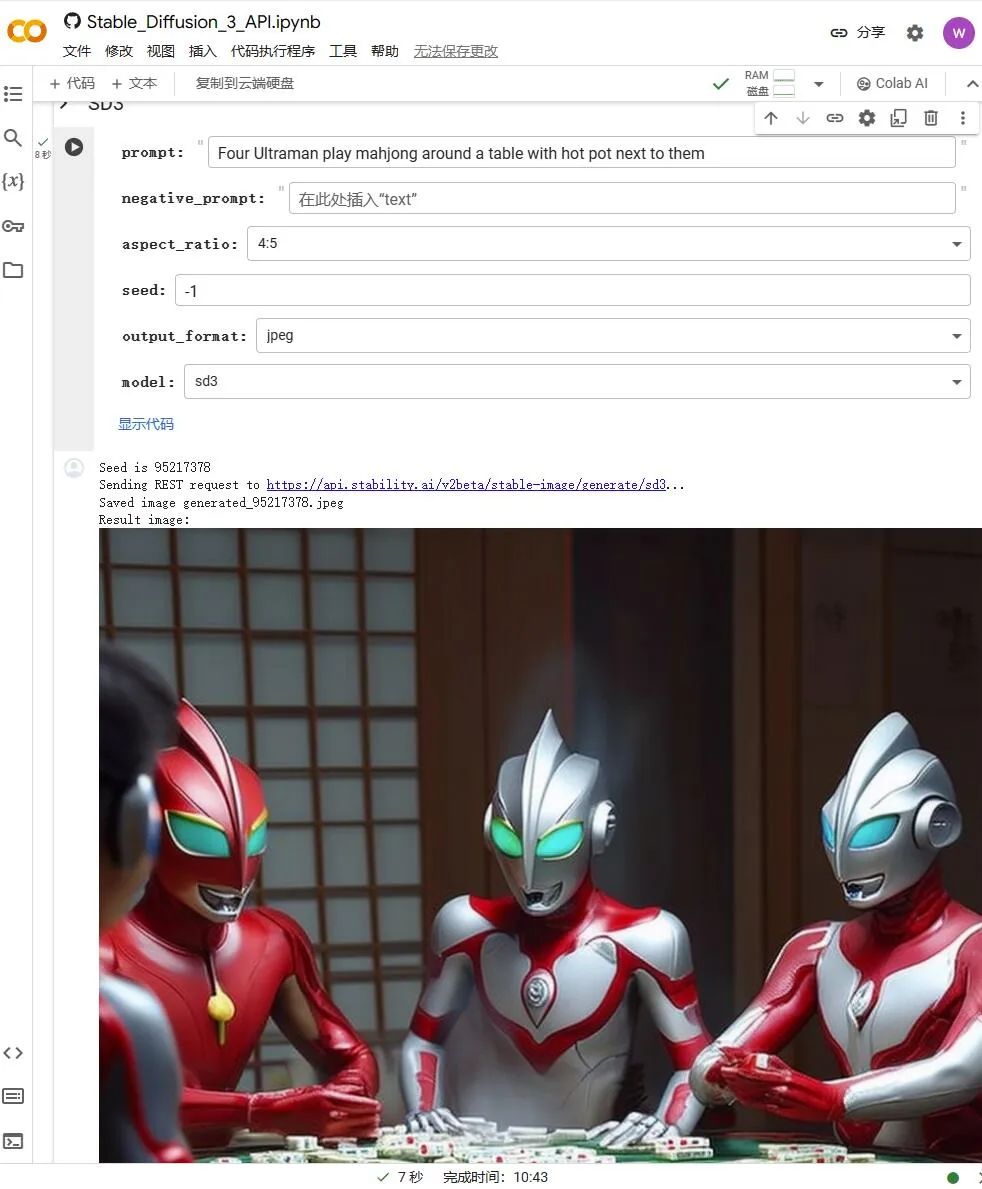
在Google Colab上调用API进行绘图
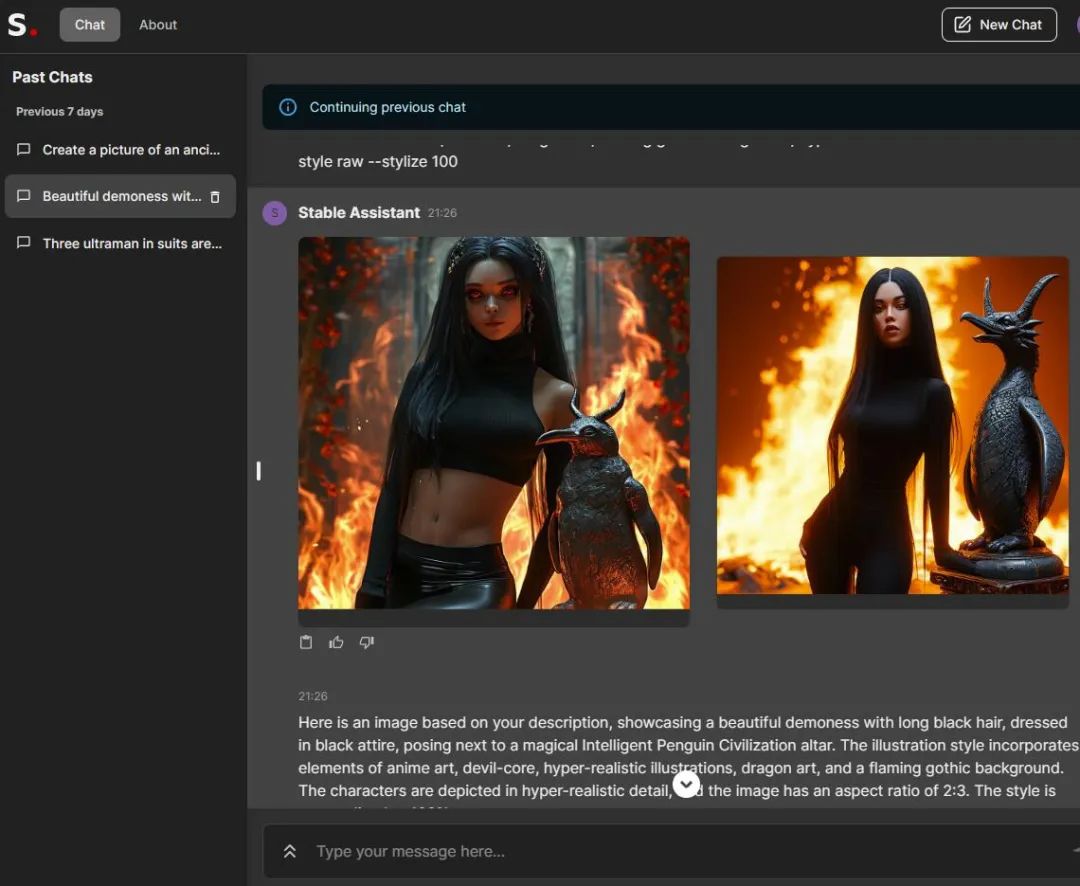
另一种方法,是使用Stable Assistant聊天机器人(需申请),类似在ChatGPT里使用DALLE3:
通过Stable Assistant使用SD3
总之,目前两种方式都需要付费,10美元1000点数,只能画不到200张图,并不便宜。
那到底效果如何,今天就和Midjourney(V6)作一番详细对比:
**
1.**
美丽的魔女,黑色长发,穿着黑色高领套头衫和黑色瑜伽裤,在一个神奇的智能企鹅文明祭坛旁摆姿势,雕像,动画艺术风格,魔鬼核心,超现实插画,32k uhd,龙的艺术,燃烧的哥特式背景,超现实的人物。
Beautiful demoness with long black hair, dressed in a black turtleneck jumper and black yoga pants, posing next to a magic Intelligent Penguin Civilization altar, a statue, in the style of anime art, devil-core, hyper-realistic illustrations, 32k uhd, dragon art, flaming gothic background, hyper-realistic characters.
Stable Diffusion 3

Midjourney V6

两款工具的画风都比较精致,但MJ6没能体现“魔女”,SD3则加入了眼睛异色、头上长角的元素。
2.
狮子肖像,黑白,逼真
lion portrait, black and white, photorealistic
Stable Diffusion 3

Midjourney V6

两款工具表现都很好,好到简直像是以同一只狮子的照片训练的。
3.
贴纸设计的武士宫本武藏,他与樱花树站在一起,平静,安详,极简的线条插图,黑色的灰色和橙色,白色的背景
sticker design of samurai Miyamoto Musashi, he is standing with cherry blossoms tree, he is standing calm, serene, minimalistic line illustration, black gray and orange colors, white background
Stable Diffusion 3

Midjourney V6

相比之下,MJ6更符合“极简”的要求。
4.
一堆垃圾,高得像一座山,活着的人类演员从里面伸出来,人类垃圾超写实,色彩鲜艳,现代,白色背景
pile of garbage, very tall like a mountain, alive human comedians sticking out of it, ala human garbage ultra realistic, colorful, modern, white background
Stable Diffusion 3

Midjourney V6

各有所长,但MJ6在人物的细节上面表现更好。
5.
泰伦斯·马利克拍摄的现代电影,当代在热气球上野餐和西蒙妮·吉尔兹吃糖果的场景
Cinematic film still of modern contemporary picnic in a hot air balloon and a simone giertz eating a candy bar by terrence malik
Stable Diffusion 3

Midjourney V6

提示词包含具体的导演风格和演员形象,两款工具不相伯仲,但对于表现“吃东西”都有点困难。
**6.
**
Stable Diffusion 3

Midjourney V6

个人感觉都差不多,但MJ6的工人是白人,SD3的工人是黑人?
7.
动作科幻电影中女主角的电影广角镜头,控制论增强,运动身体,未来主义,戏剧性的姿势,大胆的灯光,景深,引人注目的视觉效果
cinematic wide shot of a lead heroine in an action packed sci fi movie with cybernetic enhancements, athletic body, futuristic, dramatic pose, bold lighting, depth of field, striking visual effects
Stable Diffusion
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2625
2625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









