






 本文详细介绍了MapReduce的第一张运行架构图,并着重讨论了其在可扩展性、容错性和简单性方面的特点。通过并行处理和任务分发,MapReduce模型能有效处理大规模数据集,即使在节点故障情况下也能保证数据处理的连续性。
本文详细介绍了MapReduce的第一张运行架构图,并着重讨论了其在可扩展性、容错性和简单性方面的特点。通过并行处理和任务分发,MapReduce模型能有效处理大规模数据集,即使在节点故障情况下也能保证数据处理的连续性。
1️⃣First MapReduce运行架构图如下所示:
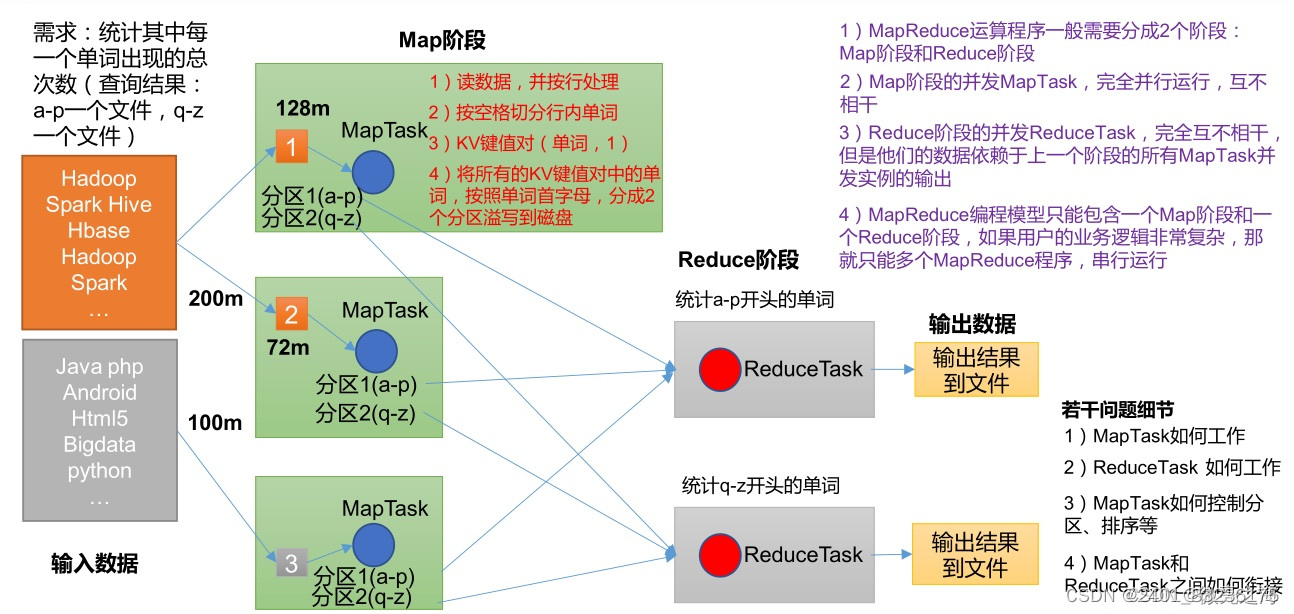
2️⃣ Second MapReduce的特点
▶️ 可扩展性:由于MapReduce模型的并行处理特性,它能够有效地处理大规模数据集。通过将任务分解为多个并行的Map和Reduce任务,可以在集群中的多个计算节点上同时处理数据,从而实现横向扩展。
▶️容错性:在MapReduce中,每个Map和Reduce任务都是独立的,它们之间没有依赖关系。当一个计算节点发生故障时,系统可以自动重新分配任务给其他可用的节点,从而实现容错性。
▶️简单性:MapReduce模型提供了一种简单而直观的方法来处理大规模数据集。















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









