






 本文详细介绍了Hadoop生态系统的关键组件,包括HDFS的分布式文件系统、MapReduce的分布式计算框架、HBase的NoSQL数据库以及Spark的快速数据处理引擎。文章突出了这些技术在数据存储、处理、扩展性和容错性方面的特性,以及它们之间的区别和互补性。
本文详细介绍了Hadoop生态系统的关键组件,包括HDFS的分布式文件系统、MapReduce的分布式计算框架、HBase的NoSQL数据库以及Spark的快速数据处理引擎。文章突出了这些技术在数据存储、处理、扩展性和容错性方面的特性,以及它们之间的区别和互补性。
一. 介绍hadoop生态圈的详细资料
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop 的核心是 HDFS 和 Mapreduce,HDFS 还包括 YARN。
1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与namenode交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
HDFS:HDFS(Hadoop Distributed File System)是Hadoop体系的核心组件之一,它是一个分布式文件系统,被设计用于存储大规模数据集,并在Hadoop集群中进行高可靠性的数据存储。
HDFS的主要功能和作用包括:
1、分布式存储:HDFS将大量的数据文件分布式地存储在Hadoop集群中的多个机器上。数据被分割成块并复制到多个节点上,提供了可靠性和容错性,防止数据丢失。
2、高可靠性:HDFS通过数据冗余和复制机制来提供高可靠性。每个数据块都会在多个节点上进行复制,如果一个节点失败,数据仍然可以从其他副本中访问。
3、数据流式访问:HDFS支持以流式方式对大规模数据进行访问。它通过一次传输整个数据块的方式,以提高读写数据的效率。
4、扩展性:HDFS具有良好的可扩展性,可以容纳非常大的数据集。它可以在集群中添加新的机器,以同时扩展存储容量和计算能力。
5、数据局部性:HDFS通过尽量将数据存储在离计算节点近的位置来提高数据访问的效率。这样可以减少网络传输的开销,提高数据处理的性能。
HBase:HBase是一种分布式、可扩展的面向列的NoSQL数据库,它基于Hadoop的HDFS和ZooKeeper来提供可靠的、高性能的数据存储和实时读写访问。HBase的功能和作用包括:
1、面向列的存储:HBase采用面向列的存储方式,数据被组织成表,每个表由行和列族组成。这种存储方式使得HBase能够存储和处理非结构化和半结构化的数据。
2、高可扩展性:HBase能够在大规模数据集上进行水平扩展。它可以在大量的服务器节点上进行数据存储和处理,以满足日益增长的数据量和访问需求。
3、高性能的读写访问:HBase的存储引擎使用了基于内存的索引结构(B+树),能够提供高速的读写访问性能。此外,HBase支持数据缓存、批处理操作和并行处理,进一步提高了数据的访问效率。
4、数据一致性:HBase通过ZooKeeper来提供数据的一致性。ZooKeeper是一个分布式协调服务
保数据的一致性和可靠性。
5、实时查询:HBase支持基于行键的随机访问和范围扫描,可以快速检索和查询数据。它还支持多版本数据,可以存储和检索历史数据,适用于时间序列数据和实时分析。
6、强一致性:HBase支持强一致性,即对于相同的数据操作请求,返回的结果是一致的。这对于需
要保持数据一致性的应用场景非常重要,例如金融和电子商务领域。
总之,HBase作为一种分布式、可扩展的NoSQL数据库,提供了高性能、高可靠性和高扩展性的数据存储和访问解决方案,适用于处理大规模的非结构化和半结构化数据。
HDFS(Hadoop Distributed File System)和HBase 是 Hadoop生态圈中两个重要的组件,它们在应用场景上有一些区别。
计算分析引擎组件
MapReduce:
MapReduce 是 Hadoop 生态圈中的一个重要组件,主要用于实现分布式计算。它的作用是将大规模数据集划分为较小的数据块,并在集群中的多台计算机上进行并行处理。MapReduce 通过将数据分为不同的键值对,然后对键值对进行映射(Map)和归约(Reduce)操作,来实现分布式计算。
MapReduce 通常不会单独使用,而是与其他组件配合使用。它常常与分布式存储系统 HDFS(Hadoop Distributed File System)一起使用,以处理存储在 HDFS 中的大规模数据集。此外,MapReduce 还可以与其他组件如Hive、Pig、Spark等结合使用,以实现更复杂的数据处理和分析任务。
总而言之,MapReduce 对于分布式计算非常重要,但单独使用的场景较少,通常与其他组件相结合以实现更强大的数据处理能力。
Hive:
它提供了一个类似于 SQL 的查询语言,用于进行数据提取、转换和加载(ETL)操作。Hive 的主要功能和作用如下:
1、数据的存储和管理:Hive 可以将数据存储在 Hadoop 分布式文件系统(HDFS)中,并管理数据的元数据信息。
2、数据查询和分析:Hive 支持类似于 SQL 的查询语言 HiveQL,使用户能够方便地针对存储在 HDFS 中的数据进行复杂的数据查询和分析。
3、数据转换和处理:Hive 的查询语言 HiveQL 支持丰富的数据转换函数和操作,用户可以使用 HiveQL 进行数据提取、转换和加载(ETL)操作,对数据进行加工和清洗。
4、扩展性和灵活性:Hive 支持用户自定义函数(UDF)和用户自定义聚合函数(UDAF),可以方便地扩展 Hive 的功能。
集成与生态圈:Hive 与其他 Hadoop 生态圈中的组件(如 HDFS、MapReduce、HBase、Spark 等)紧密集成,可以与它们配合使用,实现更复杂的数据处理和分析任务。
总而言之,Hive 提供了一套方便的数据查询
Spark:
它是一个快速、通用的大数据处理引擎,具备内存计算和分布式计算的能力。Spark 的主要功能和作用如下:
1、快速、分布式数据处理:Spark 使用分布式内存计算技术,将数据存储在内存中,从而加速数据处理和分析的速度。Spark 提供了丰富的数据处理操作和算法,如 Map、Reduce、Filter、Join、GroupBy 等,可用于大规模数据的处理、转换和分析。
2、支持多种数据源:Spark 可以处理来自多种数据源的数据,包括 Hadoop 分布式文件系统(HDFS)、Amazon S3、关系型数据库、NoSQL 数据库等。
3、数据流处理:Spark Streaming 是 Spark 提供的批处理和实时处理的框架,用户可以使用类似于批处理的编程模型对实时数据进行处理和分析。
MapReduce是一种编程模型,用于大规模数据集 的并行运算。概念"map(映射)和reduce(归约)",和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
1、MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2、良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3、高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4、适合PB级以上海量数据的离线处理
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点
一、速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍
在这里插入图片描述
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
Spark处理数据时,可以将中间处理结果数据存储到内存中
Spark Job调度以DAG方式,并且每个任务Task执行以线程方式,并不是像MapReduce以进程方式执行
二、易于使用
Spark的版本已经更新到了Spark3.1.2(截止日期2021.06.01),支持了包括Java、Scala、Python、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本
三、通用性强
四、运行方式
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时也可以运行在云Kubernets(Spark2.3开始支持)上
对于数据源而言,Spark支持从HDFS、HBase、Cassandra及Kafka等多种途径获取和数据。
二者的一些区别:
1、Spark的速度比MapReduce快,Spark把运算的中间数据存放在内存,迭代计算效率更高;mapreduce的中间结果需要落地,需要保存到磁盘,比较影响性能;
2、spark容错性高,它通过弹性分布式数据集RDD来实现高效容错;mapreduce容错可能只能重新计算了,成本较高;
3、spark更加通用,spark提供了transformation和action这两大类的多个功能API,另外还有流式处理sparkstreaming模块、图计算GraphX等;mapreduce只提供了map和reduce两种操作,流计算以及其他模块的支持比较缺乏,计算框架(API)比较局限;
4、spark框架和生态更为复杂,很多时候spark作业都需要根据不同业务场景的需要进行调优已达到性能要求;mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行。
备份和恢复
冷、温、热备份
冷备:读写操作均不可进行
温备:读操作可执行;但写操作不可执行
热备:读写操作均可执行
有关于linux中的命令
pwd:查看当前目录的完整路径,如下图:
cd:进入指定目标文件夹

vi:编写目标路径文件夹中的文件(图中所指文件为网络编辑所在的文件)
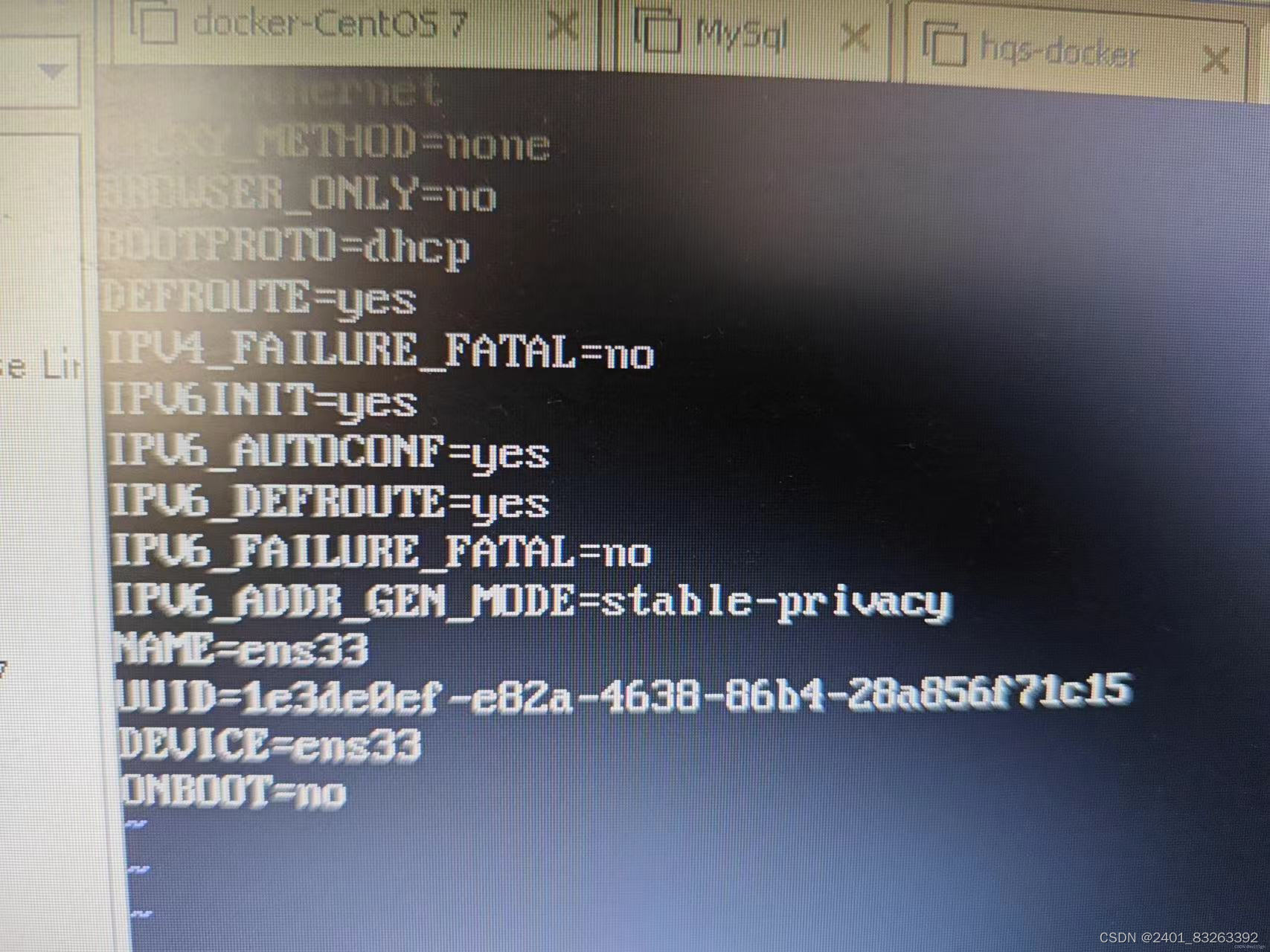
效果为:
touch:在当前目录下创建文件。

ls:显示当前文件夹中的所有文件(包括路径下的文件夹)

rm:删除所需要删除的文件。(rfv可视化强制递归删除)

数值类型
MySQL支持所有标准的SQL数值类型,包括精确数值类型(INTEGER,SMALLINT和DECIMAL)
//INTEGER 整形 ; SMALLINT 短整型; DECIMAL 小数
和近似数值类型(FLOAT,REAL和 DOUBLE PRECISION)
//FLOAT 浮点型;REAL 实数 DOUBLE PRECISION双精度数
常见关键字:INT 是INTGER 的缩写,DEC是DECIMAL的缩写
MySQL会尝试尽可能将现在的值转换为新类型。
2.日期和时间类型
表示日期和时间值的日期和时间类型有DATATIME,DATA,TIMESTAMP,TIME和YEAR。每个时间类型有一个有效值范围和一个"零"值,当输入不合法的值时,MySQL使用"零"值插入。
TIMESTAMP类型具有专有的自动更新特性。















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









