






一、Hadoop平台安装
1.绑定主机名与 IP 地址
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
2.查看ssh服务状态
[root@master ~]#systemctl status sshd
3.关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl status firewalld
执行如下命令可以永久关闭防火墙
[root@master ~]# systemctl disable firewalld
4.创建 hadoop 用户
[root@master ~]# useradd hadoop
[root@master ~]# echo "1" |passwd --stdin hadoop
更改用户 hadoop 的密码 。
passwd:所有的身份验证令牌已经成功更新。
5.安装 JAVA 环境
下载 JDK 安装包下 载 地 址 为 :
https://www.oracle.com/java /technologies /javase-jdk8-downloads.html
6.卸载自带 OpenJDK
[root@master ~]# rpm -qa | grep java
卸载相关服务,键入命令
[root@master ~]# rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.352.b082.el7_9.x86_64
[root@master ~]# rpm -e --nodeps tzdata-java-2022e-1.el7.noarch
[root@master ~]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.352.b082.el7_9.x86_64
[root@master ~]# rpm -qa | grep java
查看删除结果再次键入命令 java -version 出现以下结果表示删除功
[root@master ~]# java --version
bash: java: 未找到命令
7.安装 JDK
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -C /usr/local/src/ [root@master ~]# ls /usr/local/src/ jdk1.8.0_152
8.设置 JAVA 环境变量
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
执行 source 使设置生效:
[root@master ~]# source /etc/profile
检查 JAVA 是否可用。
[root@master ~]# echo $JAVA_HOME
/usr/local/src/jdk1.8.0_152
[root@master ~]# java -version java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
能够正常显示 Java 版本则说明 JDK 安装并配置成功。
二.安装 Hadoop 软件
1.安装 Hadoop 软件
[root@master ~]# tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /usr/local/src/
[root@master ~]# ll /usr/local/src/
总用量 0
drwxr-xr-x. 9 10021 10021 149 6月 29 2015 hadoop-2.7.1
drwxr-xr-x. 8 10 143 255 9月 14 2017 jdk1.8.0_152
查看 Hadoop 目录,得知 Hadoop 目录内容如下:
[root@master ~]# ll /usr/local/src/hadoop-2.7.1/
总用量 28
drwxr-xr-x. 2 10021 10021 194 6月 29 2015 bin
drwxr-xr-x. 3 10021 10021 20 6月 29 2015 etc
drwxr-xr-x. 2 10021 10021 106 6月 29 2015 include
drwxr-xr-x. 3 10021 10021 20 6月 29 2015 lib
drwxr-xr-x. 2 10021 10021 239 6月 29 2015 libexec
-rw-r--r--. 1 10021 10021 15429 6月 29 2015 LICENSE.txt
-rw-r--r--. 1 10021 10021 101 6月 29 2015 NOTICE.txt
-rw-r--r--. 1 10021 10021 1366 6月 29 2015 README.txt
drwxr-xr-x. 2 10021 10021 4096 6月 29 2015 sbin
drwxr-xr-x. 4 10021 10021 31 6月 29 2015 share
2.配置 Hadoop 环境变量
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source 使用设置生效:
[root@master ~]# source /etc/profile
检查设置是否生效:
[root@master ~]# hadoop
3.修改目录所有者和所有者组
[root@master ~]# chown -R hadoop:hadoop /usr/local/src/
[root@master ~]# ll /usr/local/src/
总用量 0
drwxr-xr-x. 9 hadoop hadoop 149 6月 29 2015 hadoop-2.7.1
drwxr-xr-x. 8 hadoop hadoop 255 9月 14 2017 jdk1.8.0_152
三.安装单机版 Hadoop 系统
1.配置 Hadoop 配置文件
[root@master ~]# cd /usr/local/src/hadoop-2.7.1/
[root@master hadoop-2.7.1]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@master hadoop-2.7.1]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export JAVA_HOME 这行,将其改为如下所示内容:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
2.测试 Hadoop 本地模式的运行
切换到 hadoop 用户
[root@master hadoop-2.7.1]# su - hadoop
[hadoop@master ~]$ id
uid=1001(hadoop) gid=1001(hadoop) 组=1001(hadoop) 环境 =unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
创建输入数据存放目录
[hadoop@master ~]$ mkdir ~/input
[hadoop@master ~]$ ls
Input
创建数据输入文件
[hadoop@master ~]$ vi input/data.txt
输入如下内容,保存退出。
Hello World
Hello Hadoop
Hello Husan
测试 MapReduce 运行
[hadoop@master ~]$ hadoop jar /usr/local/src/hadoop2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ~/input/data.txt ~/output
[hadoop@master ~]$ ll output/
总用量 4
-rw-r--r--. 1 hadoop hadoop 33 11月 10 23:50 part-r-00000
-rw-r--r--. 1 hadoop hadoop 0 11月 10 23:50 _SUCCESS
[hadoop@master ~]$ cat output/part-r-00000
Hadoop1
Hello 3
Husan 1
World 1
四.实验环境下集群网络配置
修改 slave1 机器主机名
[root@localhost ~]# hostnamectl set-hostname slave1
[root@localhost ~]# bash
[root@slave1 ~]#
修改 slave2 机器主机名
[root@localhost ~]# hostnamectl set-hostname slave2
[root@localhost ~]# bash
[root@slave2 ~]#
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2
[root@slave1 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2
[root@slave2 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2
五.SSH 无密码验证配置
1.生成 SSH 密钥
[root@master ~]# rpm -qa | grep openssh
openssh-server-7.4p1-11.el7.x86_64
openssh-7.4p1-11.el7.x86_64
openssh-clients-7.4p1-11.el7.x86_64
[root@master ~]# rpm -qa | grep rsync
rsync-3.1.2-11.el7_9.x86_64
2.切换到 hadoop 用户
[root@master ~]# su - hadoop
[hadoop@master ~]$
[root@slave1 ~]# useradd hadoop
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$
[root@slave2 ~]# useradd hadoop
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$
3.每个节点生成秘钥对
[hadoop@master ~]$ ssh-keygen -t rsa
[hadoop@slave1 ~]$ ssh-keygen -t rsa
[hadoop@slave2 ~]$ ssh-keygen -t rsa
[hadoop@master ~]$ ls ~/.ssh/
id_rsa id_rsa.pub
4.将 id_rsa.pub 追加到授权 key 文件中
#master
[hadoop@master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub
#slave1
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave1 ~]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub
#slave2
[hadoop@slave2 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave2 ~]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub
5.修改文件"authorized_keys"权限
#master
[hadoop@master ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@master ~]$ ll ~/.ssh/
总用量 12
-rw-------. 1 hadoop hadoop 395 11月 14 16:18 authorized_keys
-rw-------. 1 hadoop hadoop 1679 11月 14 16:14 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11月 14 16:14 id_rsa.pub
#slave1
[hadoop@slave1 ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave1 ~]$ ll ~/.ssh/
总用量 12
-rw-------. 1 hadoop hadoop 395 11月 14 16:18 authorized_keys
-rw-------. 1 hadoop hadoop 1675 11月 14 16:14 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11月 14 16:14 id_rsa.pub
#slave2
[hadoop@slave2 ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave2 ~]$ ll ~/.ssh/
总用量 12
-rw-------. 1 hadoop hadoop 395 11月 14 16:19 authorized_keys
-rw-------. 1 hadoop hadoop 1679 11月 14 16:15 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11月 14 16:15 id_rsa.pub
6.配置 SSH 服务
#master
[hadoop@master ~]$ su - root
密码:
上一次登录:一 11月 14 15:48:10 CST 2022从 192.168.47.1pts/1 上
[root@master ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes #找到此行,并把#号注释删除。
#slave1
[hadoop@ slave1 ~]$ su - root
密码:
上一次登录:一 11月 14 15:48:10 CST 2022从 192.168.47.1pts/1 上
[root@ slave1 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes #找到此行,并把#号注释删除。
#slave2
[hadoop@ slave2 ~]$ su - root
密码:
上一次登录:一 11月 14 15:48:10 CST 2022从 192.168.47.1pts/1 上
[root@ slave2 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes #找到此行,并把#号注释删除。
7.重启 SSH 服务
[root@master ~]# systemctl restart sshd
8.切换到 hadoop 用户
[root@master ~]# su - hadoop
上一次登录:一 11月 14 16:11:14 CST 2022pts/1 上
[hadoop@master ~]$
9.验证 SSH 登录本机
[hadoop@master ~]$ ssh localhost
[hadoop@master ~]$
六.交换 SSH 密钥
1.将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
hadoop@slave1's password:
id_rsa.pub 100% 395 303.6KB/s 00:00
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
The authenticity of host 'slave2 (192.168.47.142)' can't be established.
ECDSA key fingerprint is
SHA256:KvO9HlwdCTJLStOxZWN7qrfRr8FJvcEw2hzWAF9b3bQ.
ECDSA key fingerprint is MD5:07:91:56:9e:0b:55:05:05:58:02:15:5e:68:db:be:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave2,192.168.47.142' (ECDSA) to the list of known hosts. hadoop@slave2's password:
id_rsa.pub 100% 395 131.6KB/s 00:00
2.在每个 Slave 节点把 Master 节点复制的公钥复制到authorized_keys 文件
[hadoop@slave1 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@slave2 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
3.在每个 Slave 节点删除 id_rsa.pub 文件
[hadoop@slave1 ~]$ rm -rf ~/id_rsa.pub
[hadoop@slave2 ~]$ rm -rf ~/id_rsa.pub
4.将每个 Slave 节点的公钥保存到 Master
将 Slave1 节点的公钥复制到 Master
[hadoop@slave1 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
将 Slave2 节点的公钥复制到 Master
[hadoop@slave2 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
七.验证 SSH 无密码登录
1.查看 Master 节点 authorized_keys 文件
[hadoop@master ~]$ cat ~/.ssh/authorized_keys
2.查看 Slave 节点 authorized_keys 文件
[hadoop@slave1 ~]$ cat ~/.ssh/authorized_keys
[hadoop@slave2 ~]$ cat ~/.ssh/authorized_keys
3.验证 Master 到每个 Slave 节点无密码登录
[hadoop@master ~]$ ssh slave1
Last login: Mon Nov 14 16:34:56 2022
[hadoop@slave1 ~]$
[hadoop@master ~]$ ssh slave2
Last login: Mon Nov 14 16:49:34 2022 from 192.168.47.140
[hadoop@slave2 ~]$
4.验证两个 Slave 节点到 Master 节点无密码登录
[hadoop@slave1 ~]$ ssh master
Last login: Mon Nov 14 16:30:45 2022 from ::1
[hadoop@master ~]$
[hadoop@slave2 ~]$ ssh master
Last login: Mon Nov 14 16:50:49 2022 from 192.168.47.141
[hadoop@master ~]$
5.配置两个子节点slave1、slave2的JDK环境
#master
[root@master ~]# cd /usr/local/src/
[root@master src]# ls
hadoop-2.7.1 jdk1.8.0_152
[root@master src]# scp -r jdk1.8.0_152 root@slave1:/usr/local/src/
[root@master src]# scp -r jdk1.8.0_152 root@slave2:/usr/local/src/
#slave1
[root@slave1 ~]# ls /usr/local/src/
jdk1.8.0_152
[root@slave1 ~]# vi /etc/profile
#此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
[root@slave1 ~]# source /etc/profile
[root@slave1 ~]# java -version
java version "1.8.0_152" Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
#slave2
[root@slave2 ~]# ls /usr/local/src/
jdk1.8.0_152
[root@slave2 ~]# vi /etc/profile #此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
[root@slave2 ~]# source /etc/profile、
[root@slave2 ~]# java -version
java version "1.8.0_152" Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
八.Hadoop集群运行
1.在 Master 节点上安装 Hadoop
将 hadoop-2.7.1 文件夹重命名为 Hadoop
[root@master ~]# cd /usr/local/src/
[root@master src]# mv hadoop-2.7.1 hadoop
[root@master src]# ls
hadoop jdk1.8.0_152
配置 Hadoop 环境变量
[root@master src]# yum install -y vim
[root@master src]# vim /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使配置的 Hadoop 的环境变量生效
[root@master src]# su - hadoop
上一次登录:一 2 月 28 15:55:37 CST 2022 从 192.168.41.143pts/1 上
[hadoop@master ~]$ source /etc/profile
[hadoop@master ~]$ exit
登出
执行以下命令修改 hadoop-env.sh 配置文件
[root@master src]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# vim hadoop-env.sh #修改以下配置
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
2.配置 hdfs-site.xml 文件参数
[root@master hadoop]# vim hdfs-site.xml #编辑以下内容

</configuration>
3.配置 core-site.xml 文件参数
[root@master hadoop]# vim core-site.xml #编辑以下内容
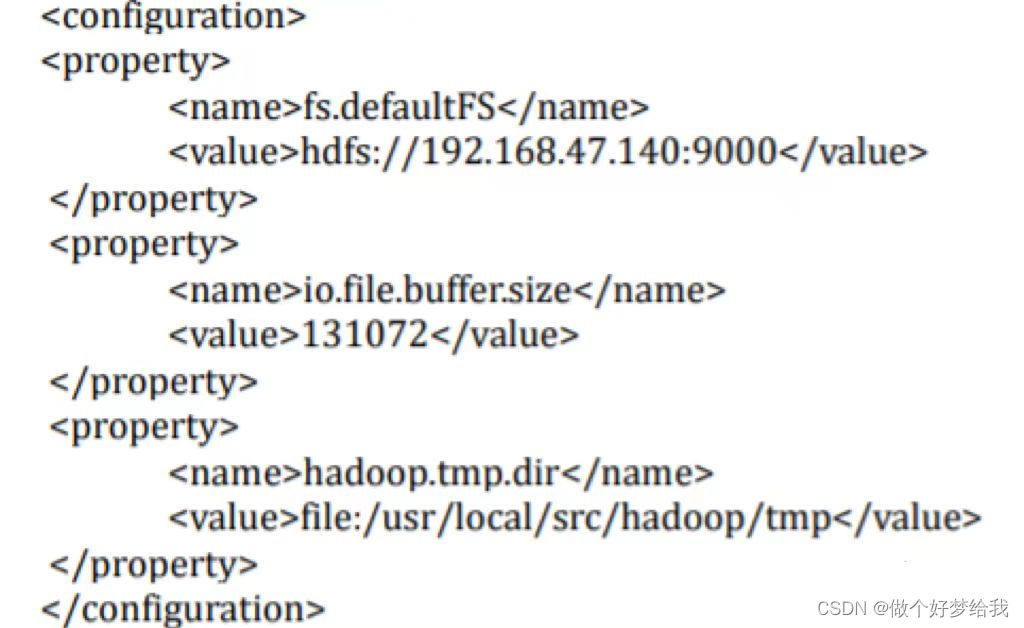
4.配置 mapred-site.xml
[root@master hadoop]# pwd
/usr/local/src/hadoop/etc/hadoop
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml #添加以下配置

5.配置 yarn-site.xml
[root@master hadoop]# vim yarn-site.xml #添加以下配置

6.Hadoop 其他相关配置
配置 masters 文件
[root@master hadoop]# vim masters
[root@master hadoop]# cat masters
192.168.47.140
配置 slaves 文件
[root@master hadoop]# vim slaves
[root@master hadoop]# cat slaves
192.168.47.141
192.168.47.142
新建目录
[root@master hadoop]# mkdir /usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/name -p
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/data -p
修改目录权限
[root@master hadoop]# chown -R hadoop:hadoop /usr/local/src/hadoop/
同步配置文件到 Slave 节点
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
#slave1
配置 [root@slave1 ~]# yum install -y vim
[root@slave1 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave1 ~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave1 ~]# su - hadoop
上一次登录:四 2 月 24 11:29:00 CST 2022 从 192.168.41.148pts/1 上
[hadoop@slave1 ~]$ source /etc/profile
#slave2
配置 [root@slave2 ~]# yum install -y vim
[root@slave2 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave2 ~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave2 ~]# su - hadoop
上一次登录:四 2 月 24 11:29:19 CST 2022 从 192.168.41.148pts/1 上
[hadoop@slave2 ~]$ source /etc/profile
九.hadoop 集群运行
1.配置 Hadoop 格式化
格化 NameNode式
[root@master ~]# su – hadoop
[hadoop@master ~]# cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format
结果:
20/05/02 16:21:50 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.1.6 ************************************************************/
启动 NameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop2.7.1/logs/hadoop-hadoop-namenode-master.out
2.查看 Java 进程
[hadoop@master hadoop]$ jps
3557 NameNode
3624 Jps
slave节点 启动 DataNode
[hadoop@slave1 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave2 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave1 hadoop]$ jps
3557 DataNode
3725 Jps
[hadoop@slave2 hadoop]$ jps
3557 DataNode
3725 Jps
启动 SecondaryNameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
[hadoop@master hadoop]$ jps
34257 NameNode
34449 SecondaryNameNode
34494 Jps
查看 HDFS 数据存放位置
[hadoop@master hadoop]$ ll dfs/
总用量 0
drwx------ 3 hadoop hadoop 21 8 月 14 15:26 data
drwxr-xr-x 3 hadoop hadoop 40 8 月 14 14:57 name
[hadoop@master hadoop]$ ll ./tmp/dfs
总用量 0
drwxrwxr-x. 3 hadoop hadoop 21 5 月 2 16:34 namesecondary
3.查看 HDFS 的报告
[hadoop@master sbin]$ hdfs dfsadmin -report
4.使用浏览器查看节点状态
在浏览器的地址栏输入http://master:50070
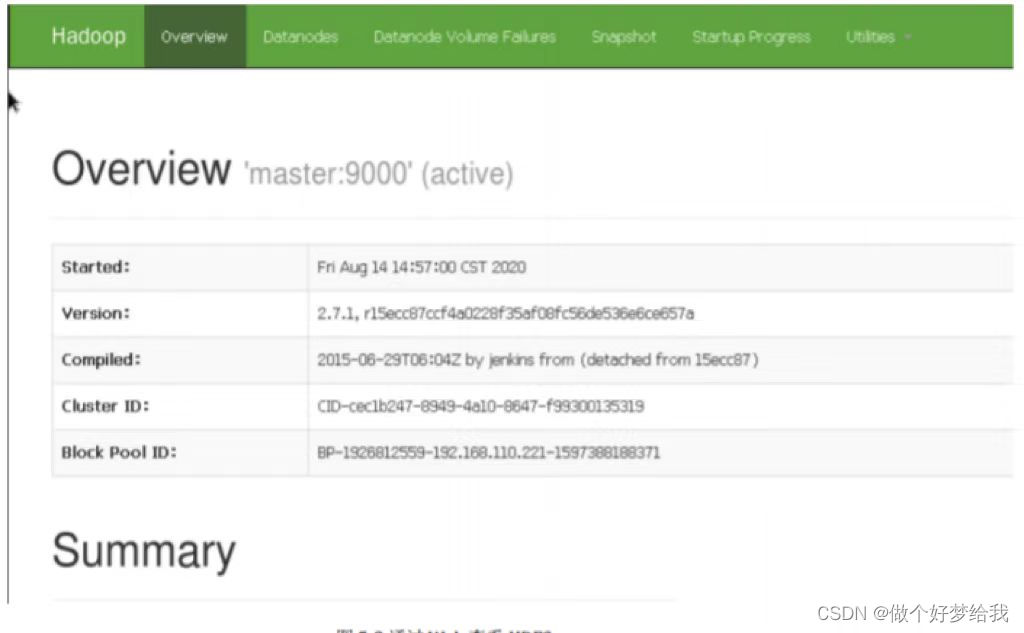
在浏览器的地址栏输入 http://master:50090
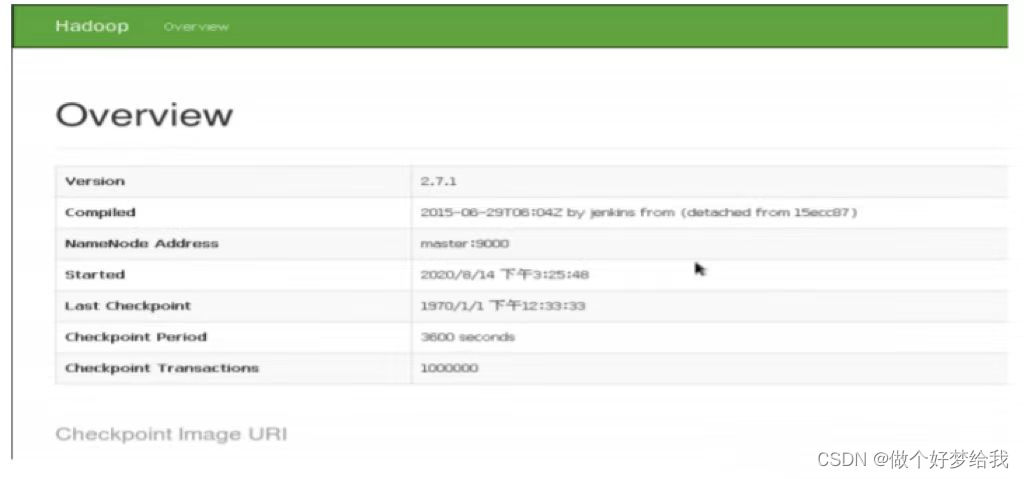
在 HDFS 文件系统中创建数据输入目录
[hadoop@master hadoop]$ start-yarn.sh
[hadoop@master hadoop]$ jps
34257 NameNode
34449 SecondaryNameNode
34494 Jps
32847 ResourceManager
[hadoop@master hadoop]$ hdfs dfs -mkdir /input
[hadoop@master hadoop]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-05-02 22:26 /input
将输入数据文件复制到 HDFS 的/input 目录中
[hadoop@master hadoop]$ cat ~/input/data.txt
Hello World
Hello Hadoop
Hello Huasan
[hadoop@master hadoop]$ hdfs dfs -put ~/input/data.txt /input
[hadoop@master hadoop]$ hdfs dfs -ls /input
运行 WordCount 案例,计算数据文件中各单词的频度
[hadoop@master hadoop]$ hdfs dfs -mkdir /output
[hadoop@master hadoop]$ hdfs dfs -ls /
[hadoop@master hadoop]$ hdfs dfs -rm -r -f /output
[hadoop@master hadoop]$ hadoop jar share/hadoop/mapreduce/hadomapreduce op-- -examples-2.7.1.jar wordcount /input/data.txt /output
在浏览器的地址栏输入:http://master:8088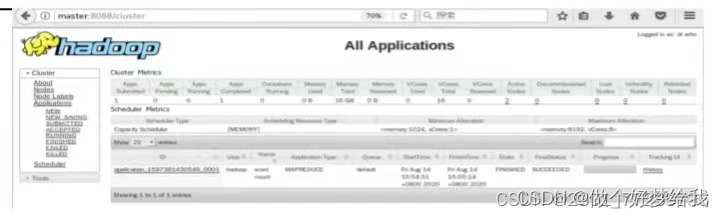
可以使用 HDFS 命令直接查看 part-r-00000 文件内容,结果如下所示:
[hadoop@master hadoop]$ hdfs dfs -cat /output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
可以看出统计结果正确,说明 Hadoop 运行正常。















 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









