






目标网站:https://www.mafengwo.cn/wenda/area-10030.html
目的:我们需要获取有关三亚旅行问答的有关数据.提取出每一个问题的评论并将数据保存在csv文件中。
分析网页数据:
我们滑动鼠标,拖拉至下方,点击 '加载更多' 的时候,发现数据会自动更新并且网页url没有发生变化,由此我们可以判断数据是通过另外一种方式加载页面数据的,我们按住fn+f12打开开发者工具,找到对应的url网址,通过抓包可以获取到我们想要的数据。
由下图可知,我们想要的数据在一个html文档中,所以我们通过抓包获取到json数据,然后利用字典来提取这个html文件。这个html文件然后通过xpath来提取数据就可以了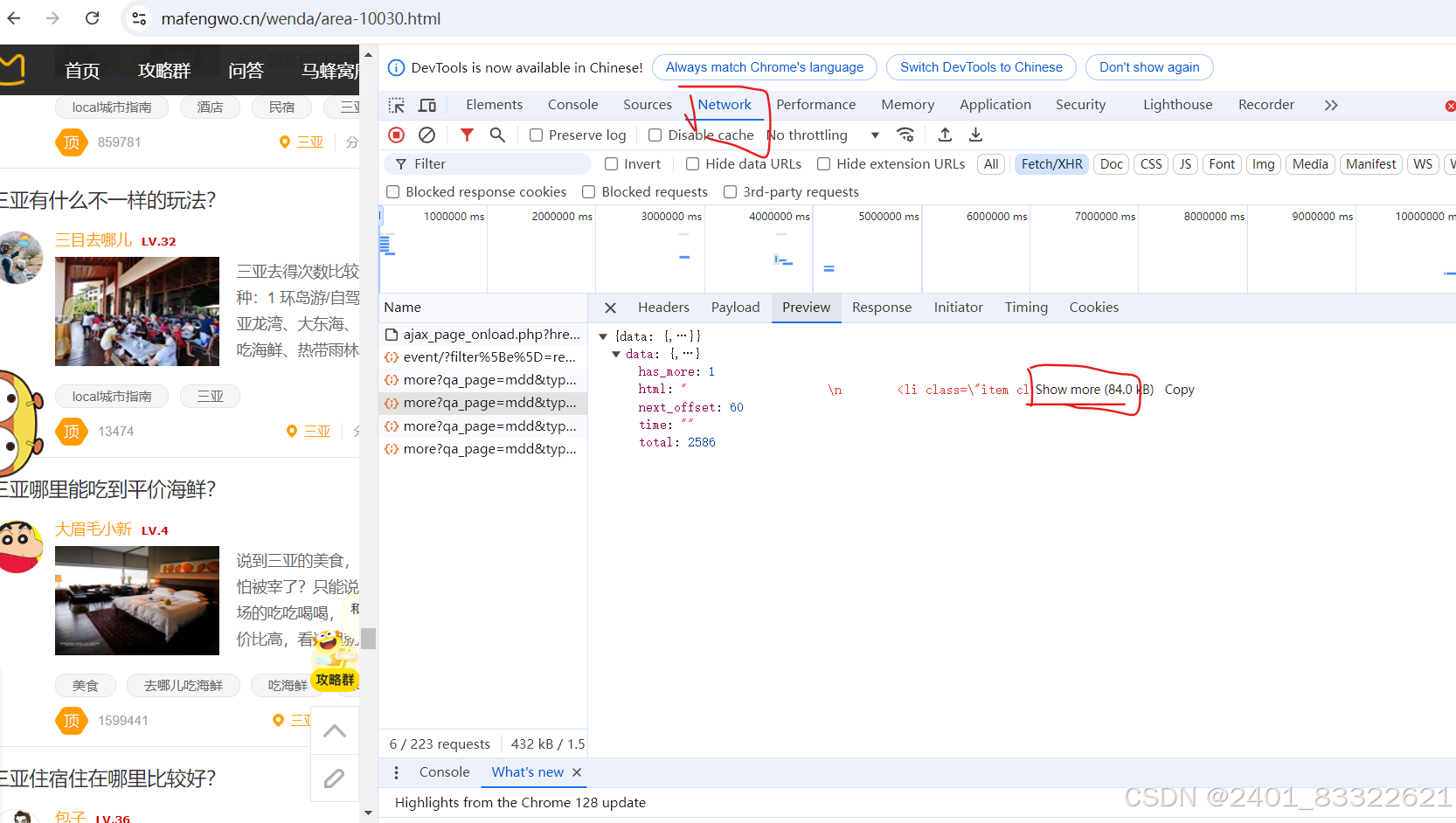
一.获取html文件:
发送请求的url: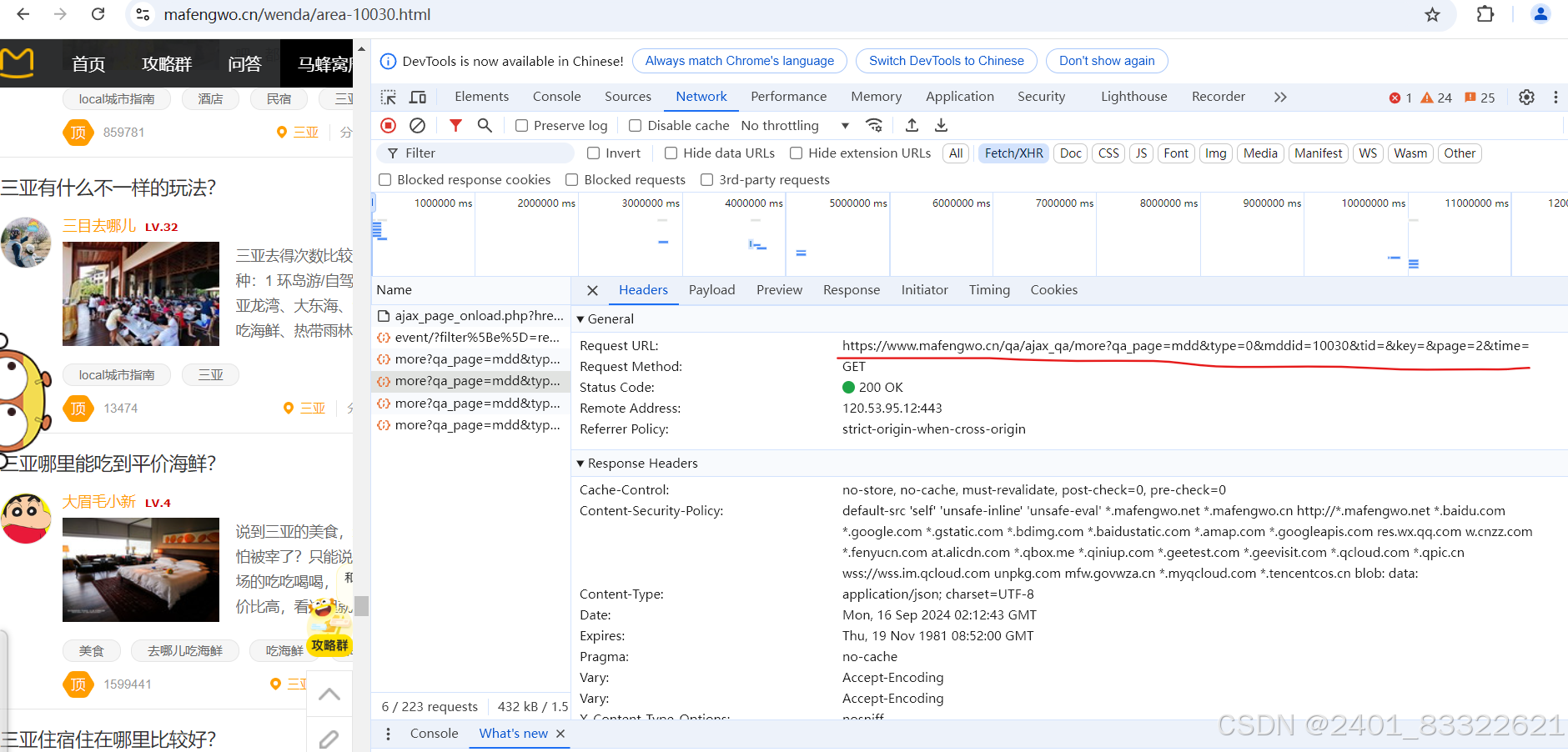
url所需参数(拼接成一个完整的url):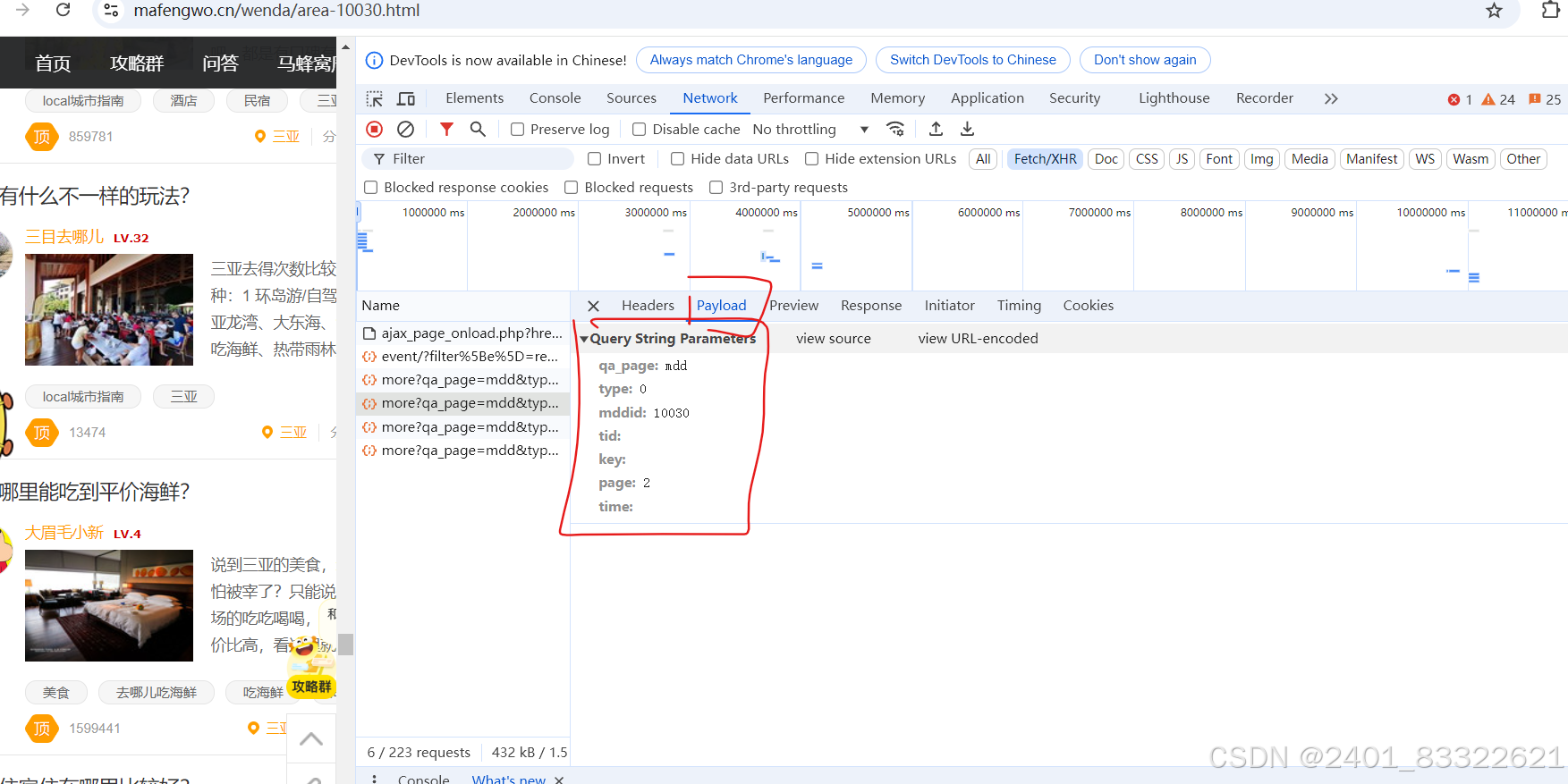
url = 'https://www.mafengwo.cn/qa/ajax_qa/more?'
#参数
paramr1={'qa_page': 'mdd',
'type': 0,
'mddid': '10030',
'tid':' ',
'key':' ',
'page': page,
'time':' '}
#添加一个请求头,处理一个反扒
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
#发生请求获取到json数据
resp1 = requests.get(url, headers=header,params=paramr1).json()
#通过字典获取到html文件
data = resp1['data']['html']
#提取的 HTML 数据保存到一个文件中
with open('马蜂窝.html', "w", encoding='utf-8-sig') as f:
f.write(data)
通过上述代码我们可以得到一个HTML文件,然后通过浏览器打开就可以看到我们需要的数据了: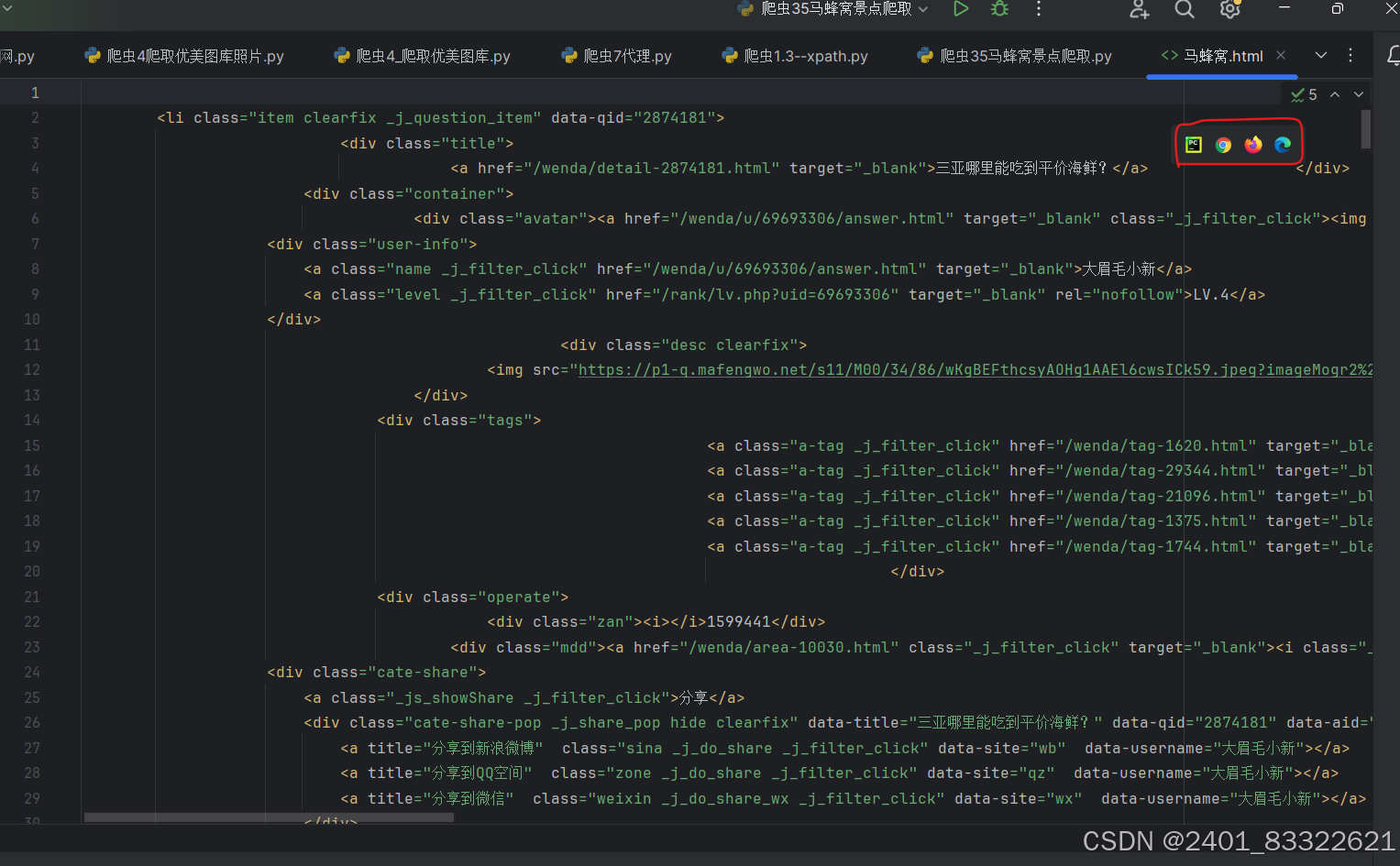
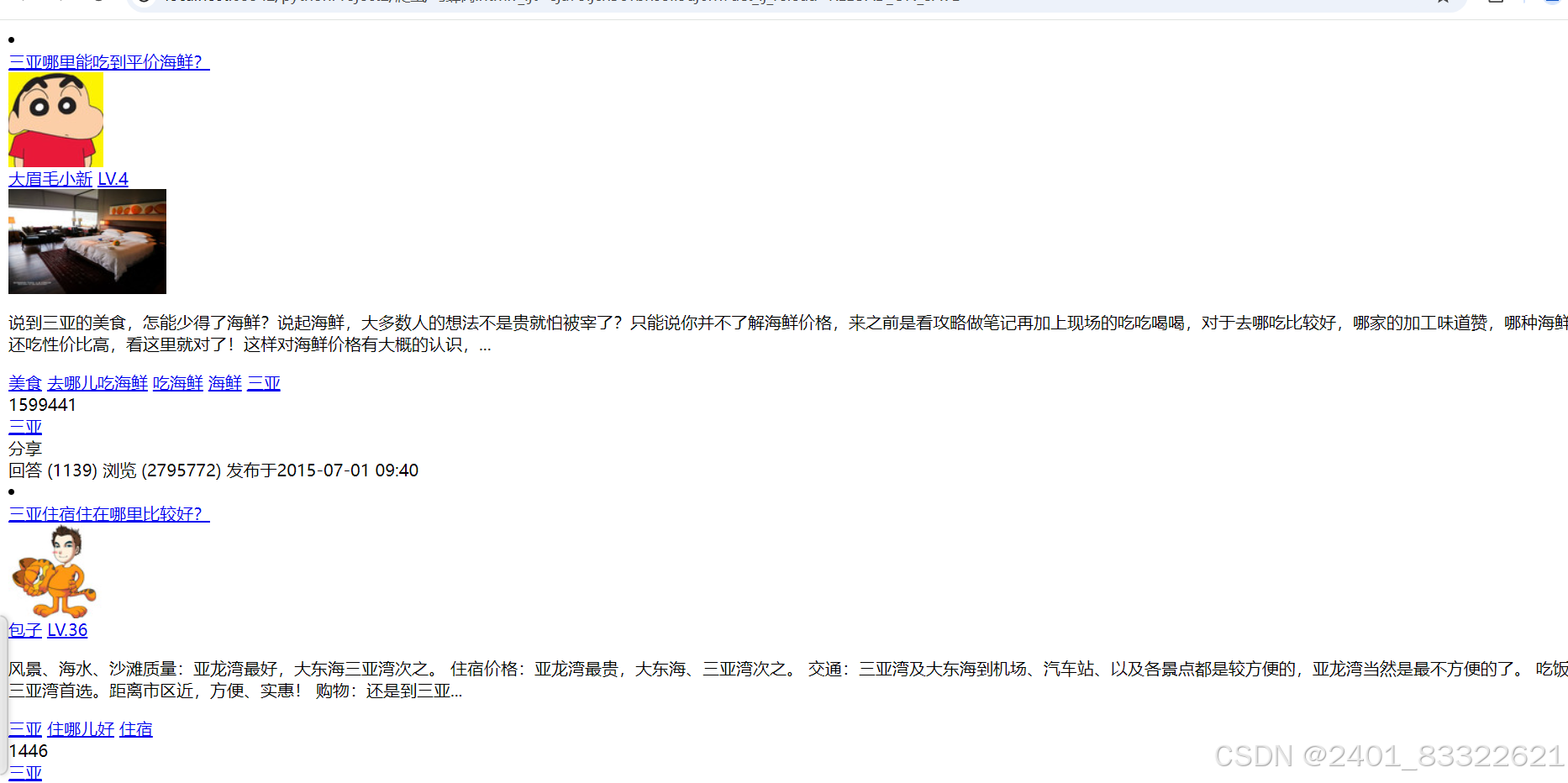
获取了html数据文件后,我们就可以通过浏览器打开,然后通过xpath来提取每一个‘问题’。
二.通过xpath提取每一个‘问题’:
url = 'https://www.mafengwo.cn/qa/ajax_qa/more?'
#参数
paramr1={'qa_page': 'mdd',
'type': 0,
'mddid': '10030',
'tid':' ',
'key':' ',
'page': page,
'time':' '}
#添加一个请求头,处理一个反扒
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
#发生请求获取到json数据
resp1 = requests.get(url, headers=header,params=paramr1).json()
#通过字典获取到html文件
data = resp1['data']['html']
#提取的 HTML 数据保存到一个文件中
with open('马蜂窝.html', "w", encoding='utf-8-sig') as f:
f.write(data)
#加载数据
data_resoure = etree.HTML(data)
#获取到每一个‘问题’
li_list = data_resoure.xpath('//body//li')
for li in li_list:
question_name = li.xpath(
'./div/a/text()')
if question_name: # 检查 Location_name 是否为空
print(question_name[0])
获得的问题如下所示:
三亚雨季怎么玩?还可以出海吗?
8月去三亚会不会很热
三亚哪里最好玩,比去景点
三亚海边画完妆的脸怎么补防晒霜?
请问三亚本地人吃什么?
三亚租房,离海边近,两室一厅,一个月多少钱
暑假三亚一个大人带小孩玩,度假游,需要租车吗?
在陵水赶海都有那些地方?你知道吗?
三亚的民宿公寓和豪华酒店应该选择谁?
去三亚旅游这六家酒店哪家性价比最高?
三亚有性价比高的潜水吗?
亚龙湾天堂公园怎么样,适合带娃游玩不?
带11岁孩子暑假三亚游,这样行程安排不知合理否?
在你们心里什么样的旅游才是不负时光?
如果用一句话证明你去过三亚,你会说啥?
6月初带父母出去旅游去云南还是三亚好呢?
三亚旅游带回来的纪念品里最想让你喜欢不舍的是啥?
游泳不太好,可以学冲浪吗?
从三亚归来,你觉得最好吃的餐厅是哪家 ?
三亚旅行中最好玩的娱乐项目求推荐!
国内海岛旅游哪里好?想去个人少点的三.提取每一个 ‘问题’ 的 ‘评论’:
通过分析这些游客的回答数据,可以得知这些数据的加载方式和前面的一样,为此我们可以使用同样的方式来获取。
url: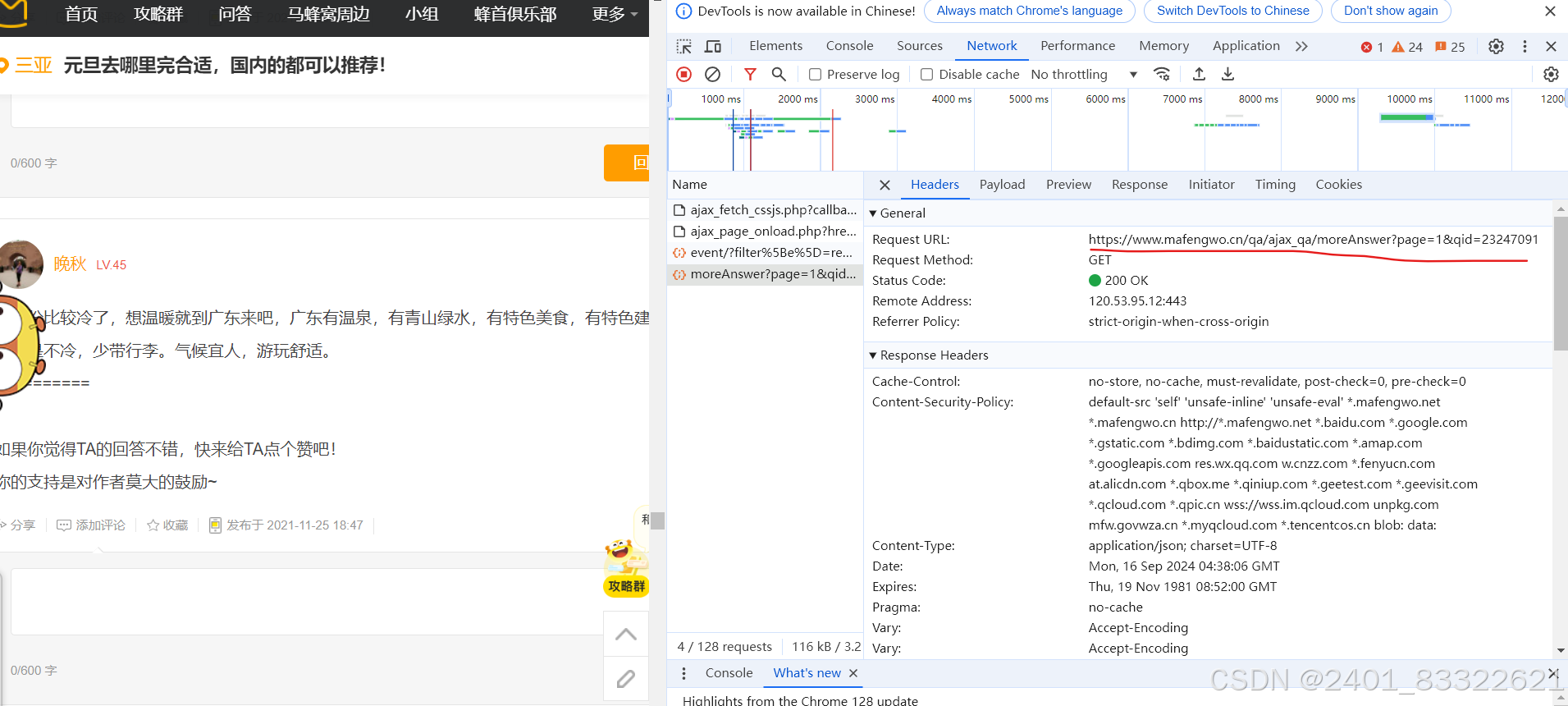
url参数: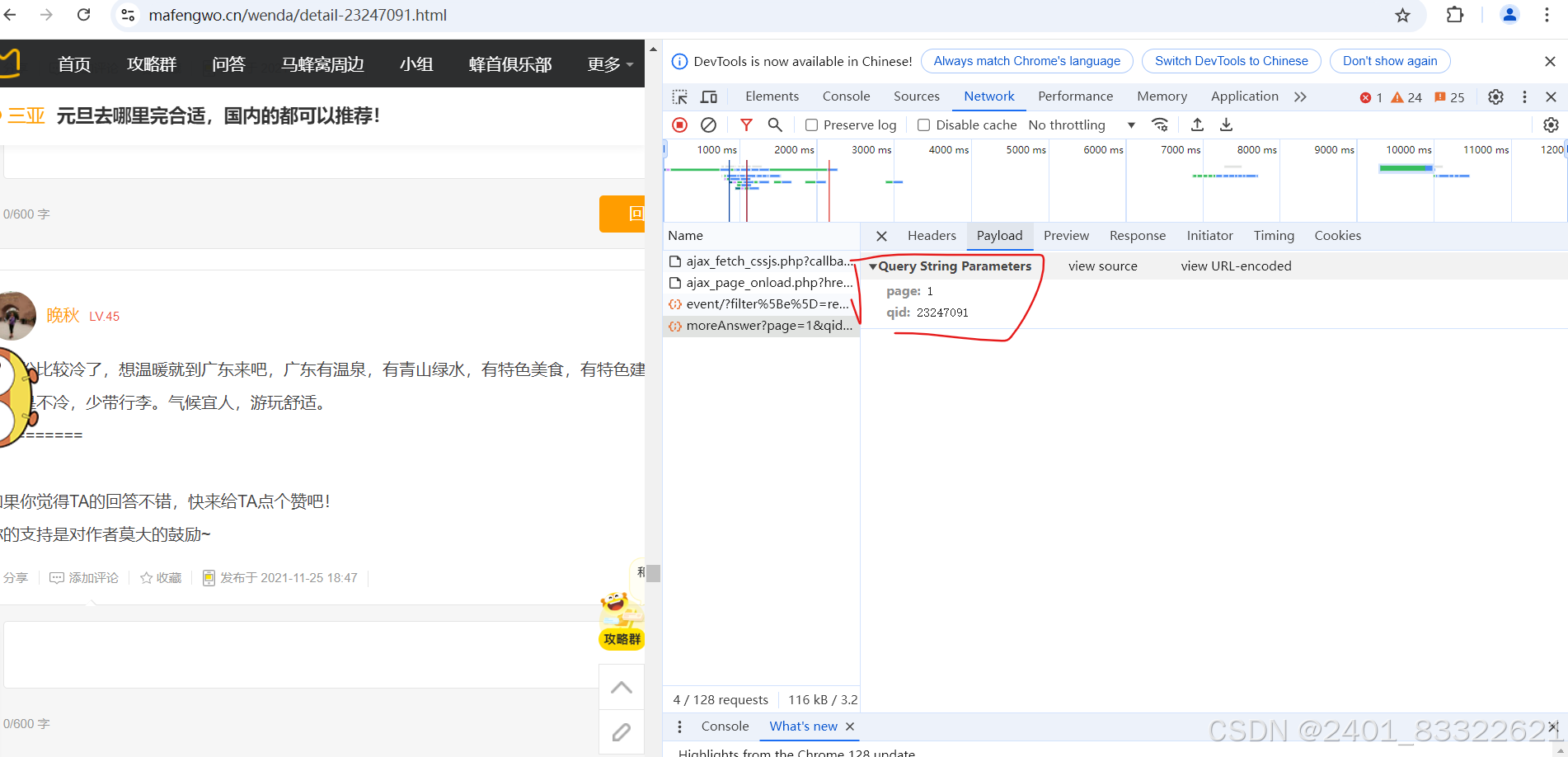
url='https://www.mafengwo.cn/qa/ajax_qa/moreAnswer?'
parmar = {'page': 1,
'qid': 23247091}
header={'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
resp=requests.get(url,headers=header,params=parmar).json()
# print(resp)
Html=resp['data']['html']
# print(Html)
if Html:#判断拿到的html是否为空
page_reoure=etree.HTML(Html)
# with open('马蜂窝当地游.htm',"w",encoding='utf-8-sig') as f:
# f.write(Html)
#//body//li//div[@class="_j_long_answer_item"]/div
li_list=page_reoure.xpath('//body//li')
# print(len(li_list))
#获取到每一个回答
for li in li_list:
react_list=li.xpath('.//div[@class="_j_long_answer_item"]/div/text()')
# print(react_list)
if len(react_list)>1:
word = react_list[0].strip()
print(f'游客对这个问题的回答是:{word}')数据:
由此我们可以看到有关 '元旦去哪里完合适,国内的都可以推荐!' 这个问题的所有评论。
游客对这个问题的回答是:来广东顺德吧,一堆的美食等着你!
游客对这个问题的回答是:只要完全消除疫情影响,又有足够的时间,国内哪里都可以。根据个人喜好、承受冷暖能力以及出行方式和条件,元旦时间还是完全能满足出行游玩需要的。
游客对这个问题的回答是:喜欢热闹的话,迪士尼吧或环球城喜欢清净的话,北方可以去大同,看看华严寺。中部的可以去绍兴,会稽山。南方的,云南大理或者海南陵水
游客对这个问题的回答是:元旦,可以选择
游客对这个问题的回答是:个人建议去一个比较热闹的城市逛逛,感受一下过节的气氛。我觉得上海,北京都是不错的选择,或者去哈尔滨也可以!
游客对这个问题的回答是:元旦时候,建议可以去南京旅行,游中山陵、玄武湖、老门东、南京长江大桥等,一定会有很多的收获。
游客对这个问题的回答是:喜欢雪景 又不怕冷,那就去北方赏雪 滑雪;偏爱文艺 习惯温暖,那就去南方
游客对这个问题的回答是:周边呗。元旦也就3天假,建议去你在的地方的周边好玩的地方。逛逛散散心~
游客对这个问题的回答是:长江以南,正常旅游,海南观海,东北赏雪,苏杭踏雪寻梅,云南品茶,福建厦门休闲,……
游客对这个问题的回答是:乌镇吧,恬静悠闲。我正在乌镇,出差😭 而且这里的防疫做的也不错
游客对这个问题的回答是:根据目前国内疫情情况,节日期间最好是待在自己所居住的城市周边活动,尽量避免到远处去旅游。
游客对这个问题的回答是:黄山、九华山、天柱山、天堂寨、万佛湖、宏村古镇、合肥渡江战役纪念馆、安徽名人馆等等
游客对这个问题的回答是:元旦假期时间不长,就去一些城市逛逛,比如成都,重庆,可打卡景点,也可放松休闲
游客对这个问题的回答是:元旦还是要看疫情的情况再考虑是否出游?图文丰富的回答更能帮助其他旅行者哦~
游客对这个问题的回答是:元旦就不要出远门了,也许去大城市,或者去南方沿海暖和点的地方~~
四.如何提取所有的 ‘问题’ 的‘评论’:
通过观察每一个 '问题' 的url可以发现通过替换page和qid这个参数就可以提取到所有的问题: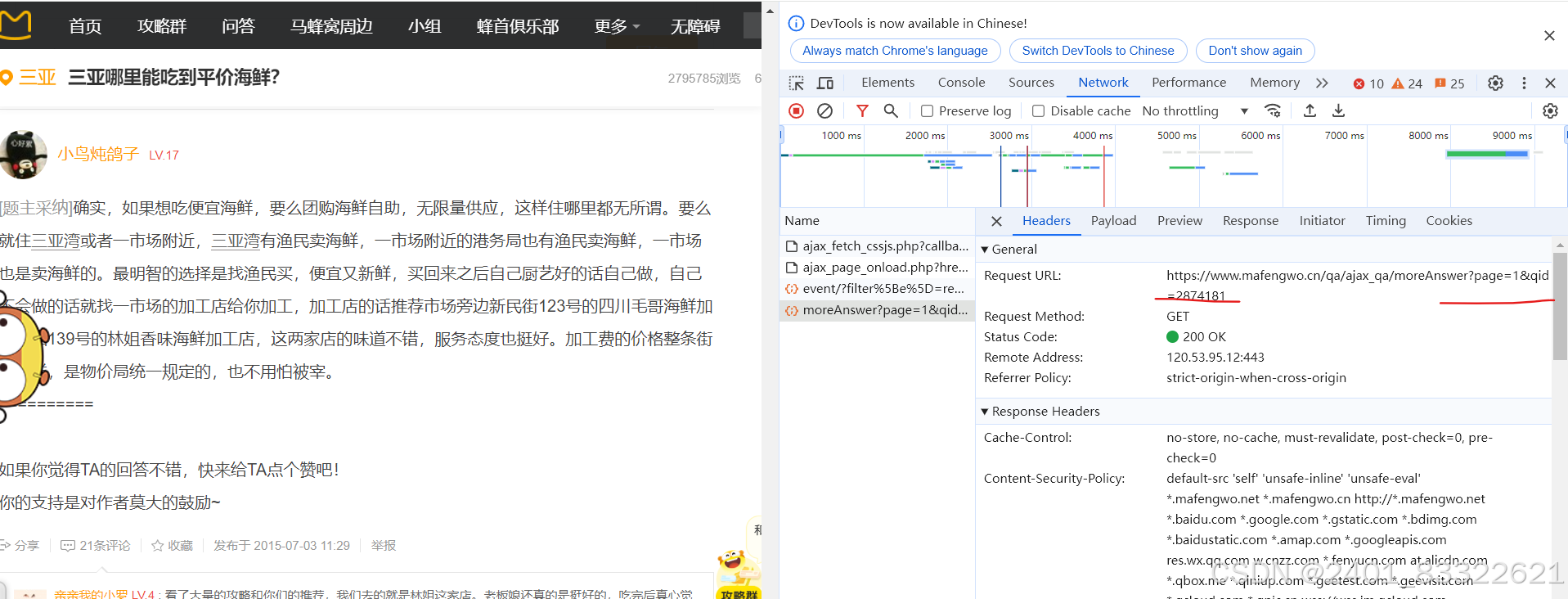
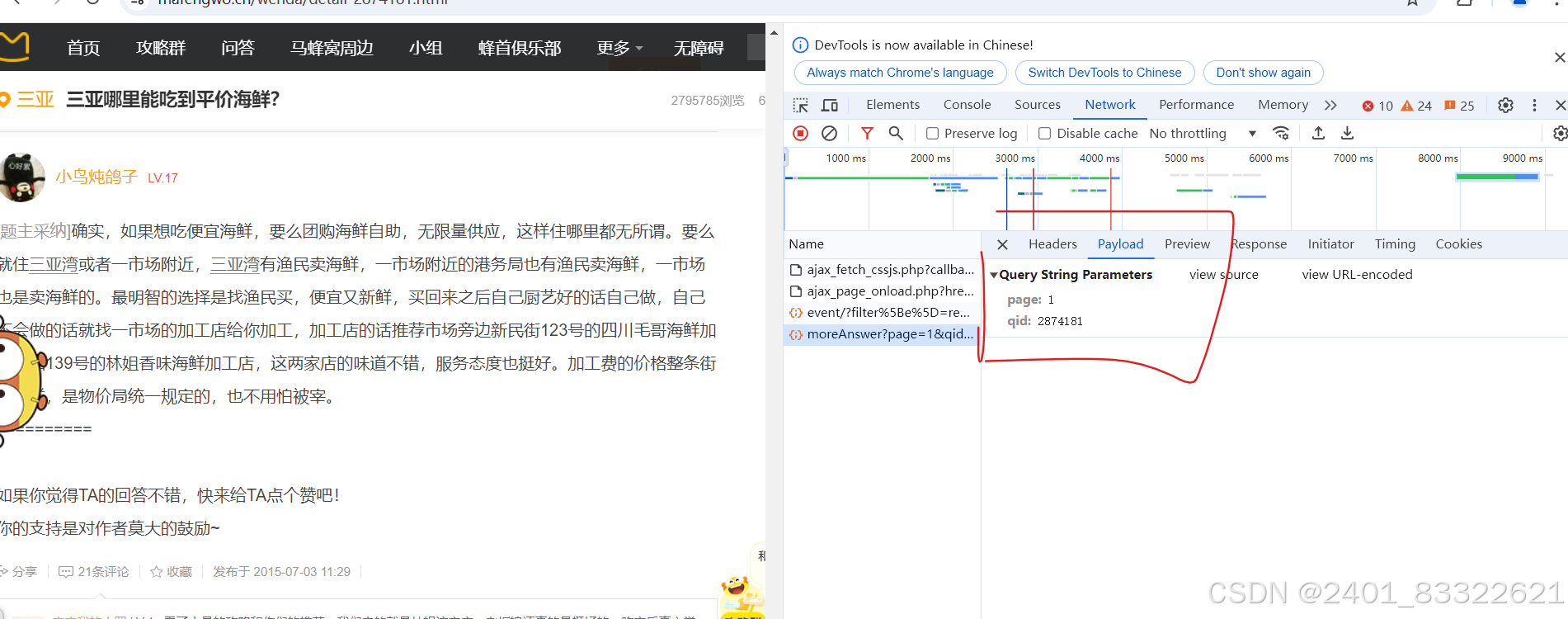
qid这个参数从哪里提取呢?
从我们通过抓包工具获取到的hmtl文件的里面,然后通过xpath来提取: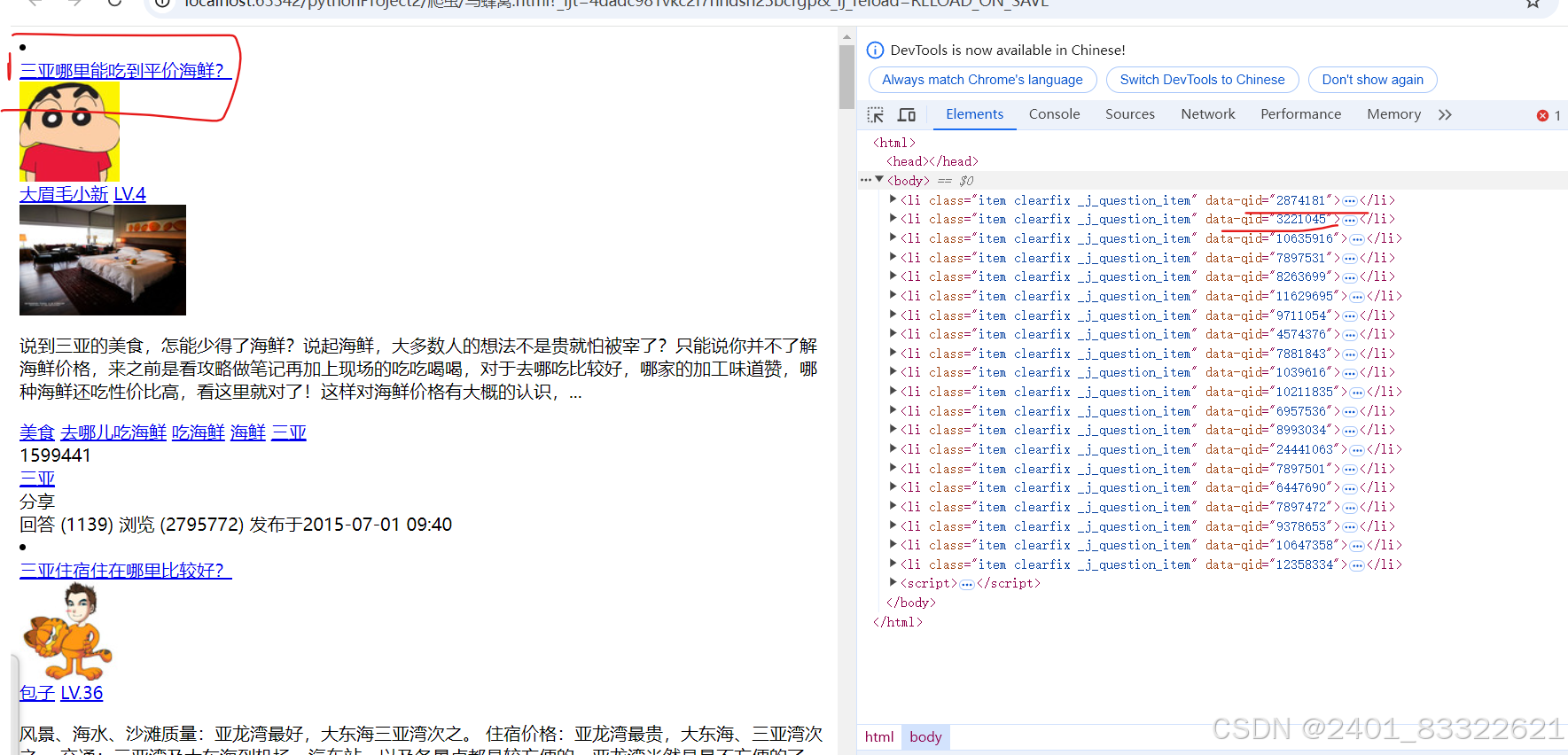
提取了id之后我们就可以替换参数了。通过这个id替换参数然后再分别发送请求到 ‘每个问题’ 的url
五.完整代码:
import requests
from lxml import etree
from time import sleep
import csv
def main():
# 打开 CSV 文件并创建写入对象
with open('马蜂窝三亚旅游问答数据.csv', mode='a', newline='', encoding='utf-8-sig') as csvfile:
csvwriter = csv.writer(csvfile)
# 如果 CSV 文件为空,写入表头
if csvfile.tell() == 0:
csvwriter.writerow(['Question', 'Answer'])
for page in range(2):
url = 'https://www.mafengwo.cn/qa/ajax_qa/more?'#‘问题’ 的url
#url的参数
paramr1 = {'qa_page': 'mdd',
'type': 0,
'mddid': '10030',
'tid': ' ',
'key': ' ',
'page': page,
'time': ' '}
#添加请求头处理反扒
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
resp1 = requests.get(url, headers=header, params=paramr1).json()
data = resp1['data']['html']
# with open('马蜂窝.html', "w", encoding='utf-8-sig') as f:
# f.write(data)
#判断从浏览器工具的 ‘preview’ 拿到的‘问题’的html是否为空
if data:
data_resoure = etree.HTML(data)
# //body//li/div/a
li_list = data_resoure.xpath('//body//li')
for li in li_list:
question_name = li.xpath(
'./div/a/text()')
if question_name: # 检查 Location_name 是否为空
print(f'游客提取的问题是:{question_name[0]}')#拿到每一个问题
# //body//li/@data-qid
# id_list = data_resoure.xpath('//body//li')
# for id in id_list:
# id = id.xpath('./@data-qid')[0]
# # print(id)
id=li.xpath('./@data-qid')[0]#拿到每一个‘问题’的id,通过这个id替换参数然后在分别发送请求到对于的url
for i in range(2):
url='https://www.mafengwo.cn/qa/ajax_qa/moreAnswer?'
parmar = {'page': i,
'qid': id}#替换参数
header={'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
resp=requests.get(url,headers=header,params=parmar).json()
# print(resp)
Html=resp['data']['html']
# print(Html)
if Html:#判断拿到的html是否为空
page_reoure=etree.HTML(Html)
# with open('马蜂窝当地游.htm',"w",encoding='utf-8-sig') as f:
# f.write(Html)
#//body//li//div[@class="_j_long_answer_item"]/div
li_list=page_reoure.xpath('//body//li')
# print(len(li_list))
for li in li_list:
react_list=li.xpath('.//div[@class="_j_long_answer_item"]/div/text()')
# print(react_list)
if len(react_list)>1:#保证提取的数据不为空
word = react_list[0].strip()
print(f'{question_name[0]}的回答是:{word}')
# 写入 CSV 文件
csvwriter.writerow([question_name[0], word])
else:
continue
else:
break
else:
break
if __name__=='__main__':
main()
然后保存到csv文件中:

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









