






目录
一.awk命令
1.工作原理:逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
- sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
Linux中最常用的文本处理工具有grep,sed,awk。行内将之称为文本三剑客,就功能量和效率来看,awk是当之无愧的文本三剑客之首
2. awk的数学计算(浮点运算)
具体使用方法,在本人前面的博客有记录: shell编程之条件语句-CSDN博客
二.awk的基础用法和选项
1.awk的基本格式及其内置变量
- awk 选项 '模式或条件 {操作}' 文件1 文件2...
- awk -f 脚本文件 文件1 文件2
- 注意一定是单引号:'模式或条件 {操作}'
- { }外指定条件,{ }内指定操作。
- 用逗号指定连续的行,用 || 指定不连续的行。&&表示”且“。
- 内建变量,不能用双引号括起来,不然系统会把它当成字符串。
| 内置变量 | 作用 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数。$NF代表最后一个字段 |
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| OFS | 输出内容的列分隔符 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是"\n" |
2. 基本打印用法
2.1 打印文章所有内容
[root@localhost ~]# awk '{print}' e.txt
ONE
TWO
THERE
FOUR
FIVE
SIX
SEVEN
EIGHT
NINE
TEN
#####
{print}表示打印每一行的内容。因此,该命令会将文件中的每一行内容打印出来。 另外:0和1放置{ }前,能够起到限制答应的作用(默认为"1")
另外:0和1放置{ }前,能够起到限制答应的作用(默认为"1")

[root@localhost ~]# awk '{print $0 }' e.txt
[root@localhost ~]# awk '{print NR,$0}' e.txt
 2.2指定行和指定行范围打印
2.2指定行和指定行范围打印
[root@localhost ~]# awk 'NR==3{print}' e.txt
THERE
[root@localhost ~]# awk 'NR==3,NR==5{print}' e.txt
THERE
FOUR
FIVE
[root@localhost ~]# awk '(NR>=3)&&(NR<=5){print}' e.txt
THERE
FOUR
FIVE
######
第一个命令:awk 'NR==3{print}' e.txt,表示只打印文件中的第三行内容。
第二个命令:awk 'NR==3,NR==5{print}' e.txt,表示打印文件中的第三行和第五行的内容。
第三个命令:awk '(NR>=3)&&(NR<=5){print}' e.txt,表示打印文件中的第三行到第五行的内容
2.3奇偶行打印
[root@localhost ~]# awk 'NR%2==0{print}' e.txt
TWO
FOUR
SIX
EIGHT
TEN
[root@localhost ~]# awk 'NR%2==1{print}' e.txt
ONE
THERE
FIVE
SEVEN
NINE
 2.4文本内容匹配过滤打印
2.4文本内容匹配过滤打印
[root@localhost ~]# awk '/^root/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# awk '/bash$/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
mwq:x:1000:1000:mwq:/home/mwq:/bin/bash
zs:x:1001:1001::/home/zs:/bin/bash
ls:x:1002:1002::/home/ls:/bin/bash
ww:x:1003:1003::/home/ww:/bin/bash
ml:x:1004:1004::/home/ml:/bin/bash
zz:x:1005:1005::/home/zz:/bin/bash
zl:x:1006:1006::/home/zl:/bin/bash
lll:x:1007:1007::/home/lll:/bin/bash
tt:x:1008:1008::/home/tt:/bin/bash
pp:x:1009:1009::/home/pp:/bin/bash
stu1:x:1010:1010::/home/stu1:/bin/bash
stu2:x:1011:1011::/home/stu2:/bin/bash
stu3:x:1012:1012::/home/stu3:/bin/bash
stu4:x:1013:1013::/home/stu4:/bin/bash
stu5:x:1014:1014::/home/stu5:/bin/bash
stu6:x:1015:1015::/home/stu6:/bin/bash
stu7:x:1016:1016::/home/stu7:/bin/bash
stu8:x:1017:1017::/home/stu8:/bin/bash
stu9:x:1018:1018::/home/stu9:/bin/bash
stu10:x:1019:1019::/home/stu10:/bin/bash
stu11:x:1020:1020::/home/stu11:/bin/bash
stu12:x:1021:1021::/home/stu12:/bin/bash
stu13:x:1022:1022::/home/stu13:/bin/bash
stu14:x:1023:1023::/home/stu14:/bin/bash
stu15:x:1024:1024::/home/stu15:/bin/bash
stu16:x:1025:1025::/home/stu16:/bin/bash
stu17:x:1026:1026::/home/stu17:/bin/bash
stu18:x:1027:1027::/home/stu18:/bin/bash
stu19:x:1028:1028::/home/stu19:/bin/bash
stu20:x:1029:1029::/home/stu20:/bin/bash
zq:x:1030:1030::/home/zq:/bin/bash
jj:x:1031:1031::/home/jj:/bin/bash

2.4 BEGIN打印模式
- 格式:awk 'BEGIN{...};{...};END{...}' 文件
处理过程:
- 1、在awk处理指定的文本之前,需要先执行BEGIN{...}模式里的命令操作
- 2、中间的{...} 是真正用于处理文件的命令操作
- 3、在awk处理完文件后才会执行END{...}模式里的命令操作。END{ }语句块中,往往会放入打印结果等语句。
引例演示:
[root@localhost]#awk 'BEGIN{x=1};{x++};END{print x}' e.txt
拓展提示:
- awk是从c语言中继承到Linux,所以在BEGIN模式中变量x,可以直接运用,无需"$"声明获取变量值

2.5 对字段进行处理打印
指定分隔符打印字段
普通指定方式:
[root@localhost ~]# head -n5 /etc/passwd |awk -F':' '{print$3}'
0
1
2
3
4
[root@localhost ~]# head -n5 /etc/passwd |awk -F':' '{print$5}'
root
bin
daemon
adm
lp

BEIGIN模式指定:
[root@localhost ~]# head -n5 /etc/passwd|awk 'BEGIN{FS=":"};{print $5}'
root
bin
daemon
adm
lp
[root@localhost ~]# head -n5 /etc/passwd|awk 'BEGIN{FS=":"};{print $3}'
0
1
2
3
4

2.6条件判断打印
[root@localhost ~]# awk -F: '$3>500{print $0}' /etc/passwd
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
libstoragemgmt:x:998:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
saned:x:996:993:SANE scanner daemon user:/usr/share/sane:/sbin/nologin
gluster:x:995:992:GlusterFS daemons:/run/gluster:/sbin/nologin
saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
unbound:x:992:987:Unbound DNS resolver:/etc/unbound:/sbin/nologin
geoclue:x:991:985:User for geoclue:/var/lib/geoclue:/sbin/nologin
sssd:x:990:984:User for sssd:/:/sbin/nologin
setroubleshoot:x:989:983::/var/lib/setroubleshoot:/sbin/nologin
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
gnome-initial-setup:x:988:982::/run/gnome-initial-setup/:/sbin/nologin
mwq:x:1000:1000:mwq:/home/mwq:/bin/bash
zs:x:1001:1001::/home/zs:/bin/bash
ls:x:1002:1002::/home/ls:/bin/bash
ww:x:1003:1003::/home/ww:/bin/bash
ml:x:1004:1004::/home/ml:/bin/bash
zz:x:1005:1005::/home/zz:/bin/bash
zl:x:1006:1006::/home/zl:/bin/bash
lll:x:1007:1007::/home/lll:/bin/bash
tt:x:1008:1008::/home/tt:/bin/bash
pp:x:1009:1009::/home/pp:/bin/bash
stu1:x:1010:1010::/home/stu1:/bin/bash
stu2:x:1011:1011::/home/stu2:/bin/bash
stu3:x:1012:1012::/home/stu3:/bin/bash
stu4:x:1013:1013::/home/stu4:/bin/bash
stu5:x:1014:1014::/home/stu5:/bin/bash
stu6:x:1015:1015::/home/stu6:/bin/bash
stu7:x:1016:1016::/home/stu7:/bin/bash
stu8:x:1017:1017::/home/stu8:/bin/bash
stu9:x:1018:1018::/home/stu9:/bin/bash
stu10:x:1019:1019::/home/stu10:/bin/bash
stu11:x:1020:1020::/home/stu11:/bin/bash
stu12:x:1021:1021::/home/stu12:/bin/bash
stu13:x:1022:1022::/home/stu13:/bin/bash
stu14:x:1023:1023::/home/stu14:/bin/bash
stu15:x:1024:1024::/home/stu15:/bin/bash
stu16:x:1025:1025::/home/stu16:/bin/bash
stu17:x:1026:1026::/home/stu17:/bin/bash
stu18:x:1027:1027::/home/stu18:/bin/bash
stu19:x:1028:1028::/home/stu19:/bin/bash
stu20:x:1029:1029::/home/stu20:/bin/bash
zq:x:1030:1030::/home/zq:/bin/bash
jj:x:1031:1031::/home/jj:/bin/bash

判断取反打印:
[root@localhost ~]# awk -F: '!($3>10){print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin

三. awk的三元表达式与精准筛选用法
3.1 awk的三元表达式
3.1.1 Java和shell的三元表达式
- java中: (条件表达式)?(A表达式或者值):(B表达式或者值)
- - 条件表达式成立(为真)时,会取冒号前面的值A。 - 条件表达式不成立(为假)时,会取冒号后面的值B。
- Shell中: [ 条件表达式 ] && A || B
- - 条件表达式成立(为真)时,会取||前面的值A。 - 条件表达式不成立(为假)时,会取||后面的值B。
3.1.2 awk的三元表达式运用
- awk的三元表达式继承了java的用法,格式与Java相似
- 格式:awk '(条件表达式)?(A表达式或者值):(B表达式或者值)'

3.2 awk的精准筛选
精准筛选方法:
| $n(> < ==) | 用于对比数值 |
| $n~"字符串" | 代表第n个字段 包含 某个字符串的作用 |
| $n!~"字符串" | 代表第n个字段 不包含 某个字符串的作用 |
| $n=="字符串" | 代表第n个字段 为 某个字符串的作用 |
| $n!="字符串" | 代表第n个字段 不为 某个字符串的作用 |
| $NF | 代表最后一个字段 |
运用1:输出第七个字段包含“bash”所在行的第一个字段和最后一个字段
[root@localhost ~]# awk -F: '$7~"bash" {print $1,$NF}' /etc/passwd
root /bin/bash
mwq /bin/bash
zs /bin/bash
ls /bin/bash
ww /bin/bash
ml /bin/bash
zz /bin/bash
zl /bin/bash
lll /bin/bash
tt /bin/bash
pp /bin/bash
stu1 /bin/bash
stu2 /bin/bash
stu3 /bin/bash
stu4 /bin/bash
stu5 /bin/bash
stu6 /bin/bash
stu7 /bin/bash
stu8 /bin/bash
stu9 /bin/bash
stu10 /bin/bash

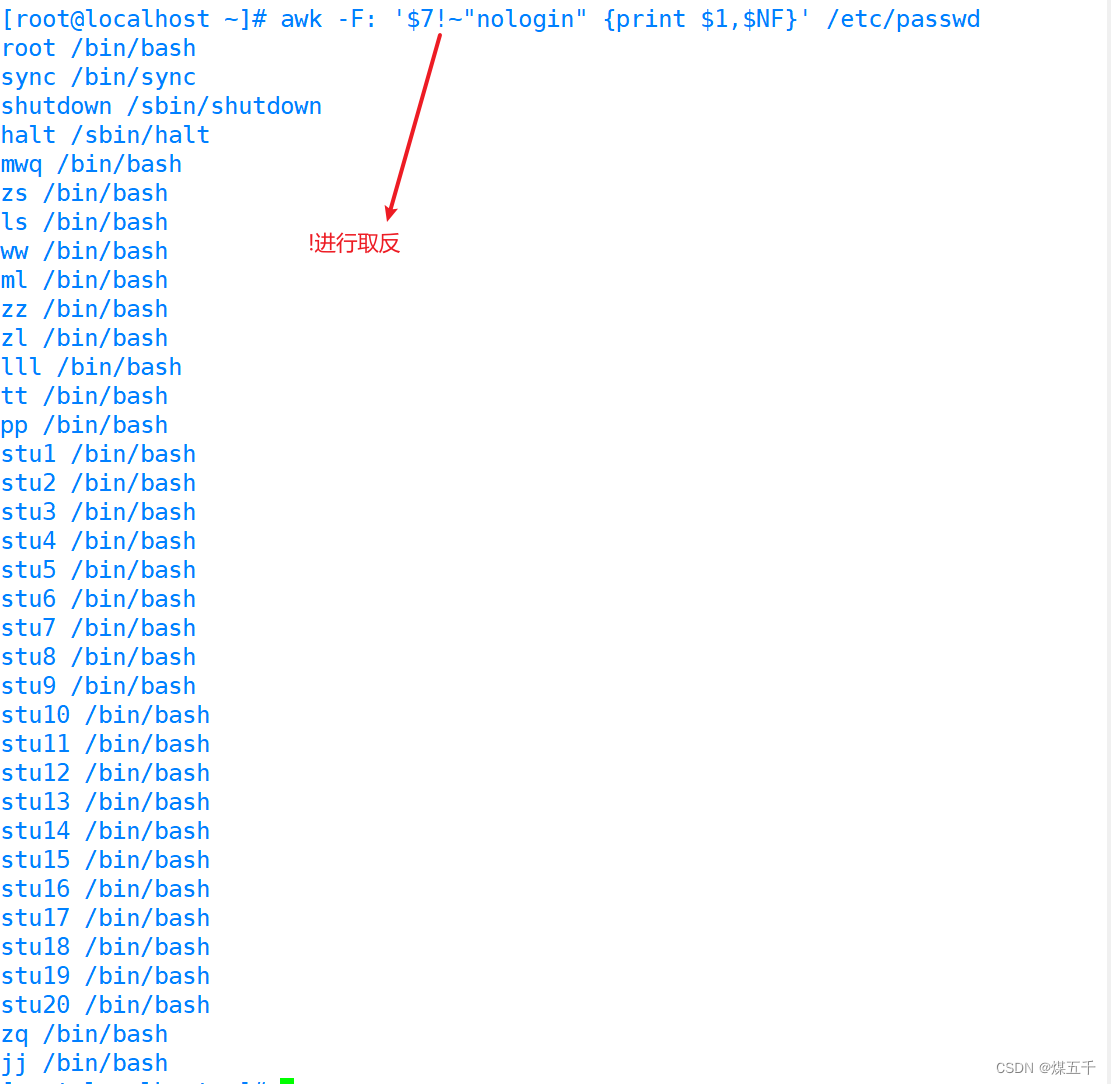
运用2:输出第七个字段不包含“nologin”所在行的第一个字段和最后一个字段
[root@localhost ~]# awk -F: '$7!~"nologin" {print $1,$NF}' /etc/passwd
root /bin/bash
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mwq /bin/bash
zs /bin/bash
ls /bin/bash
ww /bin/bash
ml /bin/bash
zz /bin/bash
zl /bin/bash
lll /bin/bash
tt /bin/bash
pp /bin/bash
stu1 /bin/bash
stu2 /bin/bash
stu3 /bin/bash
stu4 /bin/bash
stu5 /bin/bash
stu6 /bin/bash
stu7 /bin/bash
stu8 /bin/bash
stu9 /bin/bash
stu10 /bin/bash
stu11 /bin/bash
stu12 /bin/bash
stu13 /bin/bash
stu14 /bin/bash
运用3:指定第六个字段为/home/lisi ,第七个字段为/bin/bash,输出满足这些条件所在行的第一个和最后一个字段
[root@localhost ~]# awk -F: '($6=="/home/lisi")&&($7==/bin/bash)"nologin" {print $1,$NF}' /etc/passwd

四.awk的分隔符用法
4.1 RS 指定行分隔符
- awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。内置变量RS的预设值是"\n"。
- 但是也可以在使用BEGIN模式在操作前进行行分隔符的改变
[root@localhost ~]# echo $PATH|awk 'BEGIN{RS=":"};{print NR,$0}'
1 /usr/local/sbin
2 /usr/local/bin
3 /usr/sbin
4 /usr/bin
5 /root/bin

4.2 指定输出的分隔符
- FS 输入时的列分隔符。
- OFS 输出内容的列分隔符。(
$n=$n用于激活,否则不生效,n且必须存在)
对于输出时改变分隔符,我们常用到tr,awk,它们都可以实现在输出内容改变原本的分隔符
4.2.1 tr改变分隔符输出
[root@localhost ~]# echo a b c d
a b c d
[root@localhost ~]# echo a b c d|tr " " ":"
a:b:c:d

4.2.2 awk改变输出分隔符
- 直接修改输出分隔符 :
-
[root@localhost ~]# echo a b c d|awk '{OFS=":" ; $1=$1;print $0}' a:b:c:d 
BEGIN模式中修改输出分隔符:
[root@localhost ~]# echo a b c d|awk 'BEGIN{OFS=":"};{$2=$2;print $0}'
a:b:c:d
[root@localhost ~]# echo a b c d|awk 'BEGIN{OFS=":"};{$3=$3;print $0}'
a:b:c:d
[root@localhost ~]# echo a b c d|awk 'BEGIN{OFS=":"};{$4=$4;print $0}'
a:b:c:d
[root@localhost ~]# echo a b c d|awk 'BEGIN{OFS=":"};{$5=$5;print $0}'
a:b:c:d:

5. awk结合数组运用
5.1 awk中定义数组打印
[root@localhost ~]# awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[1]} '
20
[root@localhost ~]# awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[0]} '
10
[root@localhost ~]# awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[2]} '
30

5.2 awk打印文件内容去重统计
5.2.1 去重打印数组
[root@localhost ~]# arry=(10 20 10 20 30 40 10 10 20 30)
[root@localhost ~]# echo ${arry[@]}|awk -v RS=' ' '!a[$1]++'
10
20
30
40
[root@localhost ~]# awk -v RS=' ' '!a[$1]++' <<< ${arry[@]}
10
20
30
40
########
首先,定义了一个名为arry的数组,包含了10个元素:10, 20, 10, 20, 30, 40, 10, 10, 20, 30。
然后,使用echo命令输出数组的所有元素,并通过管道符(|)将输出传递给awk命令。awk命令使用了一个关联数组a,通过设置RS(Record Separator)为空格,将输入分割成单个元素。在awk命令中,!a[
1
]
+
+
表示如果元素
1]++表示如果元素1不在关联数组a中,则将其添加到数组a中,并打印出来。这样,重复的元素将被过滤掉,只保留不重复的元素。
最后,使用awk命令再次执行相同的操作,但这次直接将数组arry的元素作为输入传递给awk命令。结果同样是输出不重复的元素:10, 20, 30, 40。
5.2.2 处理文件去重统计
- 原理:将文件的字段内容变为定义的数组下标,对其进行匹配读取累加(只有遇到完全一致的才会累加),此时重复的次数在for循环的作用下成为了数组对应下标的元素,
- 所以输出该下标和元素(就等同于输出重复的字段内容 以及 统计的重复次数)
[root@localhost ~]# awk '{a[$1]++};END{for(i in a){print i,a[i]}}' lll.txt
h 1
4
sgs 1
4 2
x123213123 1
tds 1
6 1
dfh 1
24<f2> 1
3124 1
12 1
123 1
q 2
d 1
r 2
gs 1
2313 1
s 1
t 2
etw 1
g 1
#########
首先,使用awk命令读取名为lll.txt的文件。在awk命令中,{a[$1]++}表示将每行的第一个字段(即单词)作为关联数组a的键,并将其值加1。这样,每次遇到相同的单词时,其对应的值就会增加。
然后,在END块中,使用for循环遍历关联数组a的所有键。对于每个键i,打印出键i和对应的值a[i],即该单词在文本文件中出现的次数。

六. 常用awk筛选数据实例
- 下面有很多的awk获取数据都可以配合脚本加计划性任务编写为一个全自动化运维的检测脚本
6.1 获取本机上一次开机时间
[root@localhost ~]# date -d "$(awk -F. '{print $1}' /proc/uptime) second ago" +"%Y%m%d %H:%M:%S"
20240522 09:34:30
#######
首先,使用awk命令读取/proc/uptime文件的第一列(即系统运行的总秒数),并将其作为参数传递给date命令。-F.表示将输入按照点号进行分割,{print $1}表示输出第一列。
然后,使用date命令将这个总秒数转换为日期和时间格式。+%Y%m%d %H:%M:%S表示输出格式为年月日时分秒。
6.2 获取本机IP地址
[root@localhost ~]# ifconfig ens33|awk '/inet /{print $2}'
20.0.0.168

6.3 检测本机cpu 15分钟内的平均负载
[root@localhost ~]# uptime|awk '{print $NF}'
0.05

总结
- 1. awk是一种对文件输出内容的字段(列),进行操作的工具,多数用来提取重要数据
- 2. awk 结合数组时可以进行数组定义,数组遍历,以及数组元素的去重统计
- 3.提取文件数据时,注意每行或列的分隔符,正确借用分隔符能够使提取的数据更加精确
















 3140
3140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











