






在driver中修改代码
package com.root.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
// 省略其他.....
System.exit(result ? 0 : 1);
}
}
其他的Mapper和Reducer代码保持不变。
运行之后,发现输出的结果格式没有变化,因为它是中间过程。
压缩实操案例2-Reduce输出端采用压缩
基于WordCount案例,只需要在dirvier类的代码中,去设置在reduce端输出压缩开启,并设置压缩的方式即可。
对应的代码有如下两行,其他的代码不动。
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
// FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
其他的Mapper和Reducer代码保持不变。
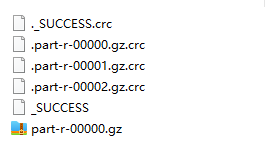
运行代码之后,是否在输出结果中看到了压缩的格式。

















 2264
2264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









